

Predicting seizure outcome after epilepsy surgery: Do we need more complex models, larger samples, or better data?
- PMID: 37129087
- PMCID: PMC10952307
- DOI: 10.1111/epi.17637
Predicting seizure outcome after epilepsy surgery: Do we need more complex models, larger samples, or better data?
Abstract
Objective: The accurate prediction of seizure freedom after epilepsy surgery remains challenging. We investigated if (1) training more complex models, (2) recruiting larger sample sizes, or (3) using data-driven selection of clinical predictors would improve our ability to predict postoperative seizure outcome using clinical features. We also conducted the first substantial external validation of a machine learning model trained to predict postoperative seizure outcome.
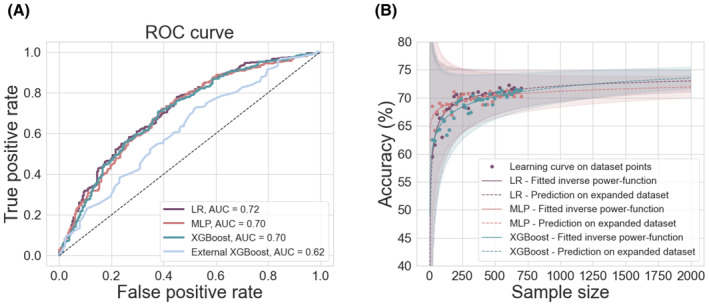
Methods: We performed a retrospective cohort study of 797 children who had undergone resective or disconnective epilepsy surgery at a tertiary center. We extracted patient information from medical records and trained three models-a logistic regression, a multilayer perceptron, and an XGBoost model-to predict 1-year postoperative seizure outcome on our data set. We evaluated the performance of a recently published XGBoost model on the same patients. We further investigated the impact of sample size on model performance, using learning curve analysis to estimate performance at samples up to N = 2000. Finally, we examined the impact of predictor selection on model performance.
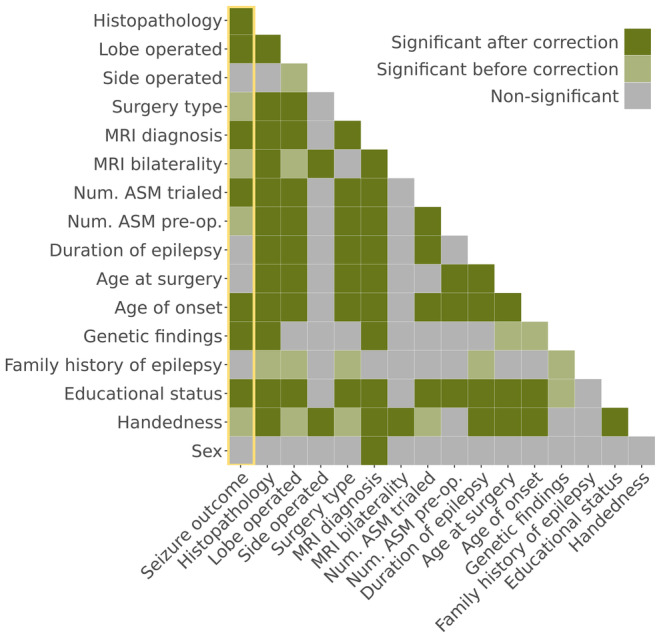
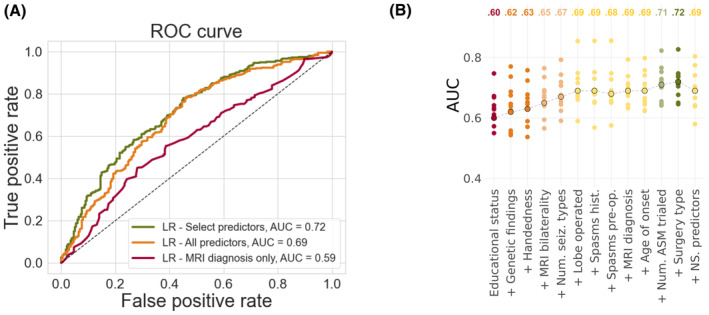
Results: Our logistic regression achieved an accuracy of 72% (95% confidence interval [CI] = 68%-75%, area under the curve [AUC] = .72), whereas our multilayer perceptron and XGBoost both achieved accuracies of 71% (95% CIMLP = 67%-74%, AUCMLP = .70; 95% CIXGBoost own = 68%-75%, AUCXGBoost own = .70). There was no significant difference in performance between our three models (all p > .4) and they all performed better than the external XGBoost, which achieved an accuracy of 63% (95% CI = 59%-67%, AUC = .62; pLR = .005, pMLP = .01, pXGBoost own = .01) on our data. All models showed improved performance with increasing sample size, but limited improvements beyond our current sample. The best model performance was achieved with data-driven feature selection.
Significance: We show that neither the deployment of complex machine learning models nor the assembly of thousands of patients alone is likely to generate significant improvements in our ability to predict postoperative seizure freedom. We instead propose that improved feature selection alongside collaboration, data standardization, and model sharing is required to advance the field.
Keywords: epilepsy surgery; machine learning; pediatric; prediction.
© 2023 The Authors. Epilepsia published by Wiley Periodicals LLC on behalf of International League Against Epilepsy.
Conflict of interest statement
JHC has acted as an investigator for studies with GW Pharmaceuticals, Zogenix, Vitaflo, Ovid, Marinius, and Stoke Therapeutics. She has been a speaker and on advisory boards for GW Pharmaceuticals, Zogenix, Biocodex, Stoke Therapeutics, and Nutricia; all remuneration has been paid to her department. She is president of the International League Against Epilepsy (2021–2025), and chair of the medical boards for Dravet UK, Hope 4 Hypothalamic Hamartoma, and Matthew's friends. MT has received grants from Royal Academy of Engineers and LifeArc. He has received honoraria from Medtronic. LM has received personal consultancy fees from Mendelian Ltd, outside the submitted work. AM has received honoraria from Biocodex and Nutricia, and provided consultancy to Biogen, outside the submitted work. All other authors report no disclosures relevant to the manuscript.
Figures
Comment in
-
Back to the Basics in Predictive Modeling-Predicting Surgical Success.Epilepsy Curr. 2023 Nov 6;24(1):19-21. doi: 10.1177/15357597231205437. eCollection 2024 Jan-Feb. Epilepsy Curr. 2023. PMID: 38327535 Free PMC article.
