

Human-Like Modulation Sensitivity Emerging through Optimization to Natural Sound Recognition
- PMID: 37185101
- PMCID: PMC10219008
- DOI: 10.1523/JNEUROSCI.2002-22.2023
Human-Like Modulation Sensitivity Emerging through Optimization to Natural Sound Recognition
Abstract
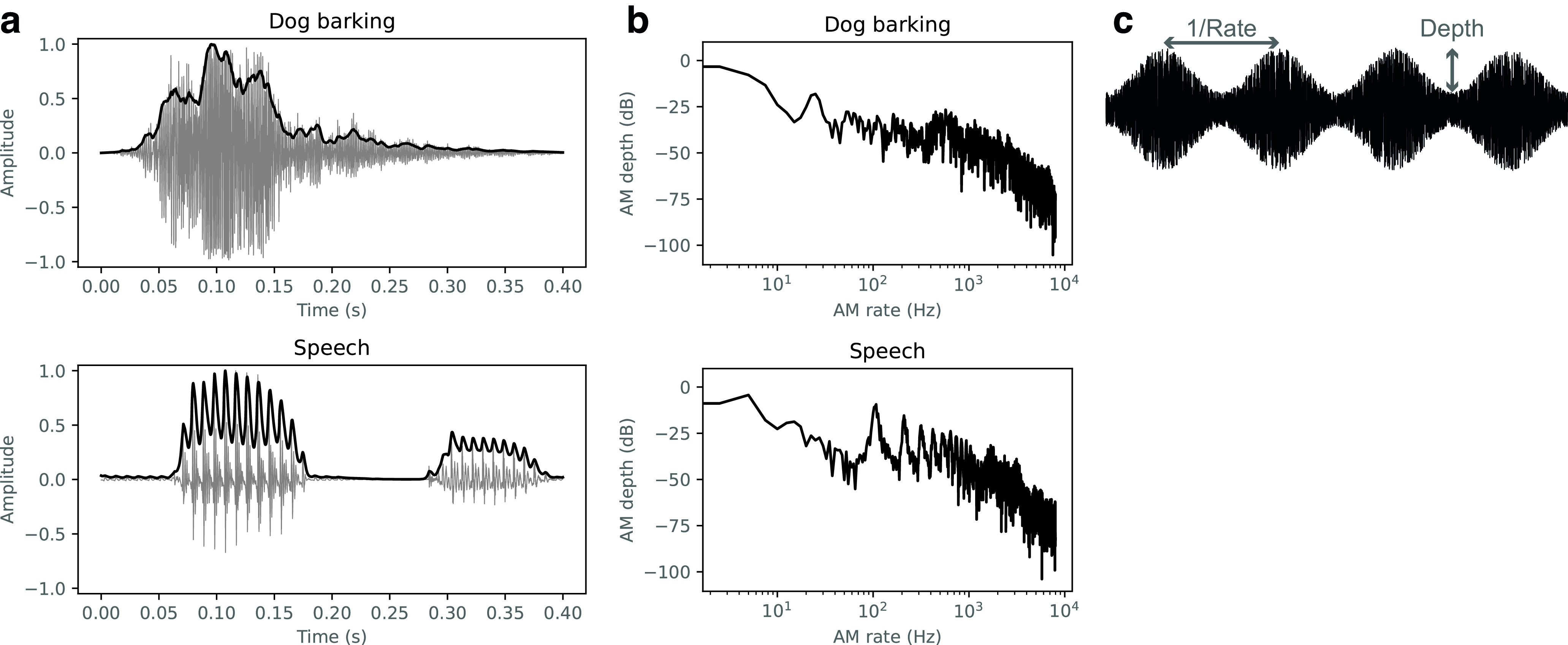
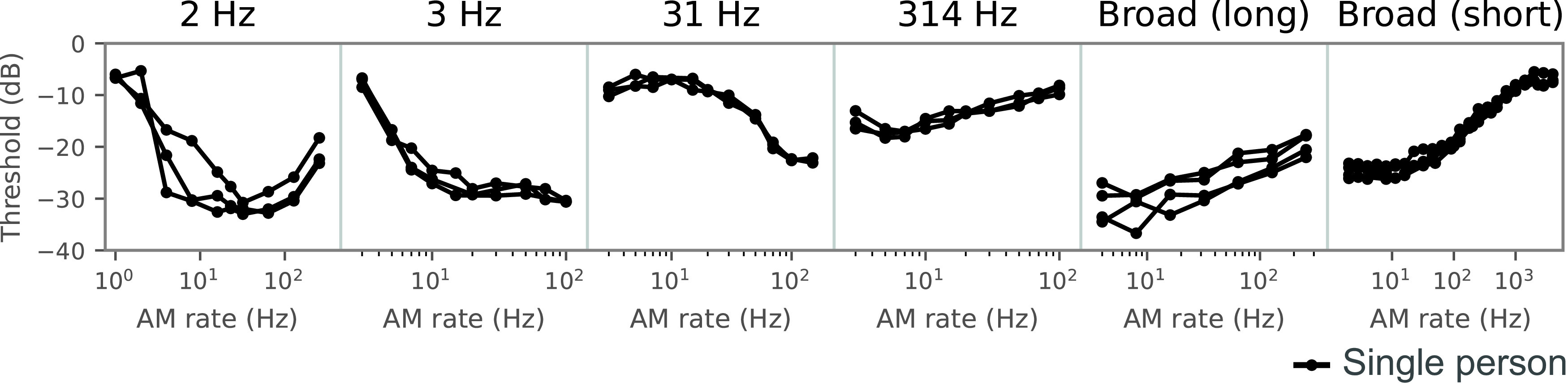
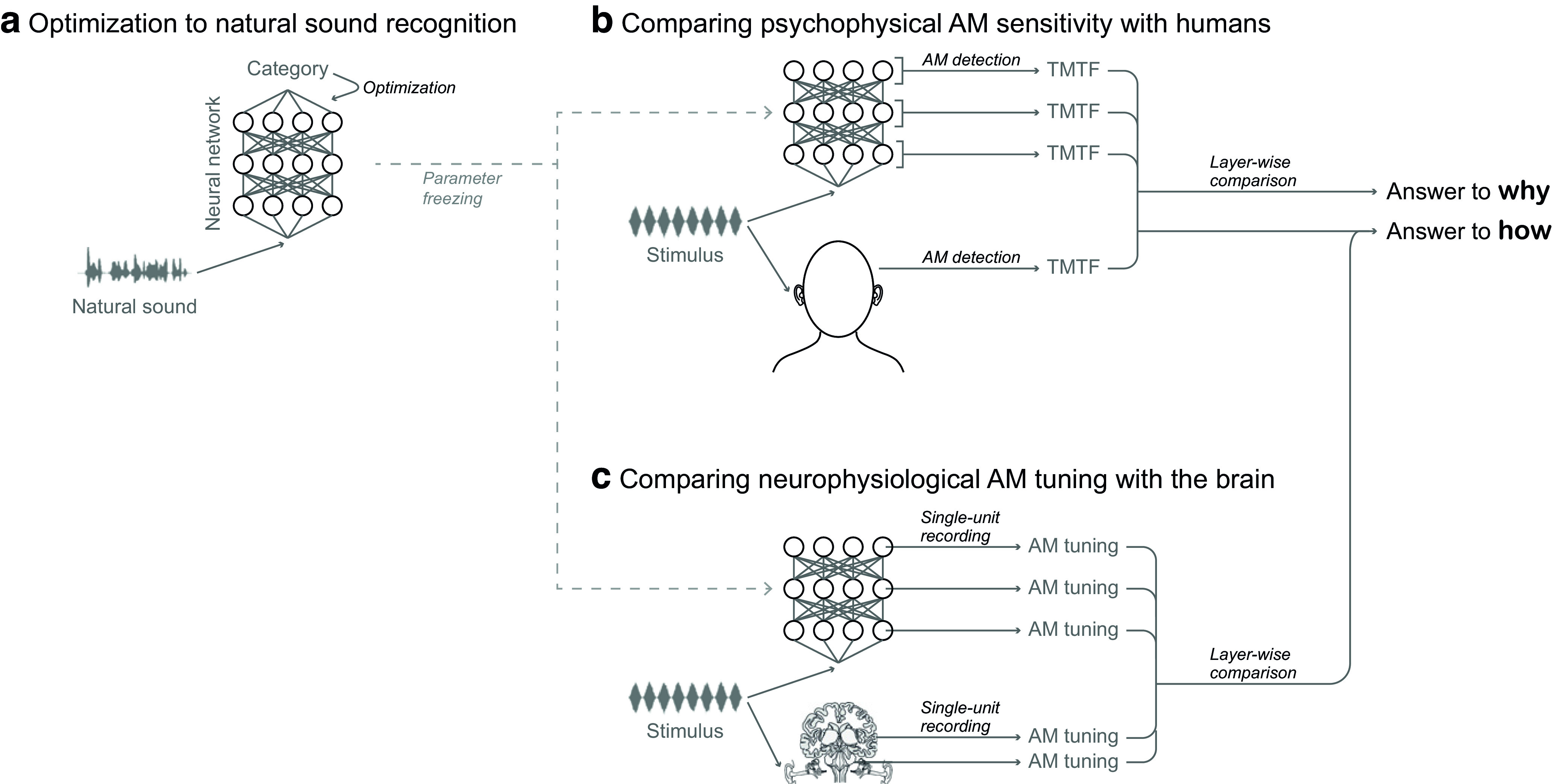
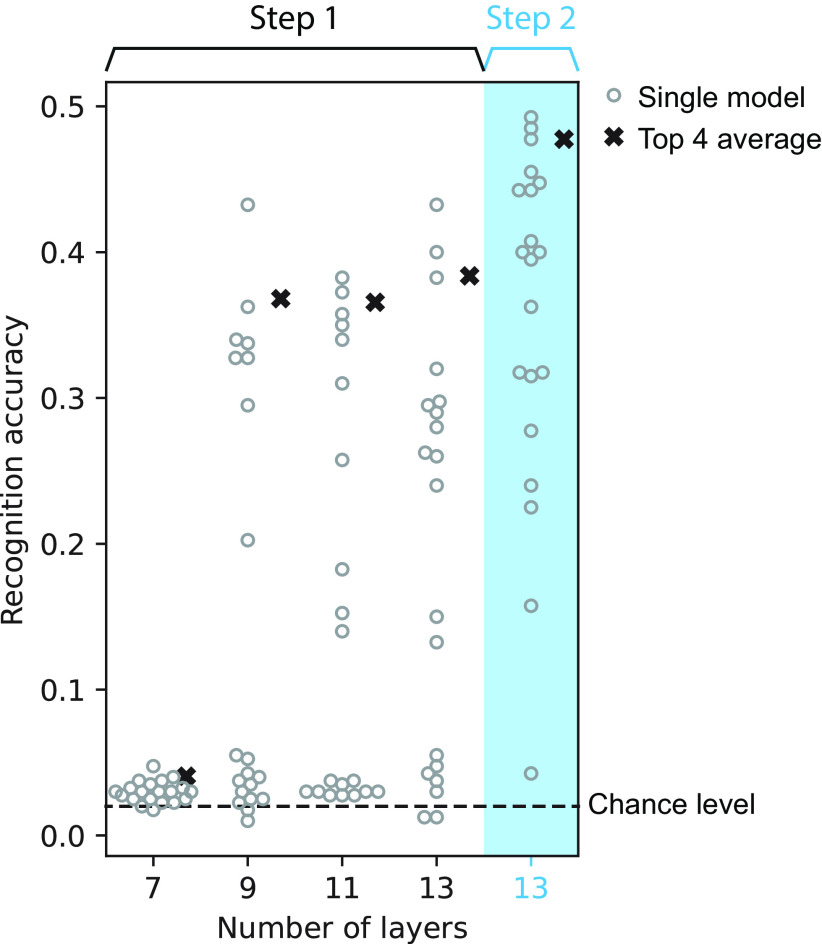
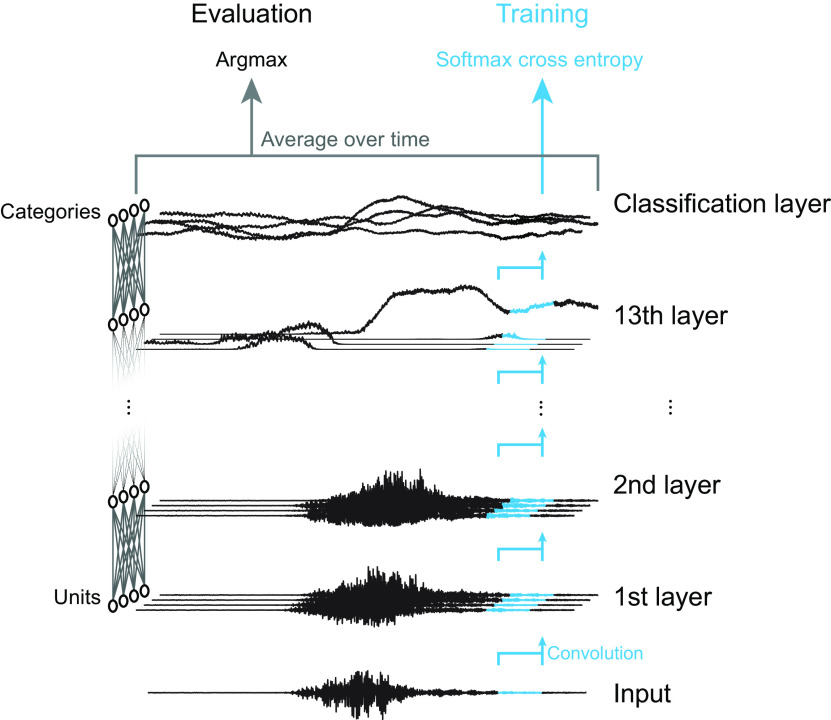
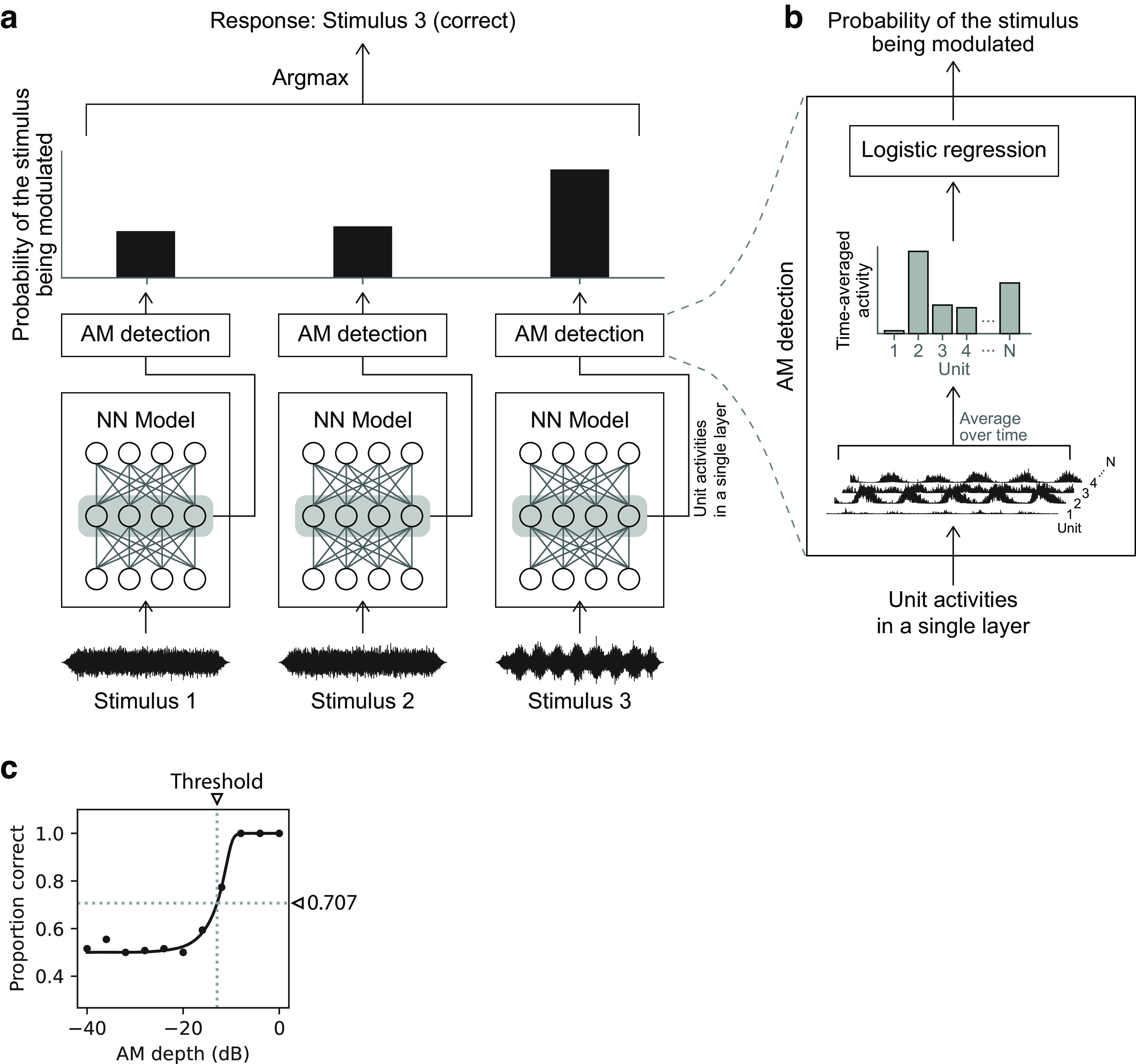
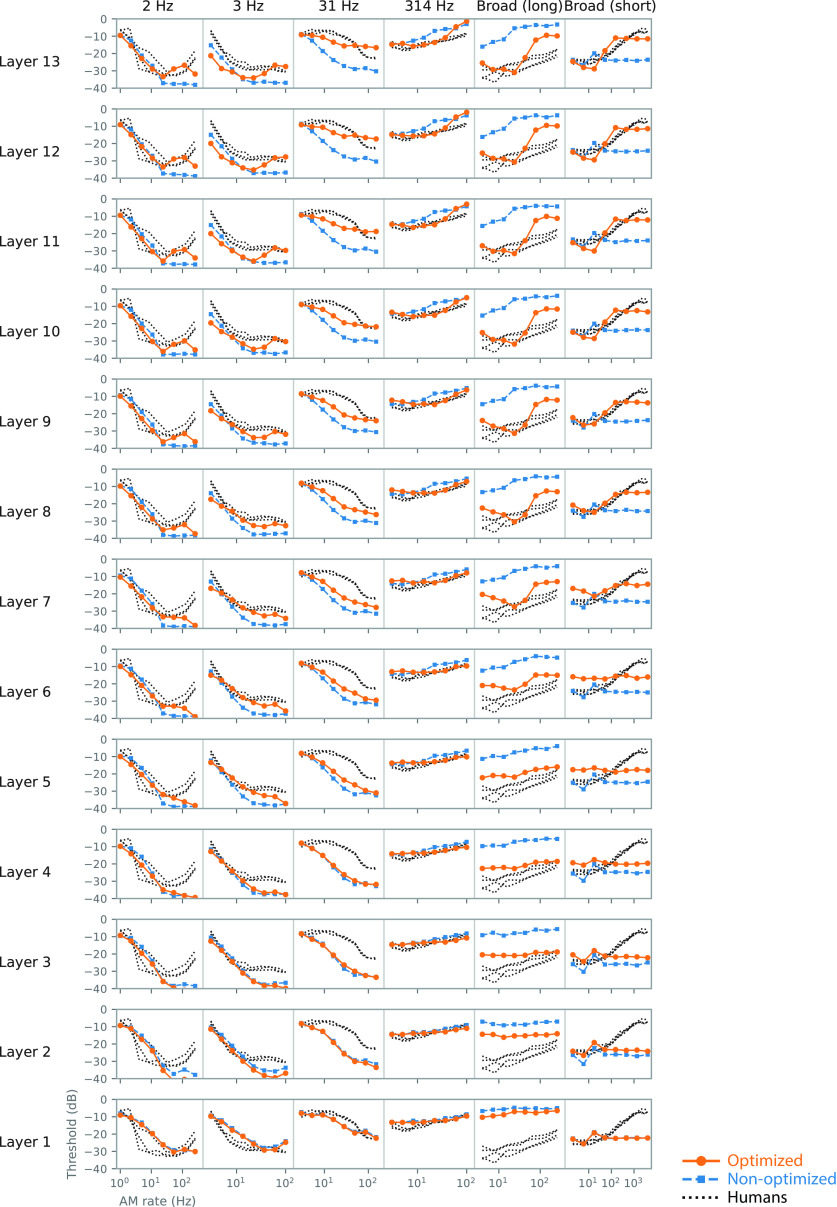
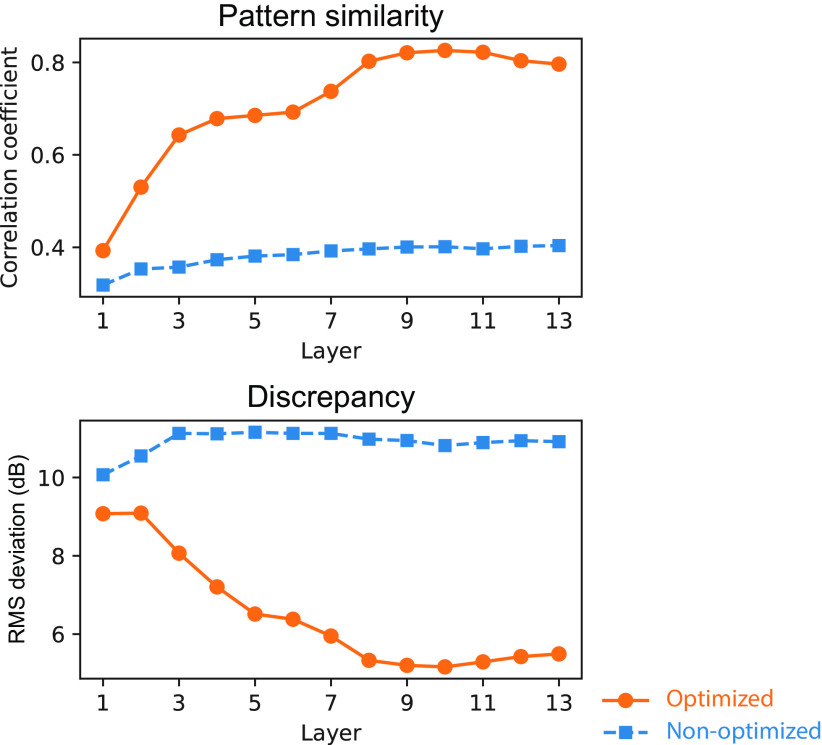
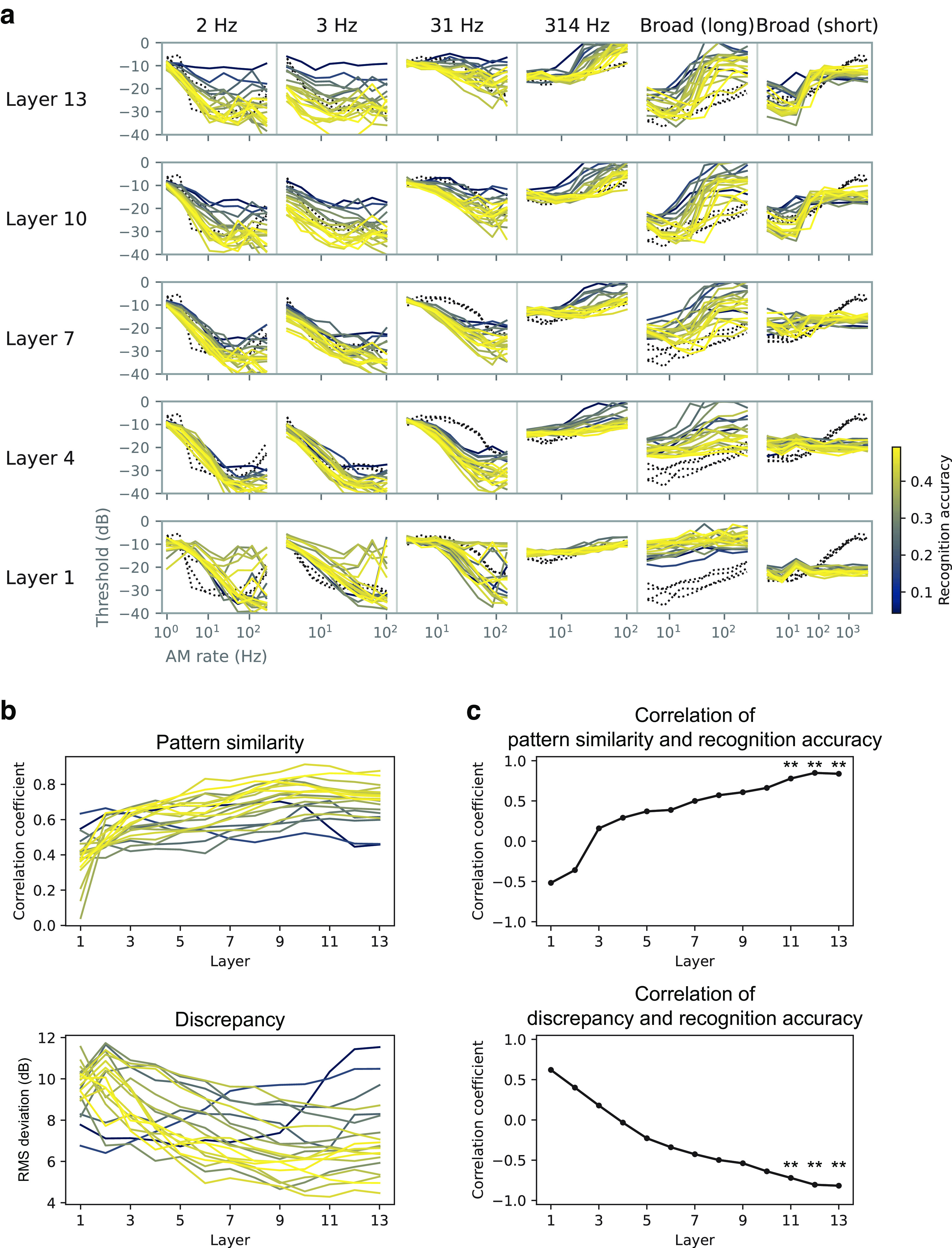
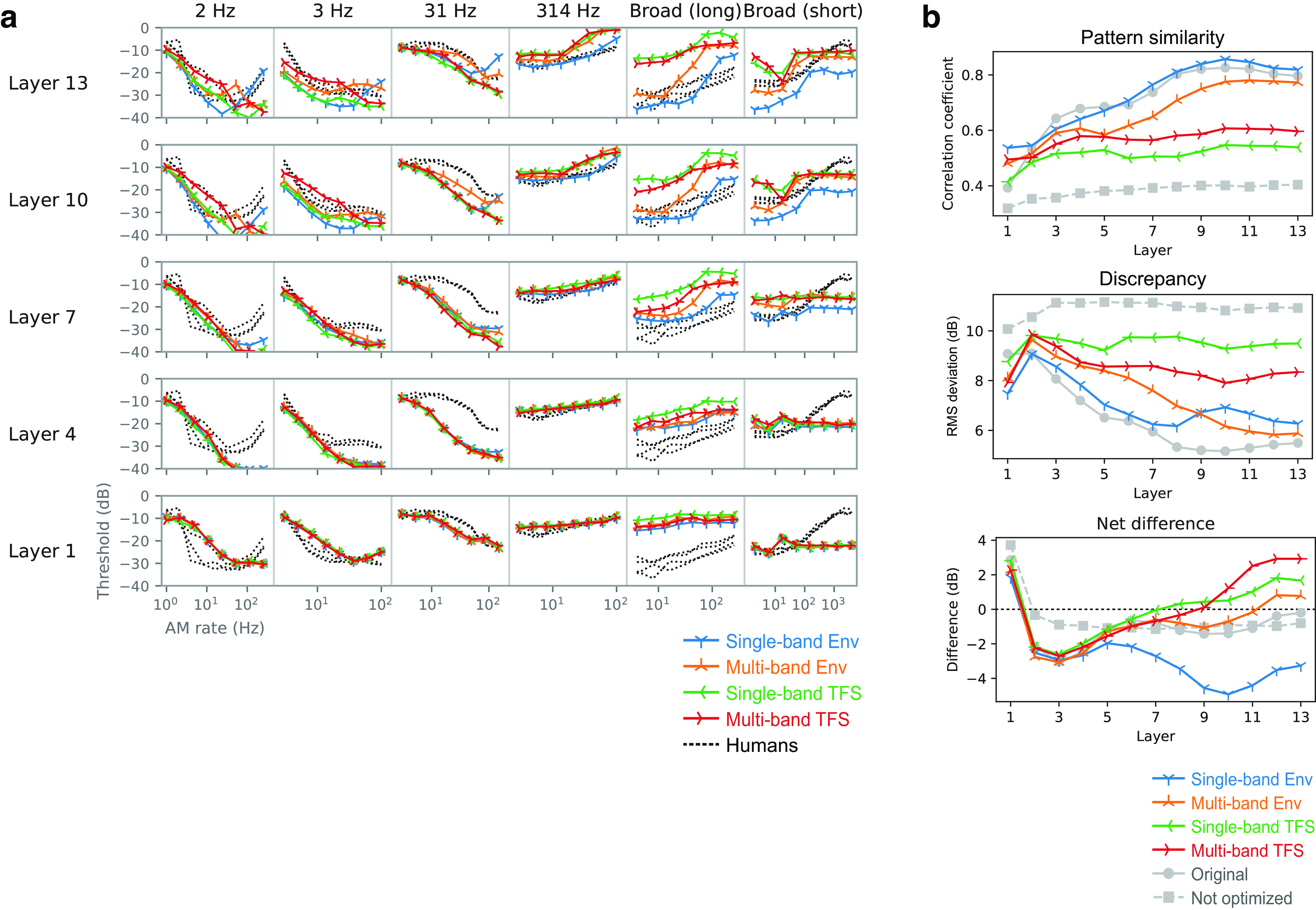
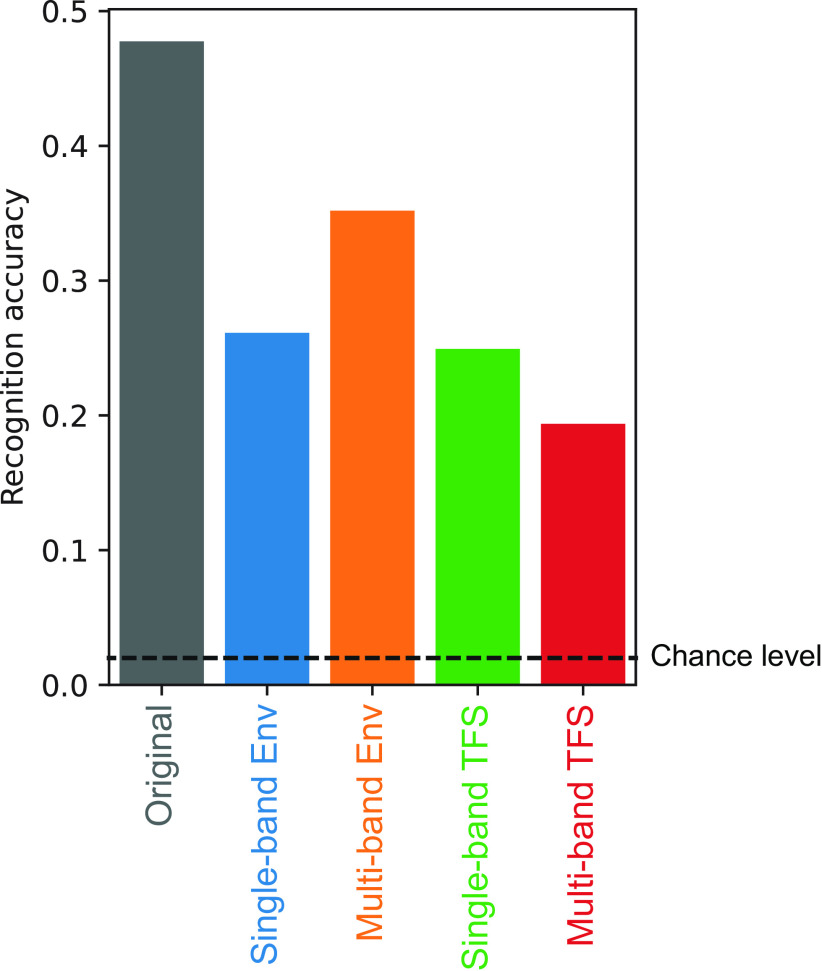
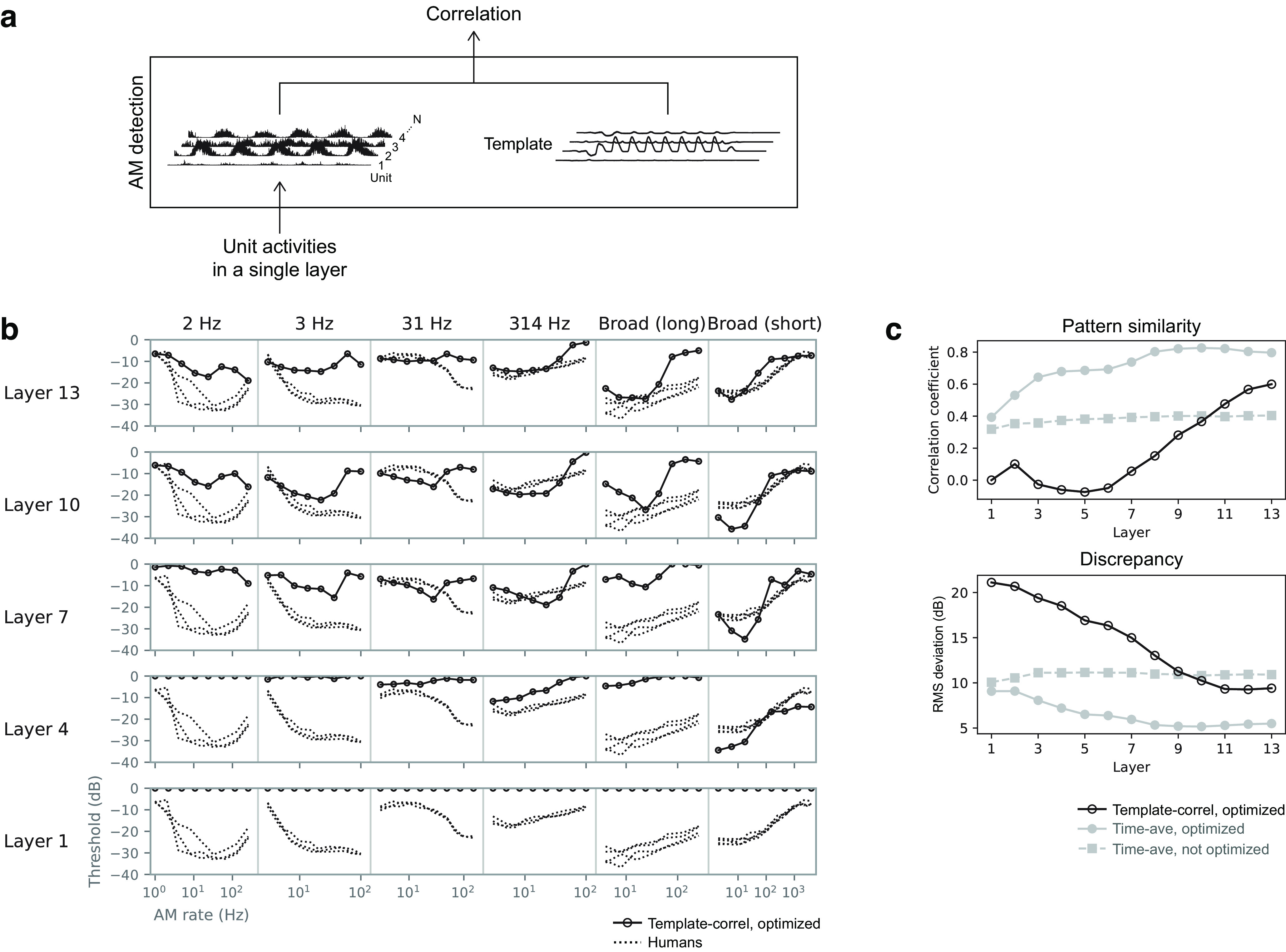
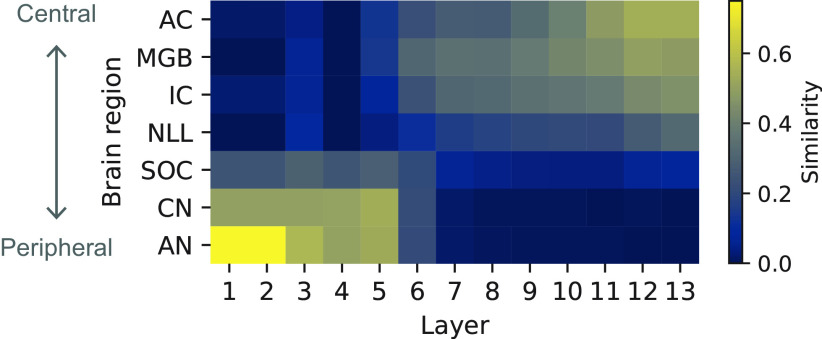
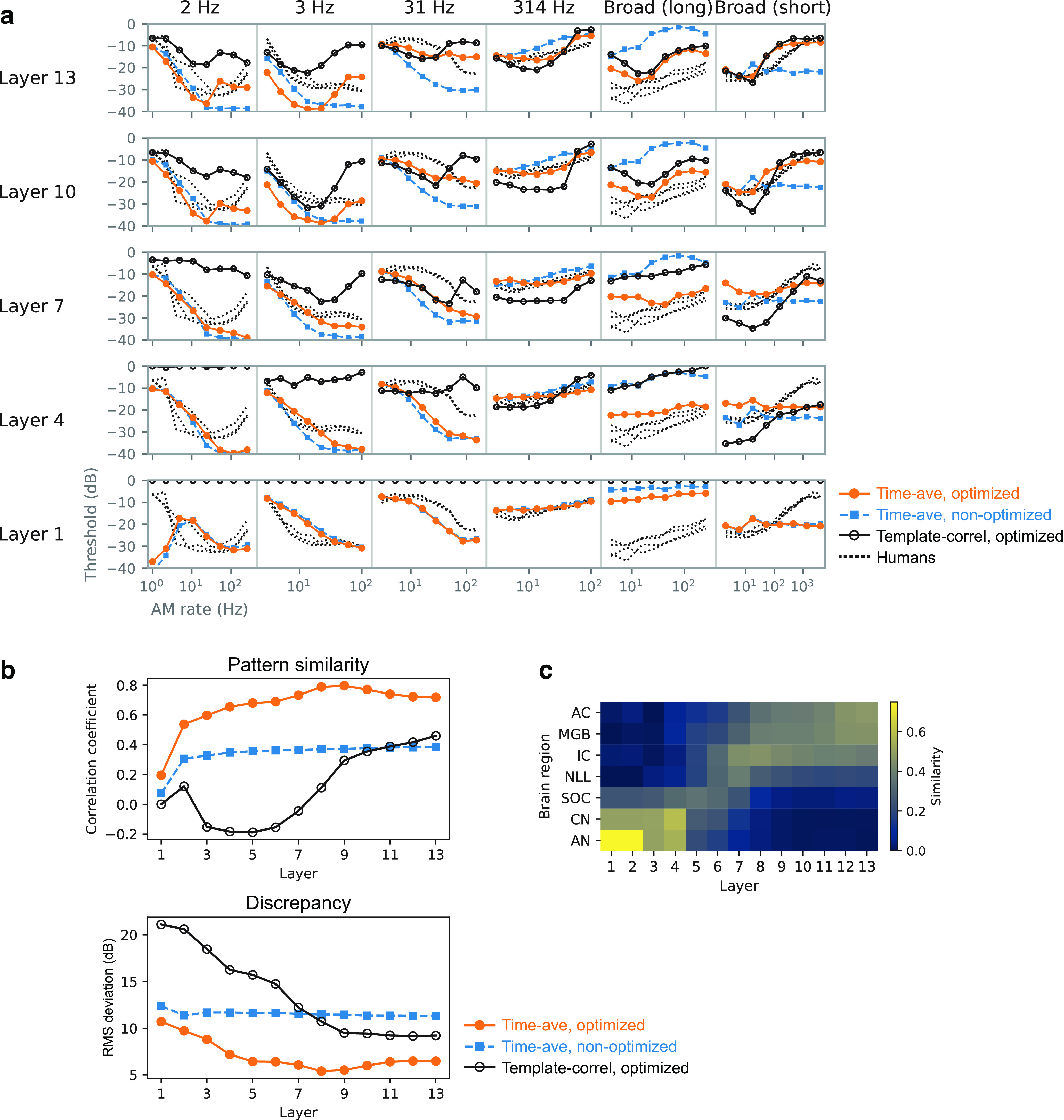
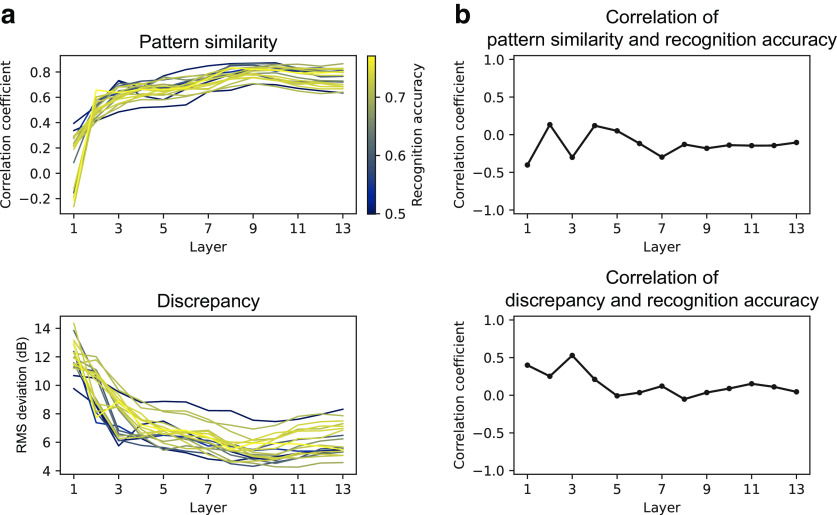
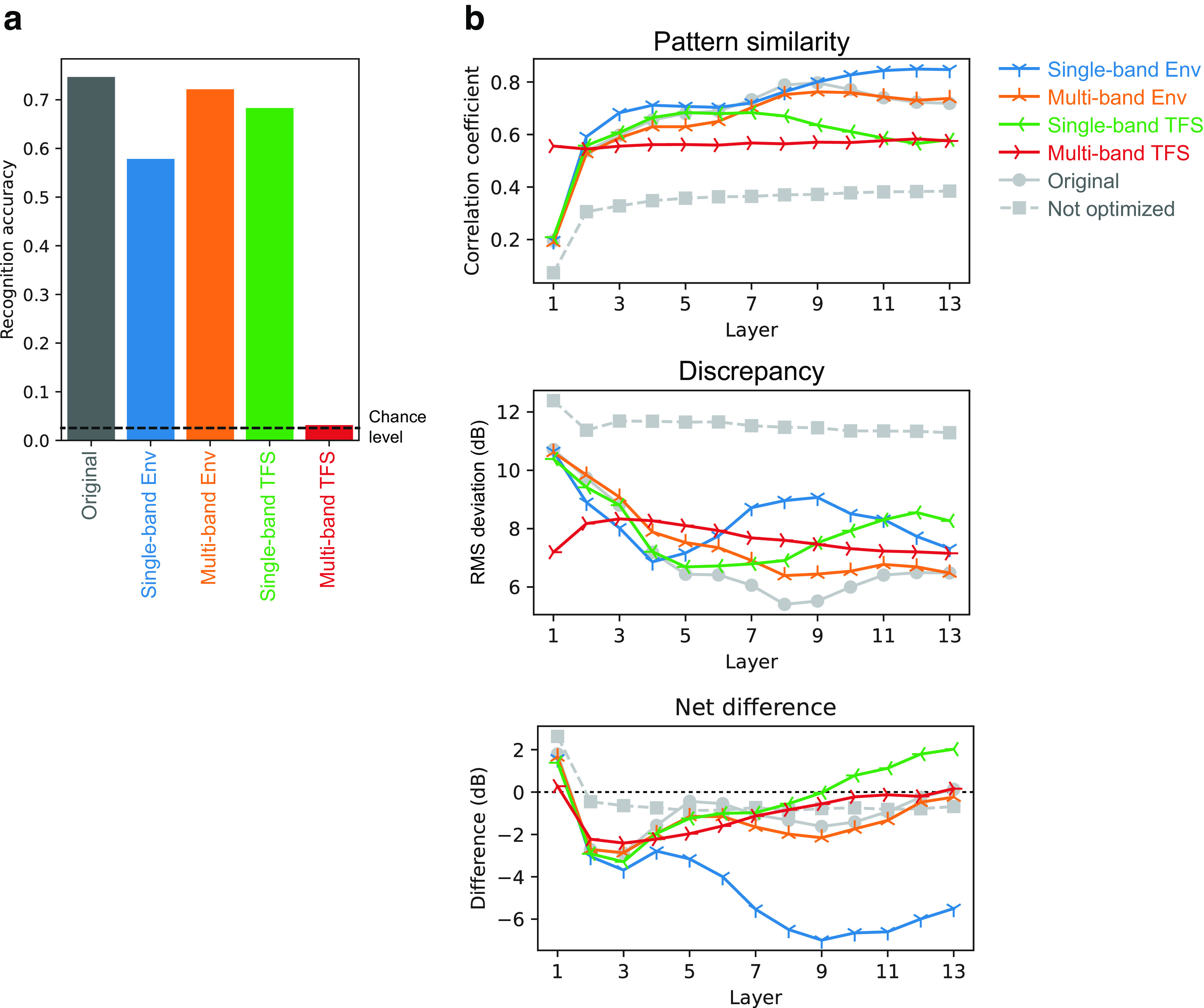
Natural sounds contain rich patterns of amplitude modulation (AM), which is one of the essential sound dimensions for auditory perception. The sensitivity of human hearing to AM measured by psychophysics takes diverse forms depending on the experimental conditions. Here, we address with a single framework the questions of why such patterns of AM sensitivity have emerged in the human auditory system and how they are realized by our neural mechanisms. Assuming that optimization for natural sound recognition has taken place during human evolution and development, we examined its effect on the formation of AM sensitivity by optimizing a computational model, specifically, a multilayer neural network, for natural sound (namely, everyday sounds and speech sounds) recognition and simulating psychophysical experiments in which the AM sensitivity of the model was assessed. Relatively higher layers in the model optimized to sounds with natural AM statistics exhibited AM sensitivity similar to that of humans, although the model was not designed to reproduce human-like AM sensitivity. Moreover, simulated neurophysiological experiments on the model revealed a correspondence between the model layers and the auditory brain regions. The layers in which human-like psychophysical AM sensitivity emerged exhibited substantial neurophysiological similarity with the auditory midbrain and higher regions. These results suggest that human behavioral AM sensitivity has emerged as a result of optimization for natural sound recognition in the course of our evolution and/or development and that it is based on a stimulus representation encoded in the neural firing rates in the auditory midbrain and higher regions.SIGNIFICANCE STATEMENT This study provides a computational paradigm to bridge the gap between the behavioral properties of human sensory systems as measured in psychophysics and neural representations as measured in nonhuman neurophysiology. This was accomplished by combining the knowledge and techniques in psychophysics, neurophysiology, and machine learning. As a specific target modality, we focused on the auditory sensitivity to sound AM. We built an artificial neural network model that performs natural sound recognition and simulated psychophysical and neurophysiological experiments in the model. Quantitative comparison of a machine learning model with human and nonhuman data made it possible to integrate the knowledge of behavioral AM sensitivity and neural AM tunings from the perspective of optimization to natural sound recognition.
Keywords: auditory; modulation; neural network; neurophysiology; psychophysics; sound recognition.
Copyright © 2023 Koumura et al.
Figures
References
-
- Ashihara T, Moriya T, Kashino M (2021) Investigating the impact of spectral and temporal degradation on end-to-end automatic speech recognition performance. Proc Interspeech 2021:1757–1761.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials
Miscellaneous