

DEcancer: Machine learning framework tailored to liquid biopsy based cancer detection and biomarker signature selection
- PMID: 37168566
- PMCID: PMC10165183
- DOI: 10.1016/j.isci.2023.106610
DEcancer: Machine learning framework tailored to liquid biopsy based cancer detection and biomarker signature selection
Abstract
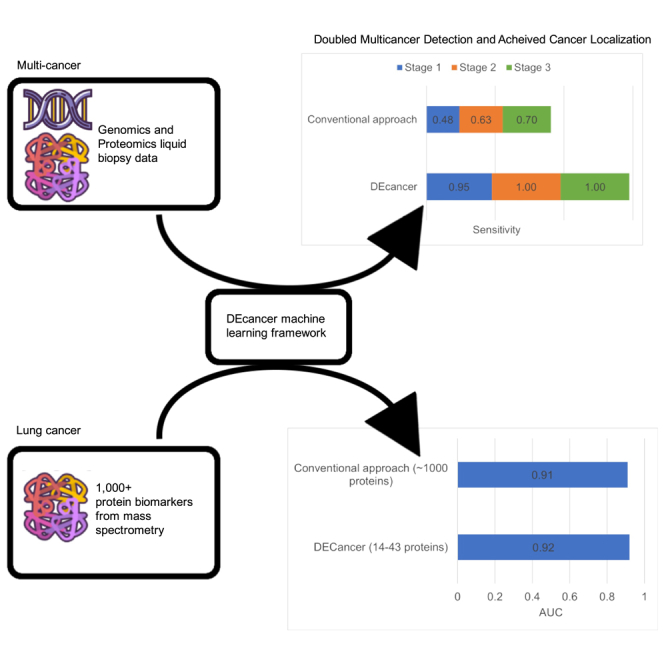
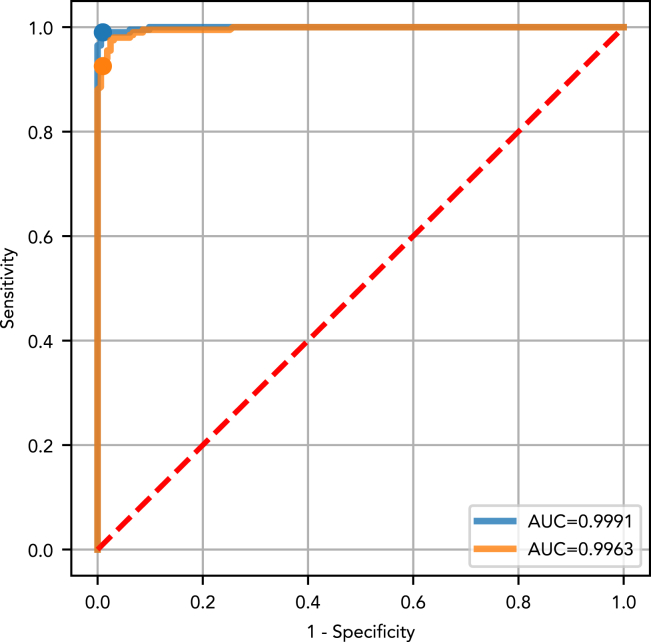
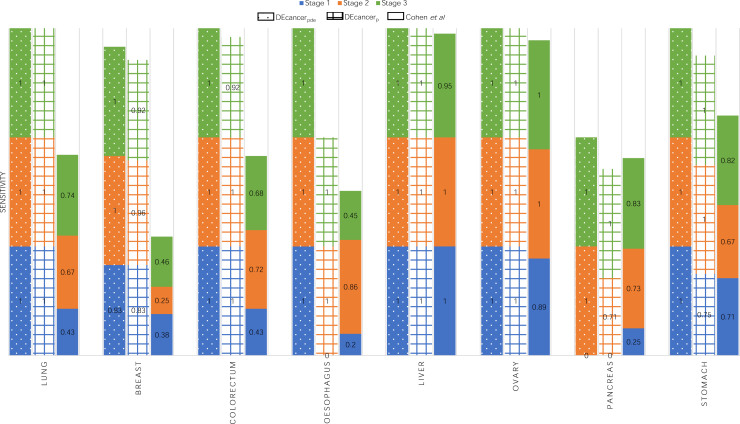
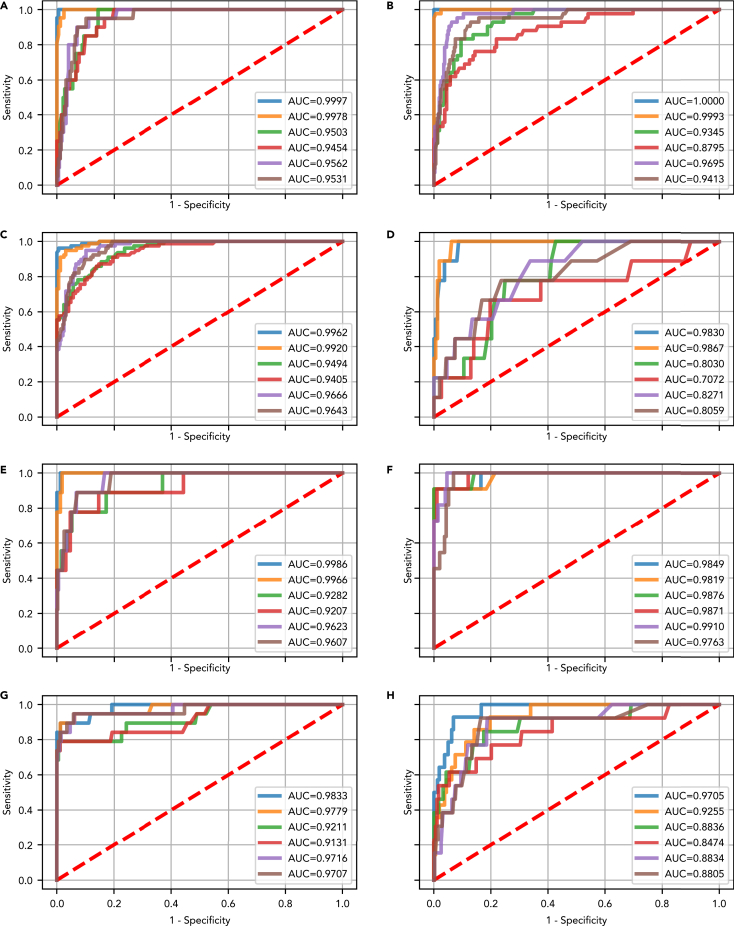
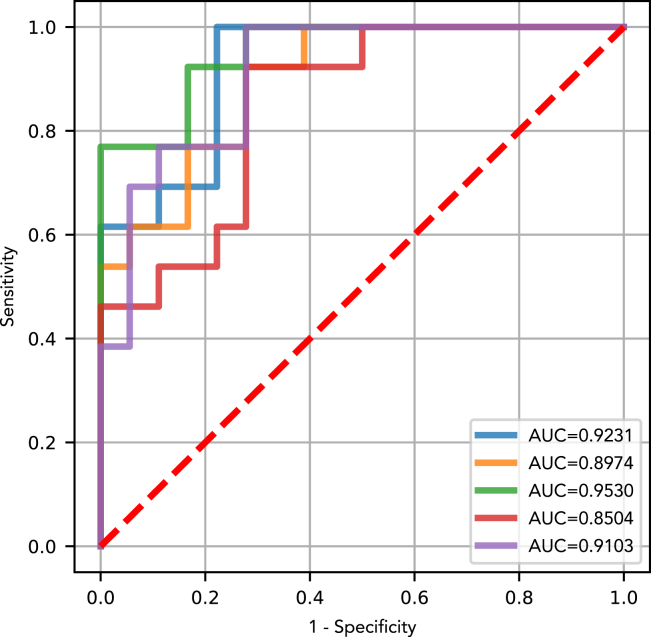
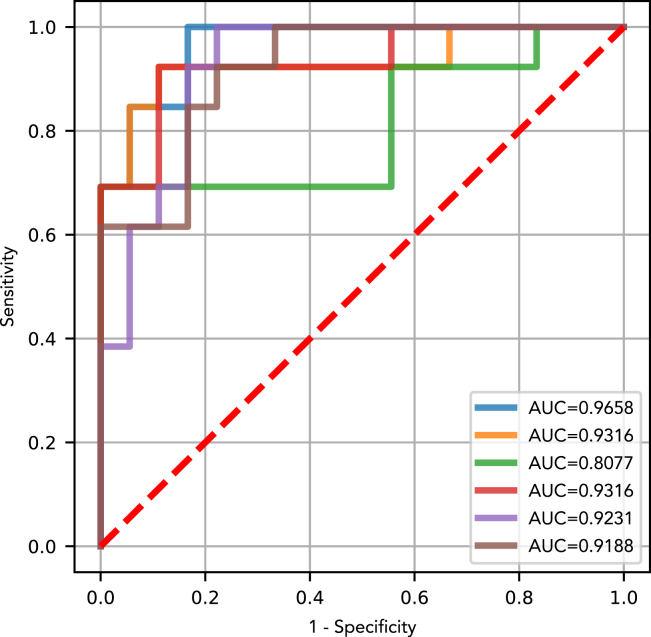
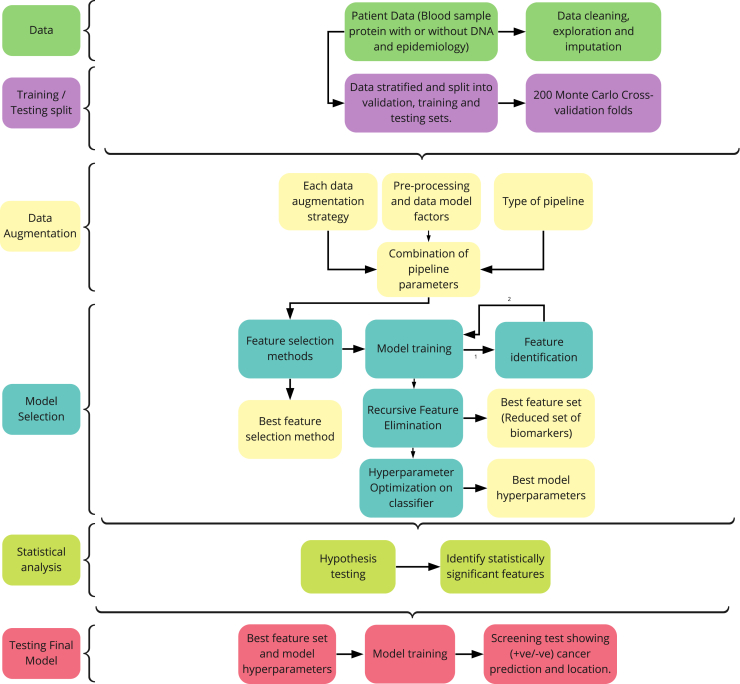
Cancer is a leading cause of mortality worldwide. Over 50% of cancers are diagnosed late, rendering many treatments ineffective. Existing liquid biopsy studies demonstrate a minimally invasive and inexpensive approach for disease detection but lack parsimonious biomarker selection, exhibit poor cancer detection performance and lack appropriate validation and testing. We established a tailored machine learning pipeline, DEcancer, for liquid biopsy analysis that addresses these limitations and improved performance. In a test set from a published cohort of 1,005 patients including 8 cancer types and 812 cancer-free individuals, DEcancer increased stage 1 cancer detection sensitivity across cancer types from 48 to 90%. In addition, with a test set cohort of patients from a high dimensional proteomics dataset of 61 lung cancer patients and 80 cancer-free individuals, DEcancer's performance using a 14-43 protein panel was comparable to 1,000 original proteins. DEcancer is a promising tool which may facilitate improved cancer detection and management.
Keywords: Cancer; Diagnostics; Machine learning.
© 2023 The Authors.
Conflict of interest statement
A.H. is a founder, an employee, and shareholder of Oxford Cancer Analytics Ltd. L.H. is an employee of Oxford Cancer Analytics Ltd. Z.L. is an employee of Oxford Cancer Analytics Ltd. F.P. was an employee and is a shareholder of Oxford Cancer Analytics Ltd. D.S. is an employee and shareholder of Oxford Cancer Analytics Ltd. E.M. is an employee of Oxford Cancer Analytics Ltd. G.L. declares no competing interests. B.K. is a shareholder and member of the Scientific Advisory Board of Oxford Cancer Analytics Ltd. J.S. is an employee of Oxford Cancer Analytics Ltd. P.J.L. is a founder, an employee and shareholder of Oxford Cancer Analytics Ltd. A.H. and P.J.L. are co-inventors of the patent “A METHOD AND SYSTEM DETECTING A HEALTH ABNORMALITY IN A LIQUID BIOPSY SAMPLE” (International Patent Application Number: PCT/EP2022/075710).
Figures
References
-
- Runowicz C.D., Leach C.R., Henry N.L., Henry K.S., Mackey H.T., Cowens-Alvarado R.L., Cannady R.S., Pratt-Chapman M.L., Edge S.B., Jacobs L.A., et al. American cancer society/American society of clinical oncology breast cancer survivorship care guideline. CA. Cancer J. Clin. 2016;66:43–73. doi: 10.3322/caac.21319. - DOI - PubMed
LinkOut - more resources
Full Text Sources
