

Polygenic scoring accuracy varies across the genetic ancestry continuum
- PMID: 37198491
- PMCID: PMC10284707
- DOI: 10.1038/s41586-023-06079-4
Polygenic scoring accuracy varies across the genetic ancestry continuum
Abstract
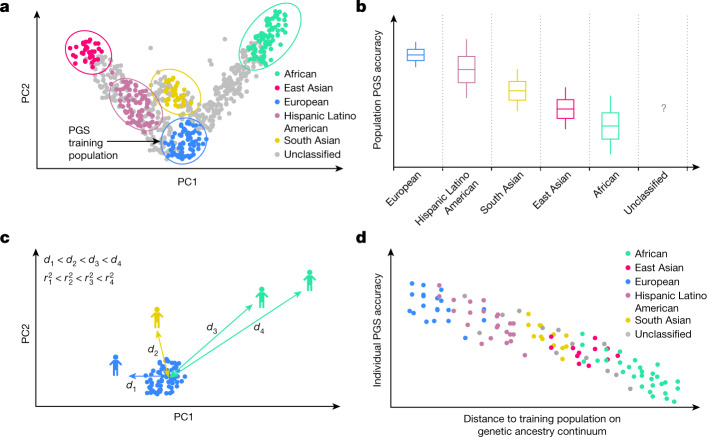
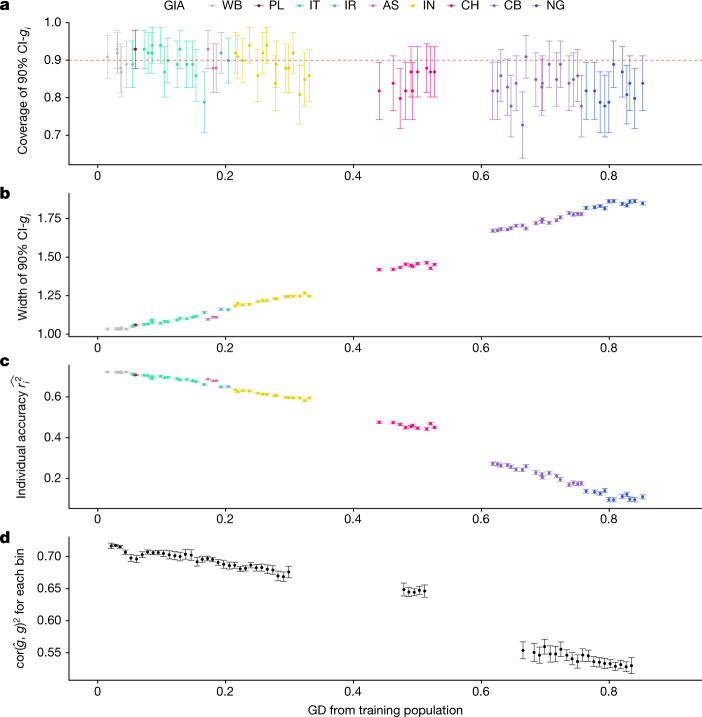
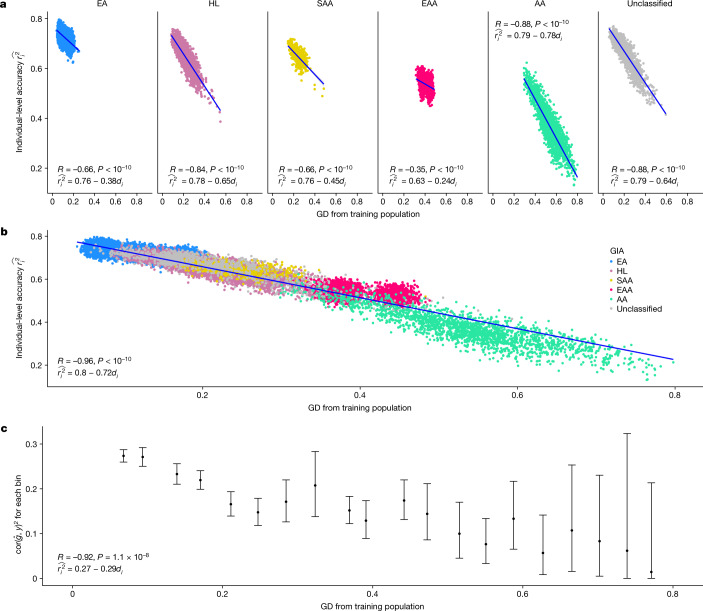
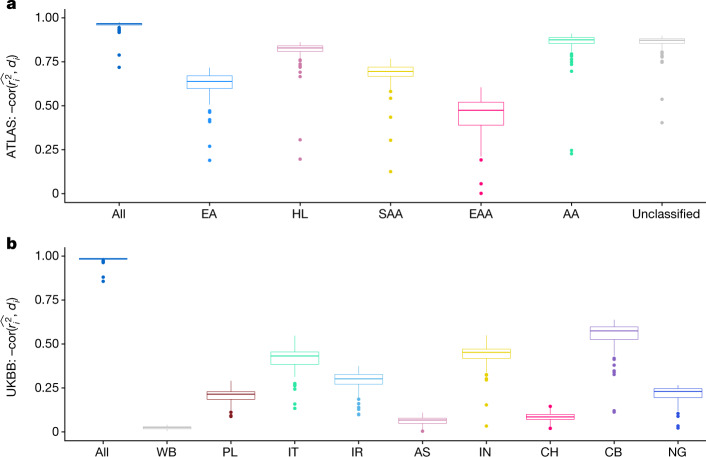
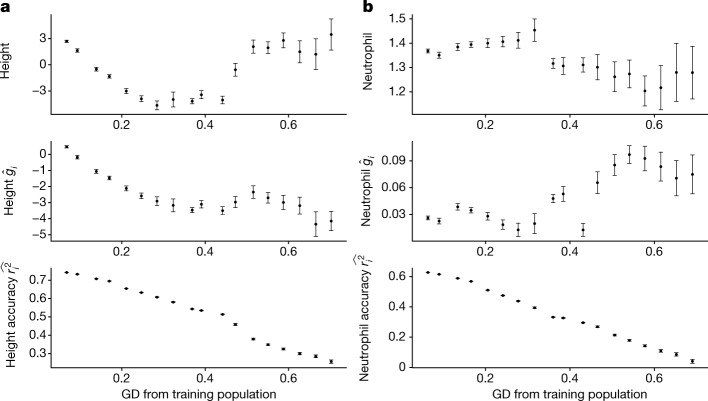
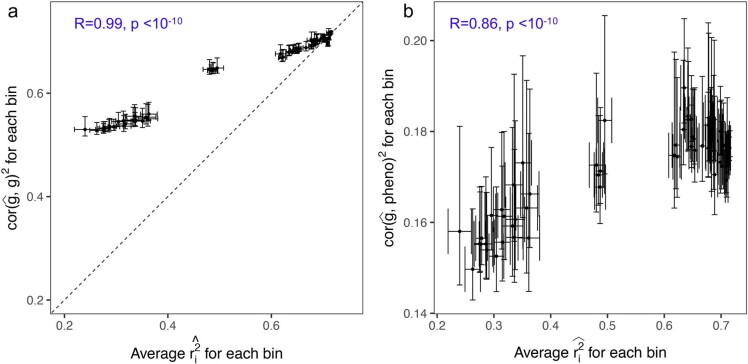
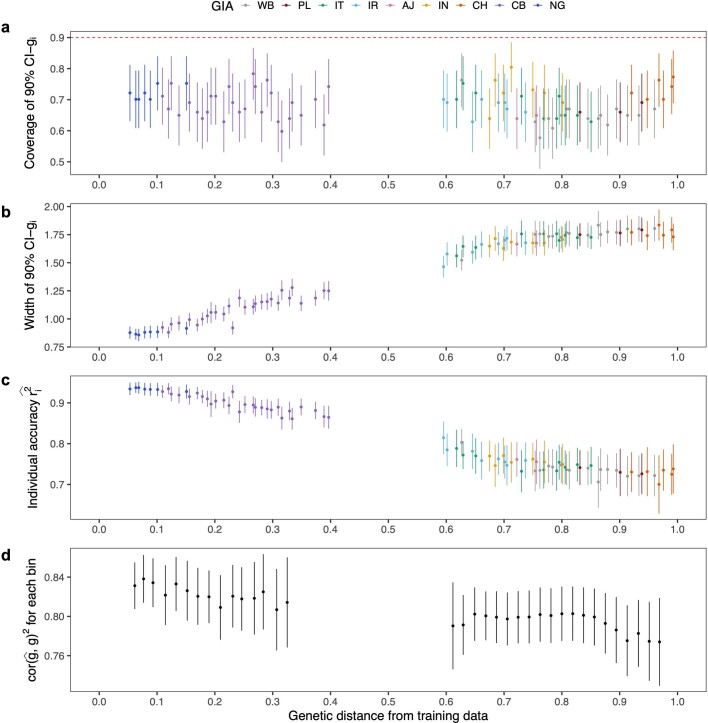
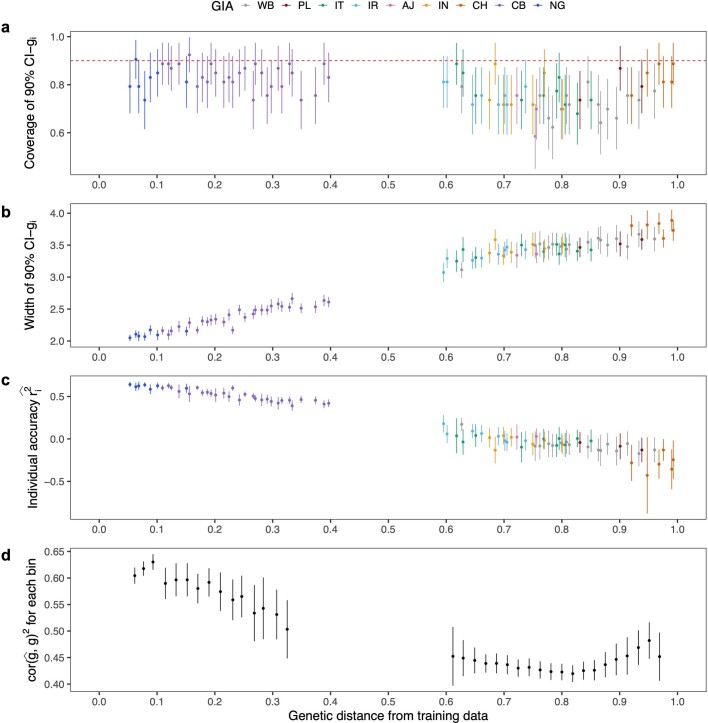
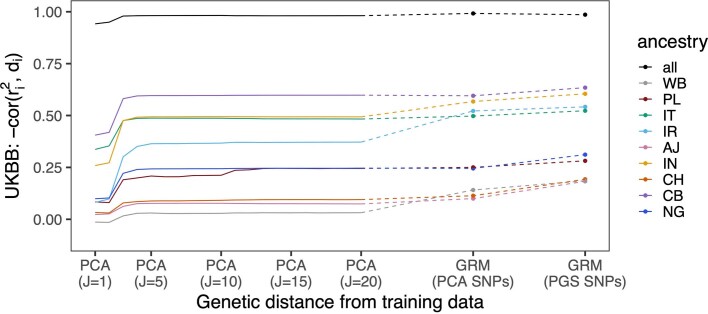
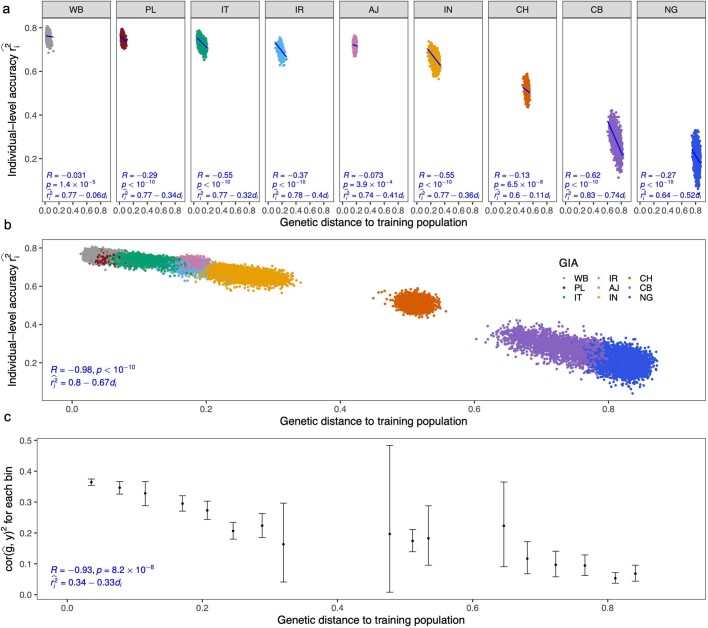
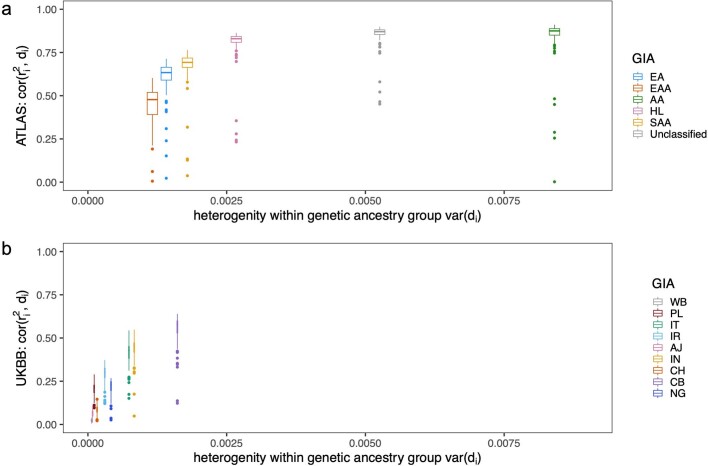
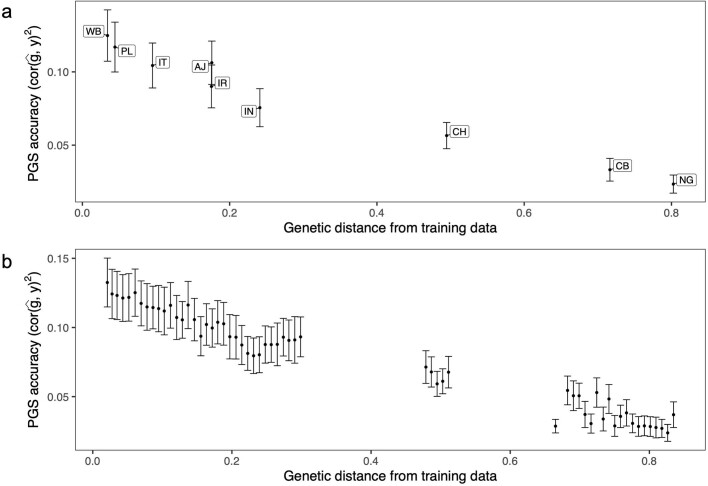
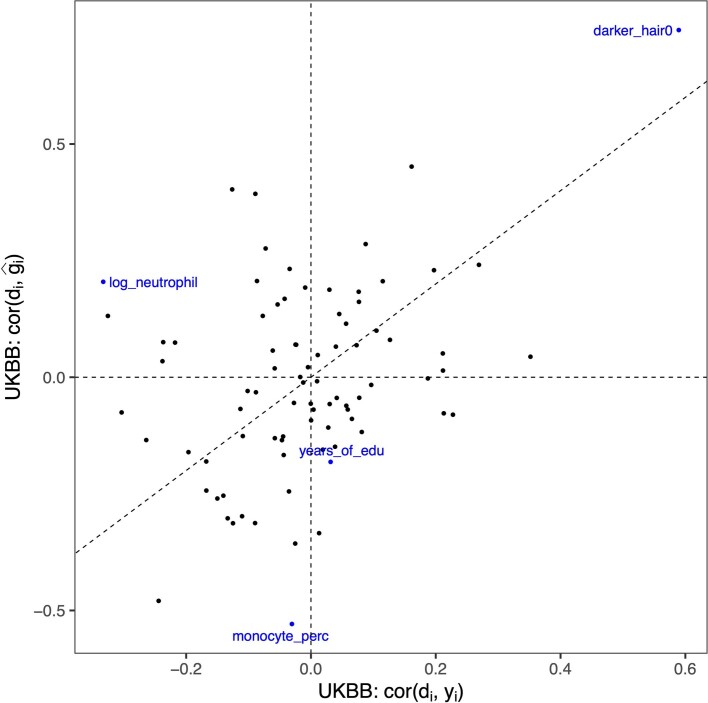
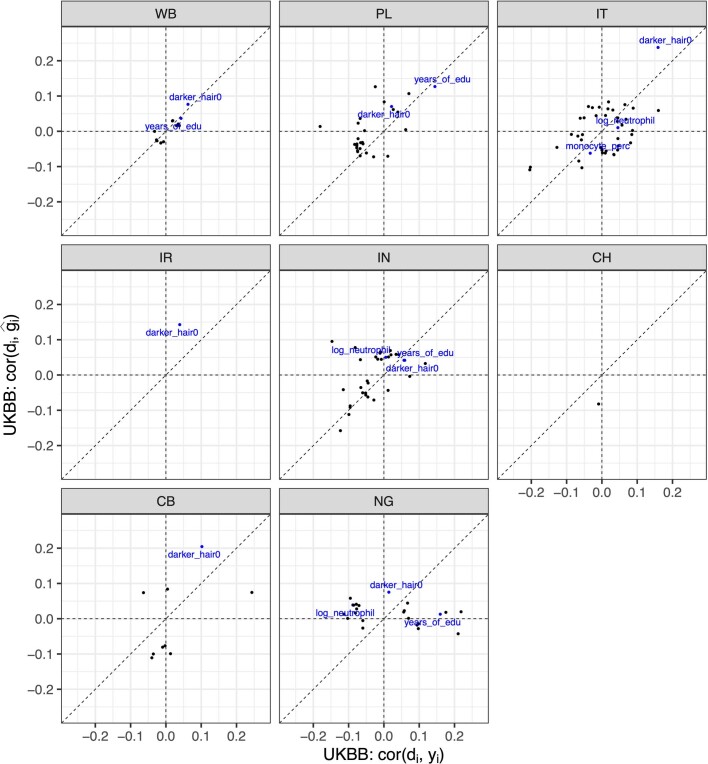
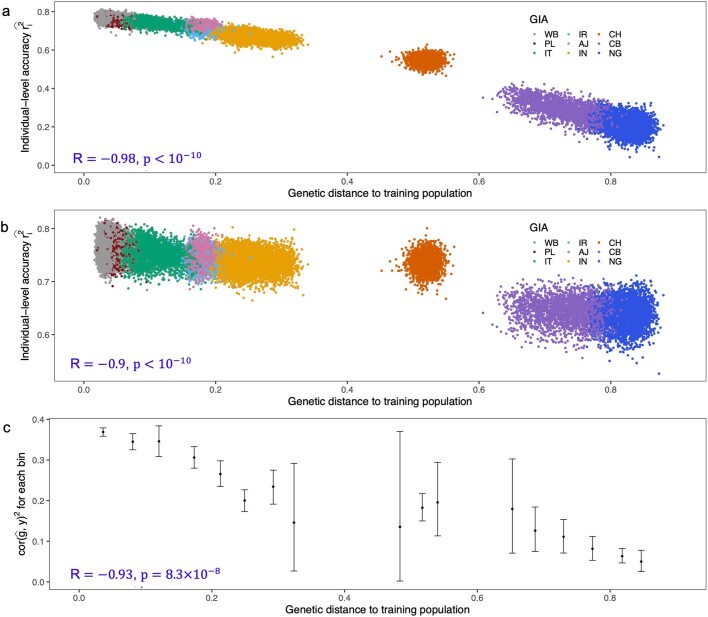
Polygenic scores (PGSs) have limited portability across different groupings of individuals (for example, by genetic ancestries and/or social determinants of health), preventing their equitable use1-3. PGS portability has typically been assessed using a single aggregate population-level statistic (for example, R2)4, ignoring inter-individual variation within the population. Here, using a large and diverse Los Angeles biobank5 (ATLAS, n = 36,778) along with the UK Biobank6 (UKBB, n = 487,409), we show that PGS accuracy decreases individual-to-individual along the continuum of genetic ancestries7 in all considered populations, even within traditionally labelled 'homogeneous' genetic ancestries. The decreasing trend is well captured by a continuous measure of genetic distance (GD) from the PGS training data: Pearson correlation of -0.95 between GD and PGS accuracy averaged across 84 traits. When applying PGS models trained on individuals labelled as white British in the UKBB to individuals with European ancestries in ATLAS, individuals in the furthest GD decile have 14% lower accuracy relative to the closest decile; notably, the closest GD decile of individuals with Hispanic Latino American ancestries show similar PGS performance to the furthest GD decile of individuals with European ancestries. GD is significantly correlated with PGS estimates themselves for 82 of 84 traits, further emphasizing the importance of incorporating the continuum of genetic ancestries in PGS interpretation. Our results highlight the need to move away from discrete genetic ancestry clusters towards the continuum of genetic ancestries when considering PGSs.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
-
- Lambert SA, Abraham G, Inouye M. Towards clinical utility of polygenic risk scores. Hum. Mol. Genet. 2019;28:R133–R142. - PubMed
