

Genetic architecture of the inflammatory bowel diseases across East Asian and European ancestries
- PMID: 37156999
- PMCID: PMC10290755
- DOI: 10.1038/s41588-023-01384-0
Genetic architecture of the inflammatory bowel diseases across East Asian and European ancestries
Abstract
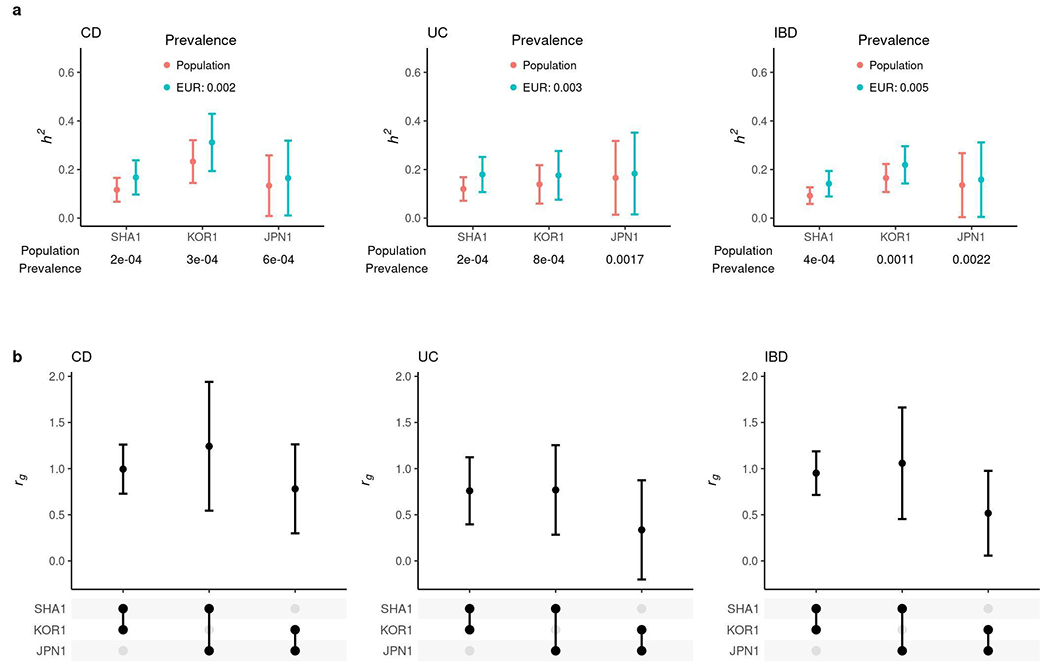
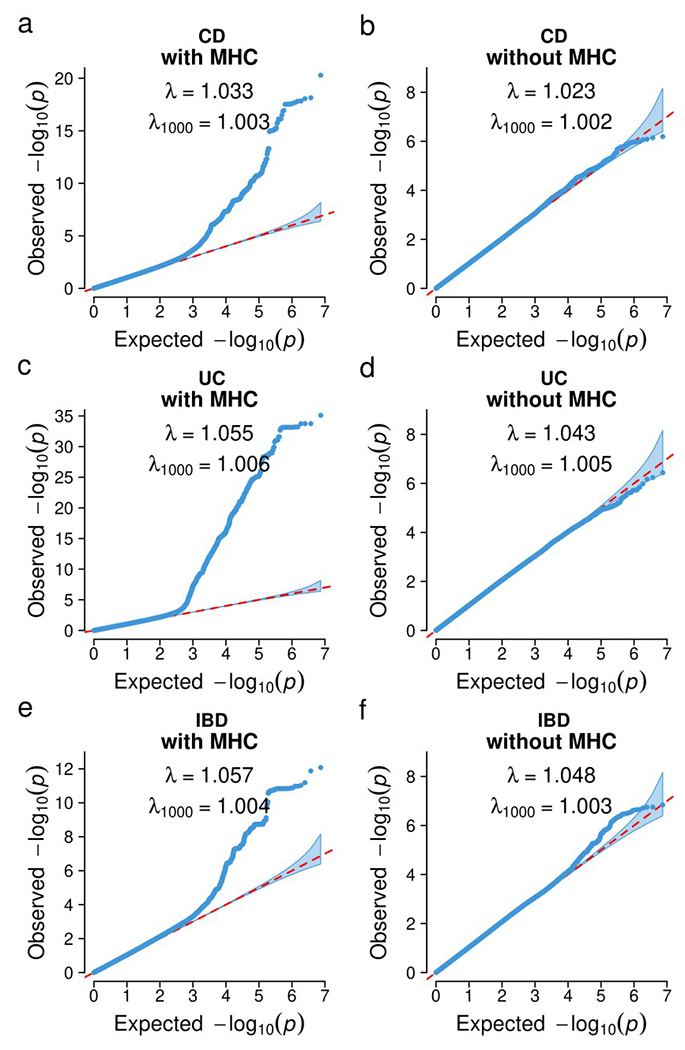
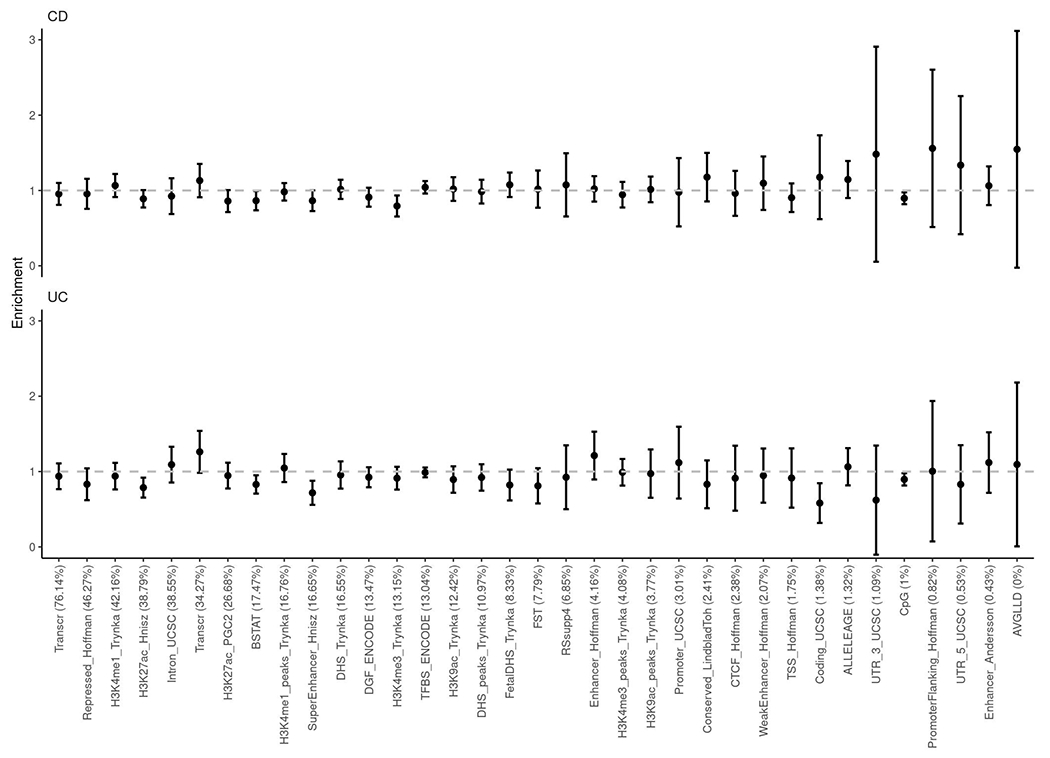
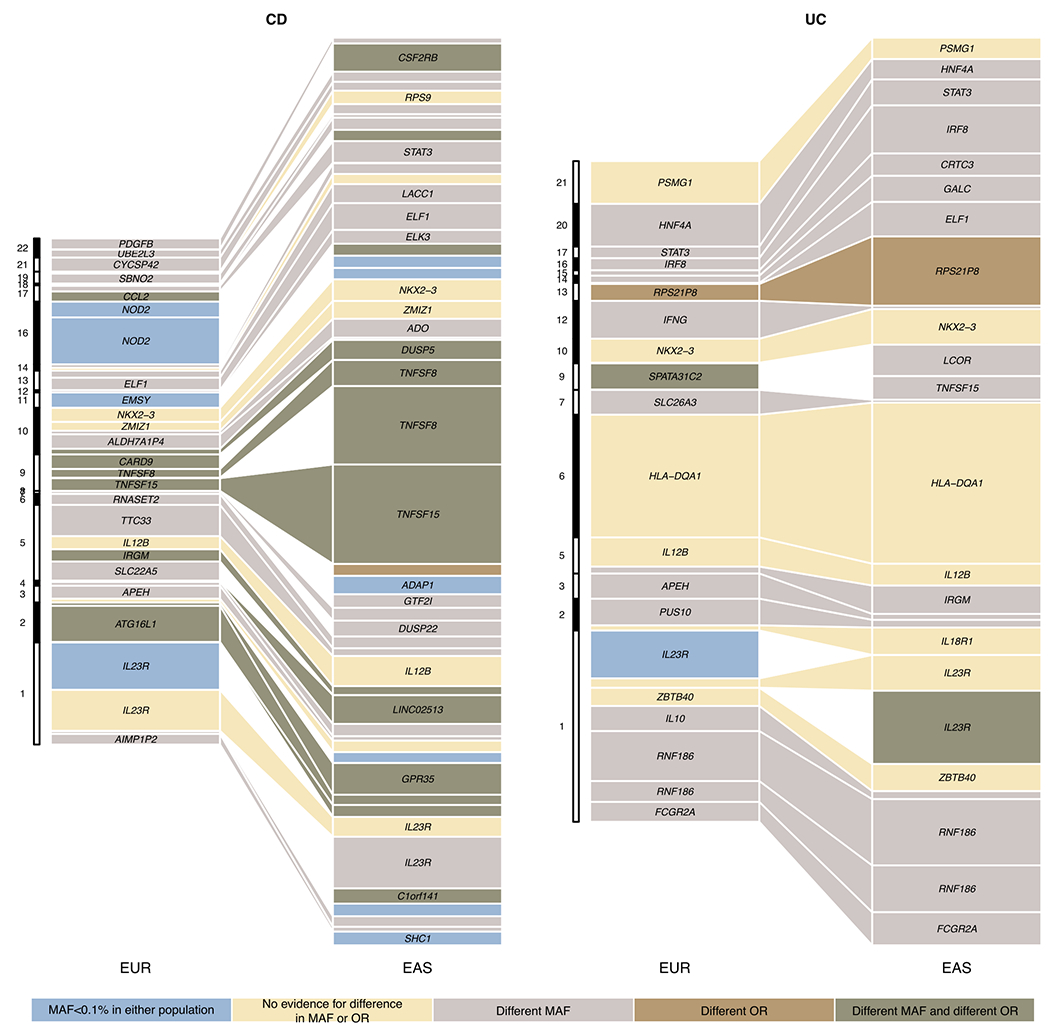
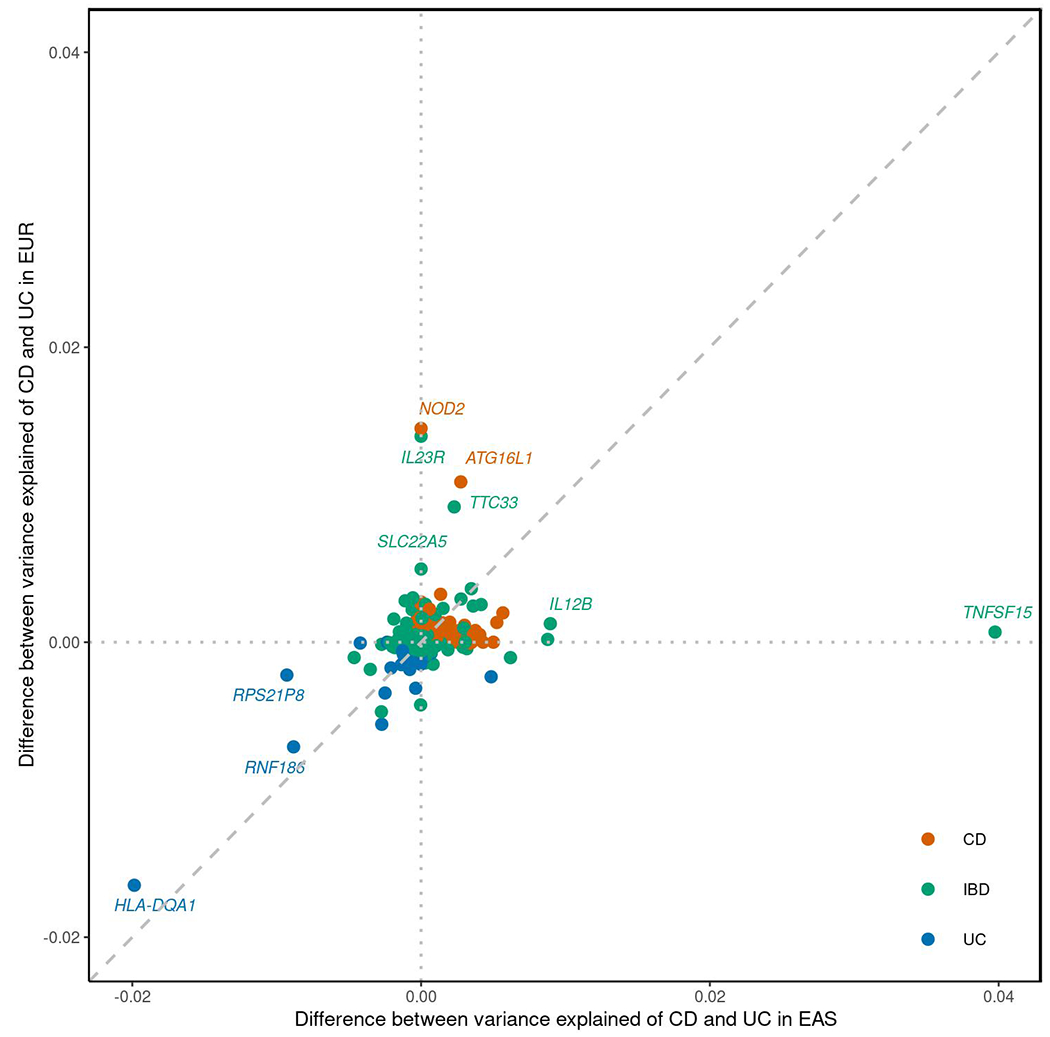
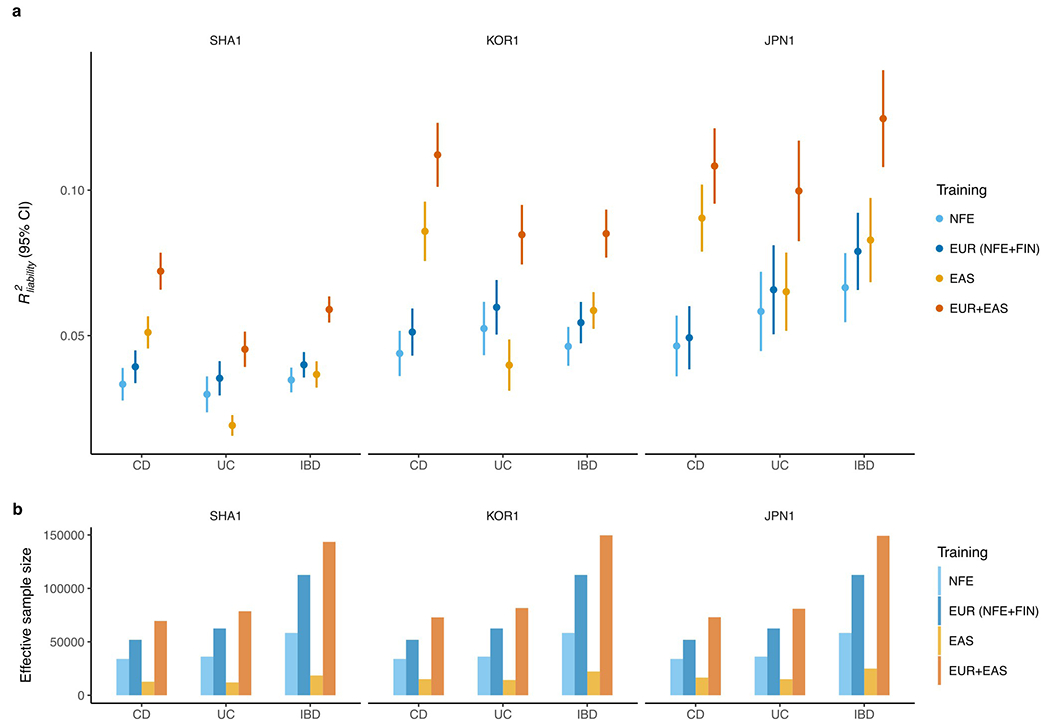
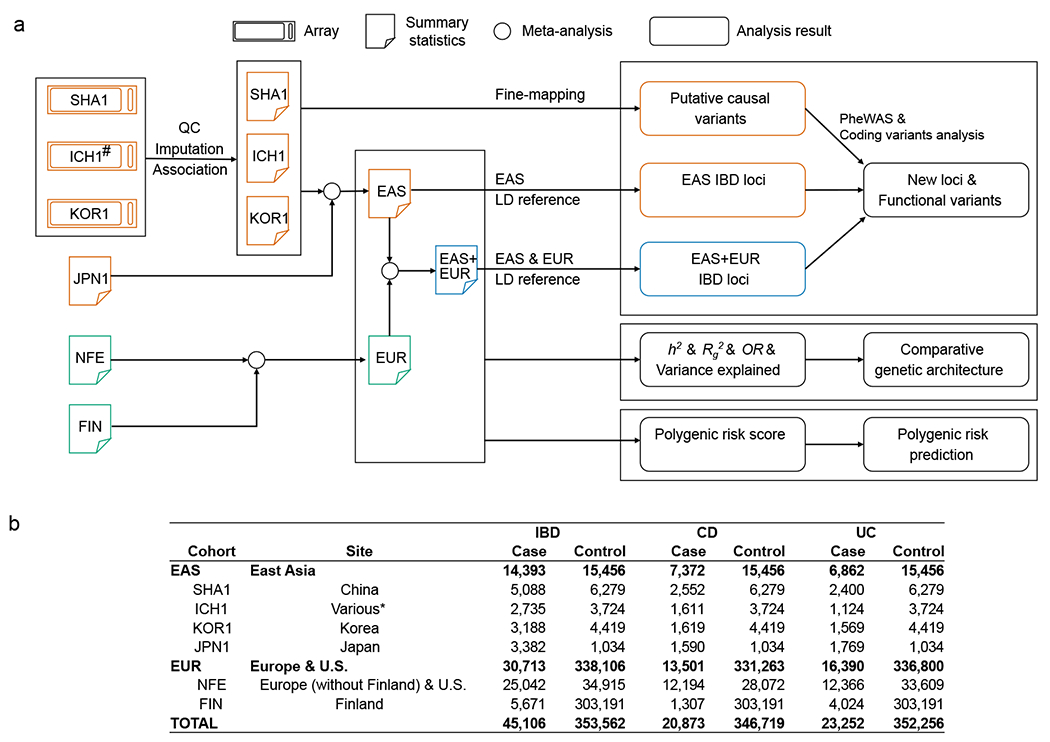
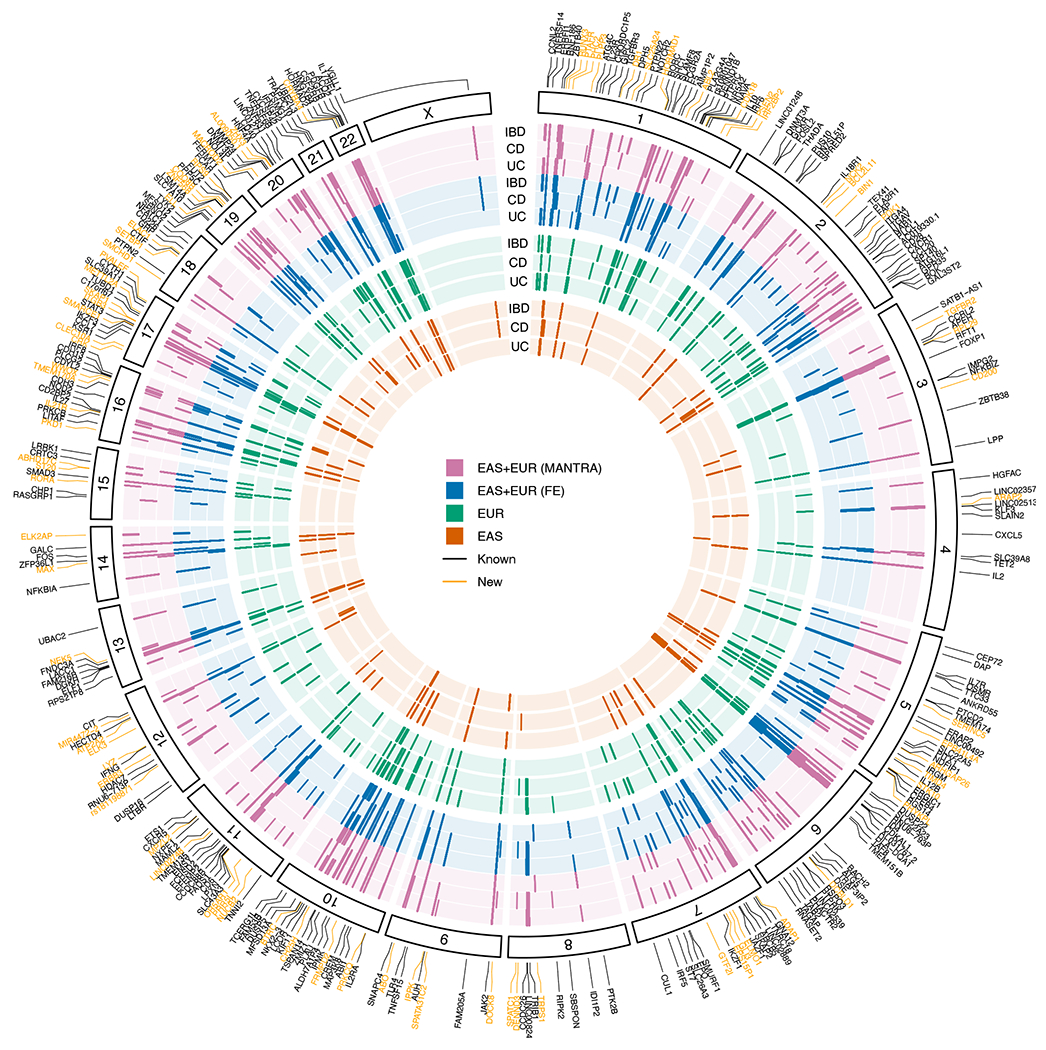
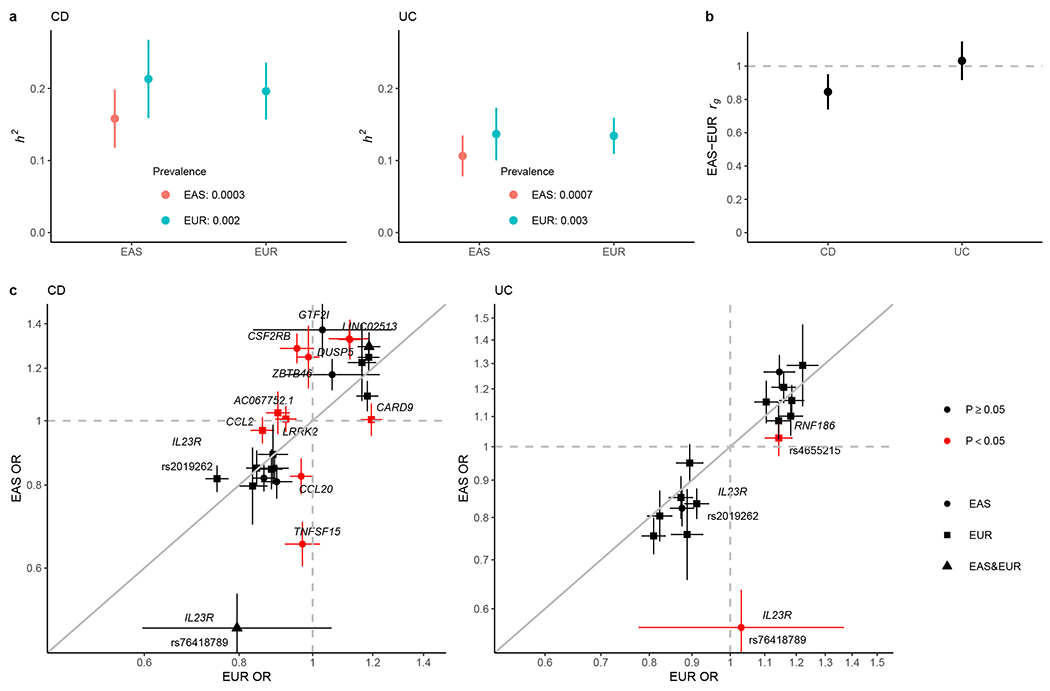
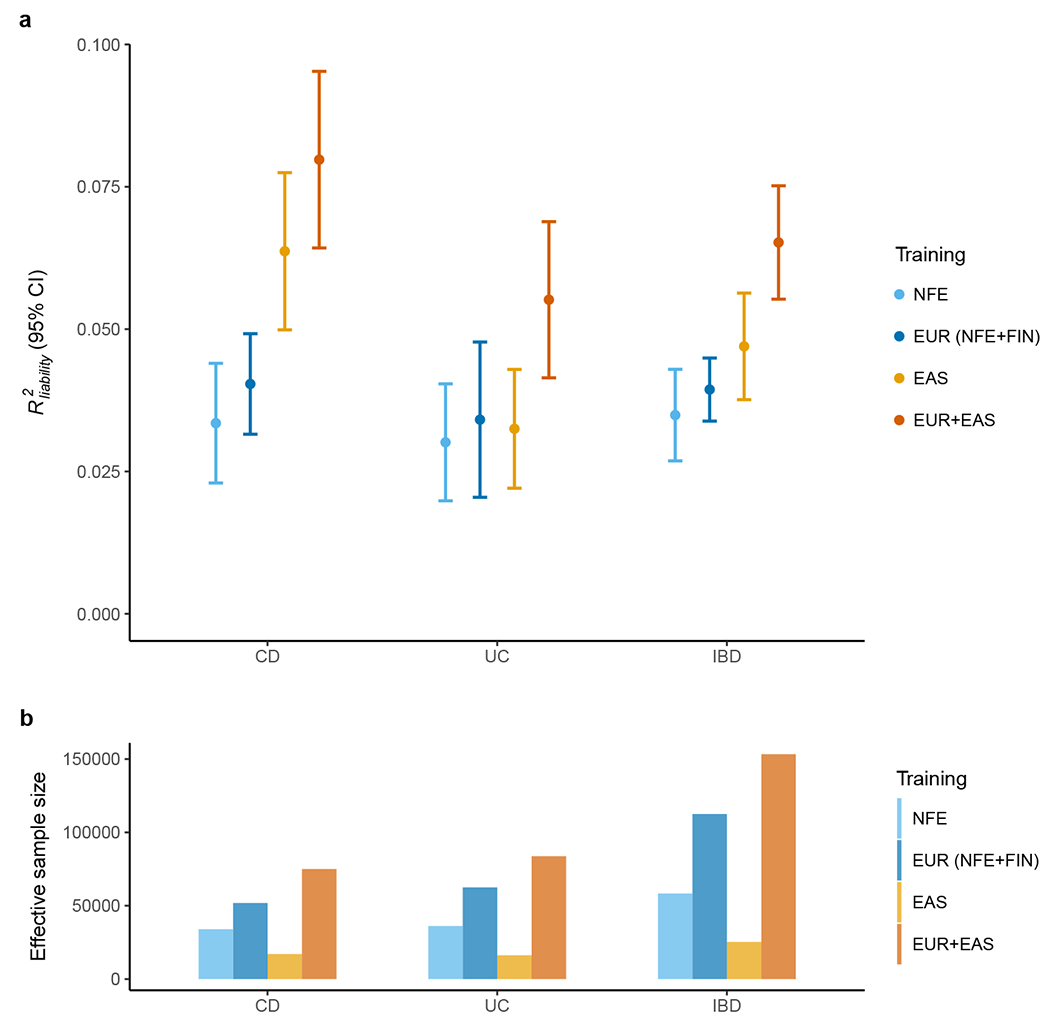
Inflammatory bowel diseases (IBDs) are chronic disorders of the gastrointestinal tract with the following two subtypes: Crohn's disease (CD) and ulcerative colitis (UC). To date, most IBD genetic associations were derived from individuals of European (EUR) ancestries. Here we report the largest IBD study of individuals of East Asian (EAS) ancestries, including 14,393 cases and 15,456 controls. We found 80 IBD loci in EAS alone and 320 when meta-analyzed with ~370,000 EUR individuals (~30,000 cases), among which 81 are new. EAS-enriched coding variants implicate many new IBD genes, including ADAP1 and GIT2. Although IBD genetic effects are generally consistent across ancestries, genetics underlying CD appears more ancestry dependent than UC, driven by allele frequency (NOD2) and effect (TNFSF15). We extended the IBD polygenic risk score (PRS) by incorporating both ancestries, greatly improving its accuracy and highlighting the importance of diversity for the equitable deployment of PRS.
© 2023. The Author(s), under exclusive licence to Springer Nature America, Inc.
Conflict of interest statement
COMPETING INTERESTS
W.S. and C.S. are employees of Digital Health China Technologies Corp. Ltd.. M.J.D. is a founder of Maze Therapeutics. D.P.B.M. has received consultancy fees from Prometheus Biosciences, Prometheus Laboratories, Takeda, Gilead, Pfizer. Stock - Prometheus Biosciences. B.D.Y. has served on advisory boards for AbbVie Korea, Celltrion, Daewoong Pharma, Ferring Korea, Janssen Korea, Pfizer Korea, and Takeda Korea; has received research grants from Celltrion and Pfizer Korea; has received consulting fees from Chong Kun Dang Pharm., CJ Red BIO, Cornerstones Health, Daewoong Pharma, IQVIA, Kangstem Biotech, Korea United Pharm. Inc., Medtronic Korea, NanoEntek, and Takeda; and has received speaking fees from AbbVie Korea, Celltrion, Ferring Korea, IQVIA, Janssen Korea, Pfizer Korea, Takeda, and Takeda Korea. H.H. received consultancy fees from Ono Pharmaceutical and honorarium from Xian Janssen Pharmaceutical. The remaining authors declare no competing interests.
Figures
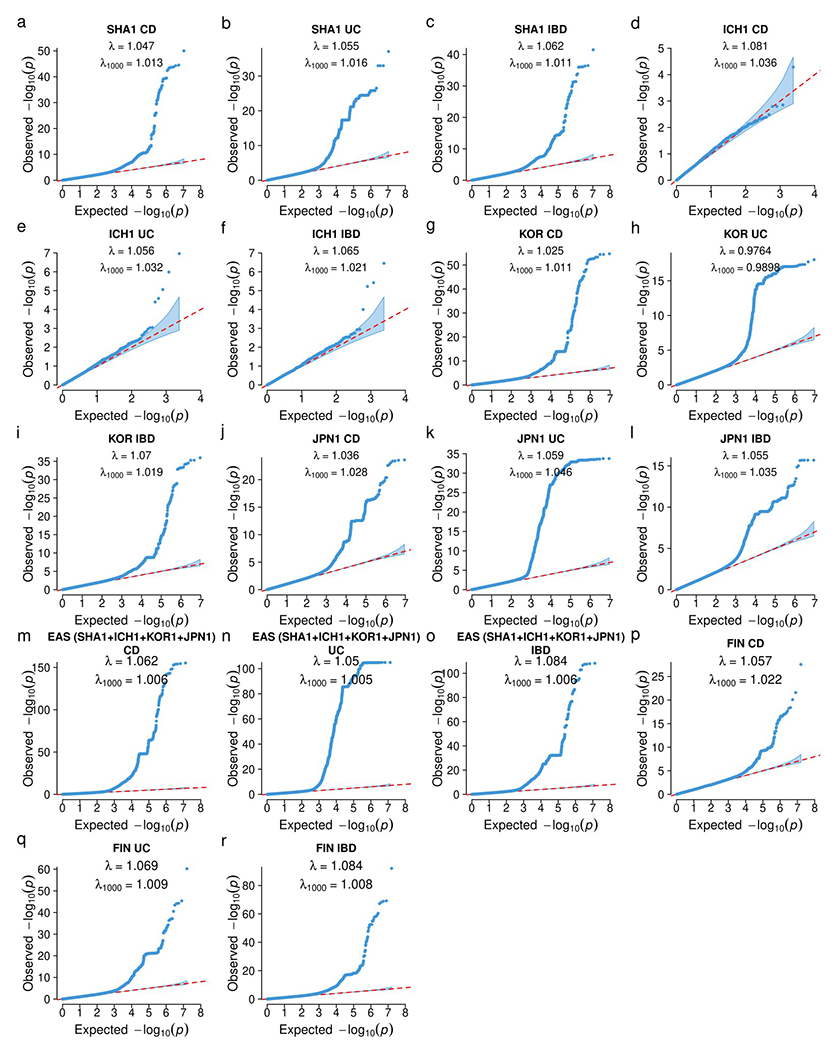
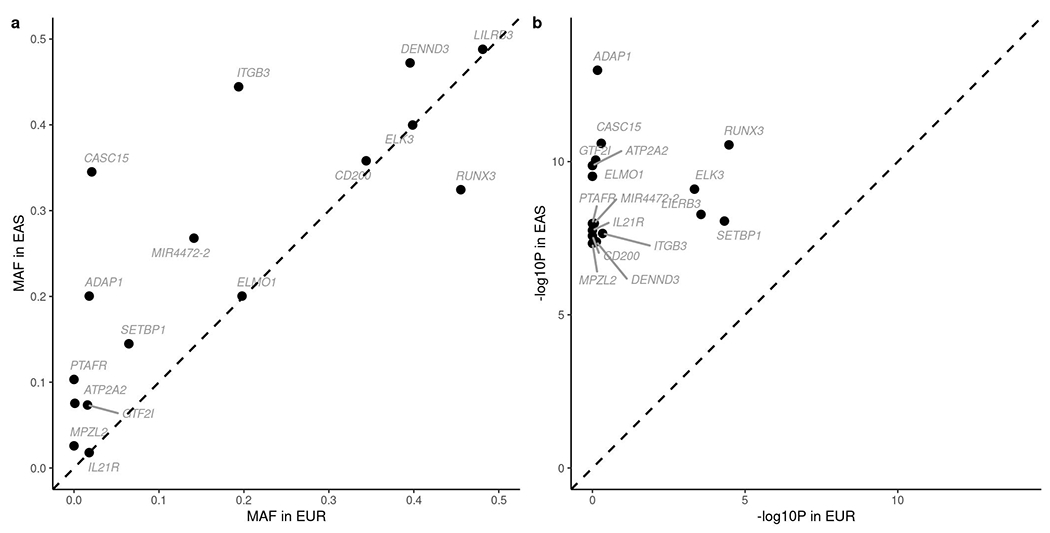
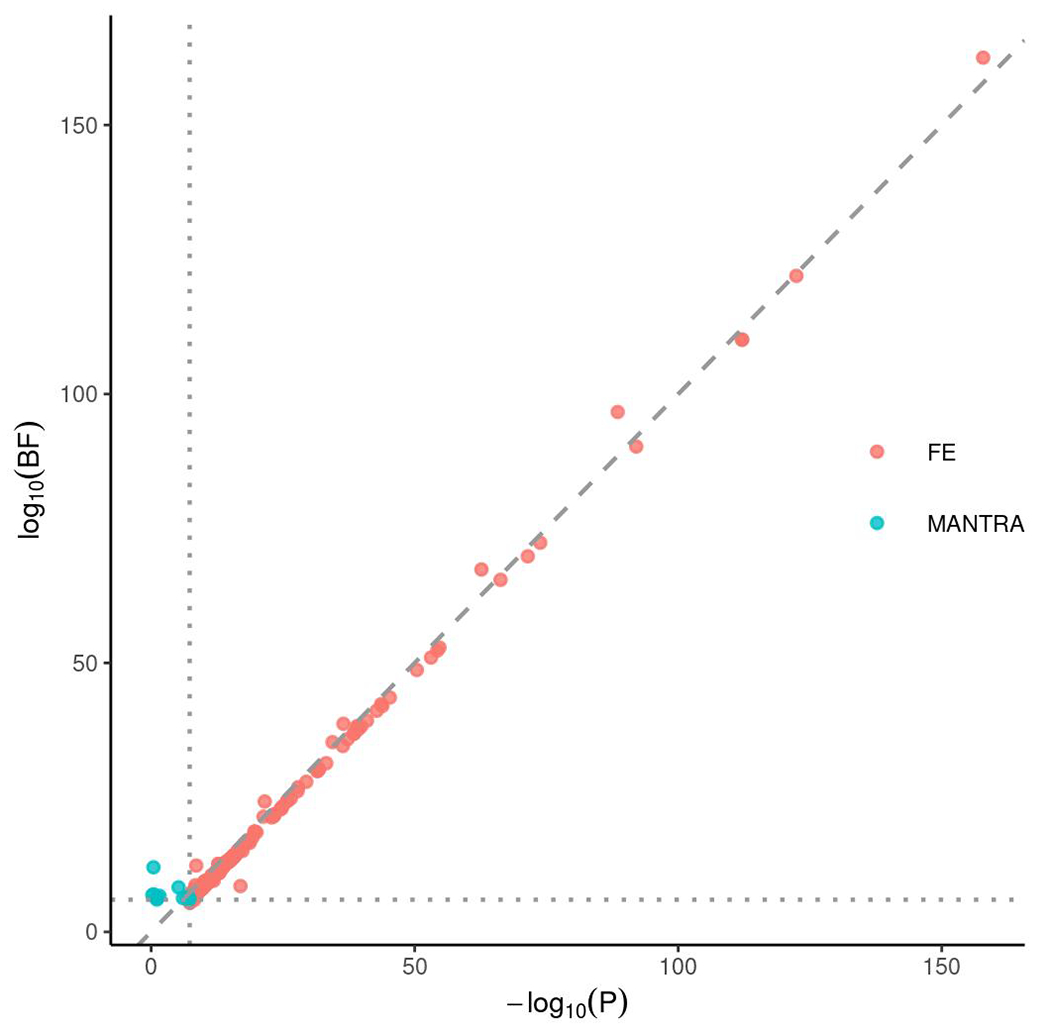
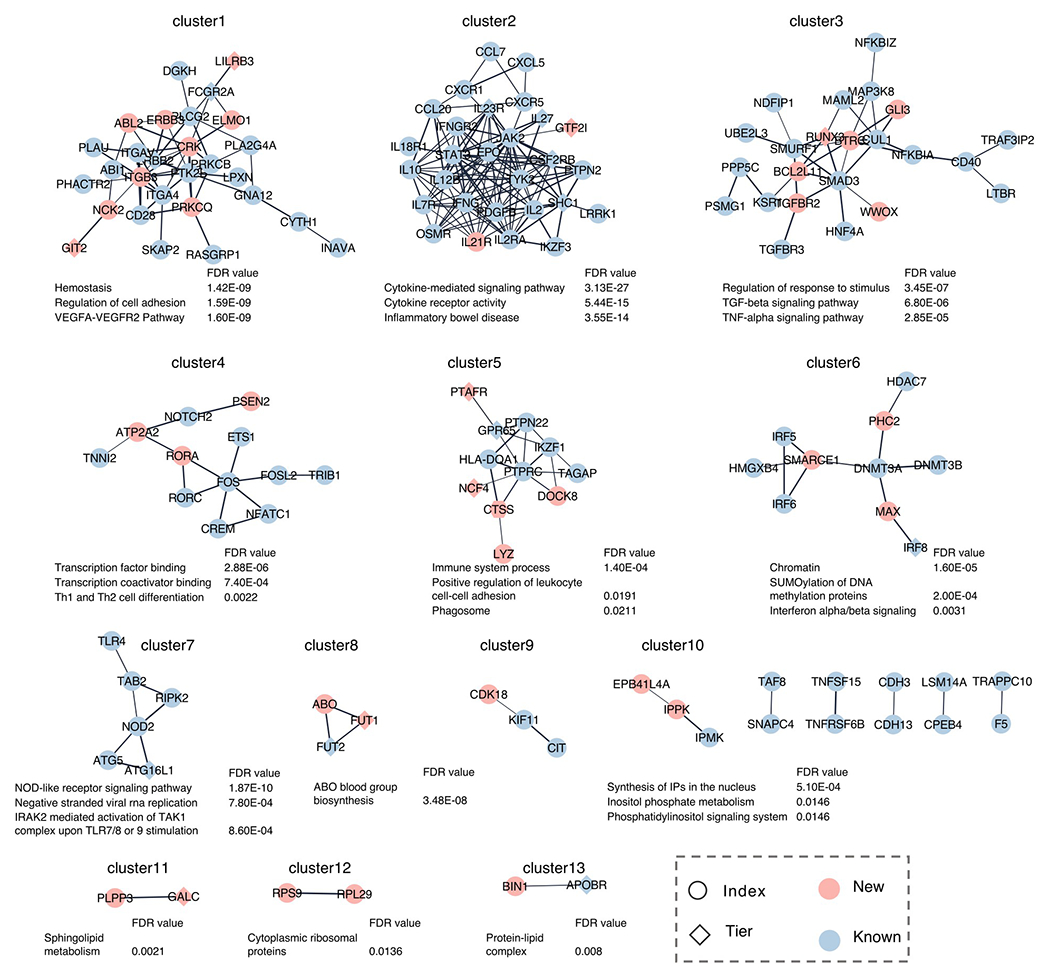
References
-
- Inflammatory bowel disease. in Fast Facts About GI and Liver Diseases for Nurses (Springer Publishing Company, 2016).
METHODS-ONLY REFERENCES
-
- Magro F et al. European Crohn’s and Colitis Organisation [ECCO]. Third European evidence-based consensus on diagnosis and management of ulcerative colitis. Part 1: definitions, diagnosis, extra-intestinal manifestations, pregnancy, cancer surveillance, surgery, and ileo-anal pouch disorders. J. Crohns. Colitis 11, 649–670 (2017). - PubMed
-
- Gomollón F et al. 3rd European Evidence-based Consensus on the Diagnosis and Management of Crohn’s Disease 2016: Part 1: Diagnosis and Medical Management. J. Crohns. Colitis 11, 3–25 (2017). - PubMed
-
- Sturm A et al. ECCO-ESGAR Guideline for Diagnostic Assessment in IBD Part 2: IBD scores and general principles and technical aspects. J. Crohns. Colitis 13, 273–284 (2019). - PubMed
-
- Maaser C et al. ECCO-ESGAR Guideline for Diagnostic Assessment in IBD Part 1: Initial diagnosis, monitoring of known IBD, detection of complications. J. Crohns. Colitis 13, 144–164 (2019). - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
Molecular Biology Databases
