

This is a preprint.
Almanac: Retrieval-Augmented Language Models for Clinical Medicine
- PMID: 37205549
- PMCID: PMC10187428
- DOI: 10.21203/rs.3.rs-2883198/v1
Almanac: Retrieval-Augmented Language Models for Clinical Medicine
Update in
-
Almanac - Retrieval-Augmented Language Models for Clinical Medicine.NEJM AI. 2024 Feb;1(2):10.1056/aioa2300068. doi: 10.1056/aioa2300068. Epub 2024 Jan 25. NEJM AI. 2024. PMID: 38343631 Free PMC article.
Abstract
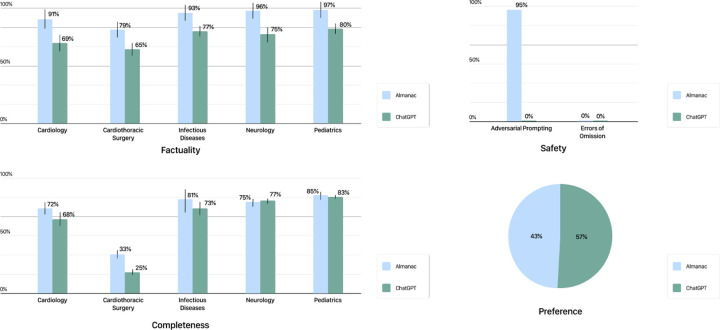
Large-language models have recently demonstrated impressive zero-shot capabilities in a variety of natural language tasks such as summarization, dialogue generation, and question-answering. Despite many promising applications in clinical medicine, adoption of these models in real-world settings has been largely limited by their tendency to generate incorrect and sometimes even toxic statements. In this study, we develop Almanac, a large language model framework augmented with retrieval capabilities for medical guideline and treatment recommendations. Performance on a novel dataset of clinical scenarios (n= 130) evaluated by a panel of 5 board-certified and resident physicians demonstrates significant increases in factuality (mean of 18% at p-value < 0.05) across all specialties, with improvements in completeness and safety. Our results demonstrate the potential for large language models to be effective tools in the clinical decision-making process, while also emphasizing the importance of careful testing and deployment to mitigate their shortcomings.
Conflict of interest statement
Competing interests The authors declare no competing interests.
Figures

References
-
- Brown T.B., Mann B., Ryder N., Subbiah M., Kaplan J., Dhariwal P., Neelakantan A., Shyam P., Sastry G., Askell A., Agarwal S., Herbert-Voss A., Krueger G., Henighan T., Child R., Ramesh A., Ziegler D.M., Wu J., Winter C., Hesse C., Chen M., Sigler E., Litwin M., Gray S., Chess B., Clark J., Berner C., McCandlish S., Radford A., Sutskever I., Amodei D.: Language Models are Few-Shot Learners. arXiv (2020). 10.48550/ARXIV.2005.14165. https://arxiv.org/abs/2005.14165 - DOI
-
- Chen M., Tworek J., Jun H., Yuan Q., de Oliveira Pinto H.P., Kaplan J., Edwards H., Burda Y., Joseph N., Brockman G., Ray A., Puri R., Krueger G., Petrov M., Khlaaf H., Sastry G., Mishkin P., Chan B., Gray S., Ryder N., Pavlov M., Power A., Kaiser L., Bavarian M., Winter C., Tillet P., Such F.P., Cummings D., Plappert M., Chantzis F., Barnes E., Herbert-Voss A., Guss W.H., Nichol A., Paino A., Tezak N., Tang J., Babuschkin I., Balaji S., Jain S., Saunders W., Hesse C., Carr A.N., Leike J., Achiam J., Misra V., Morikawa E., Radford A., Knight M., Brundage M., Murati M., Mayer K., Welinder P., McGrew B., Amodei D., McCandlish S., Sutskever I., Zaremba W.: Evaluating large language models trained on code. CoRR abs/2107.03374 (2021) 2107.03374
-
- Wei C., Xie S.M., Ma T.: Why Do Pretrained Language Models Help in Downstream Tasks? An Analysis of Head and Prompt Tuning. arXiv (2021). 10.48550/ARXIV.2106.09226. https://arxiv.org/abs/2106.09226 - DOI
-
- Devlin J., Chang M.-W., Lee K., Toutanova K.: BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv (2018). 10.48550/ARXIV.1810.04805. https://arxiv.org/abs/1810.04805 - DOI
-
- Wei J., Tay Y., Bommasani R., Raffel C., Zoph B., Borgeaud S., Yogatama D., Bosma M., Zhou D., Metzler D., Chi E.H., Hashimoto T., Vinyals O., Liang P., Dean J., Fedus W.: Emergent Abilities of Large Language Models. arXiv (2022). 10.48550/ARXIV.2206.07682. https://arxiv.org/abs/2206.07682 - DOI
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
