

This is a preprint.
Distinct genetic liability profiles define clinically relevant patient strata across common diseases
- PMID: 37214898
- PMCID: PMC10197798
- DOI: 10.1101/2023.05.10.23289788
Distinct genetic liability profiles define clinically relevant patient strata across common diseases
Update in
-
Distinct genetic liability profiles define clinically relevant patient strata across common diseases.Nat Commun. 2024 Jul 1;15(1):5534. doi: 10.1038/s41467-024-49338-2. Nat Commun. 2024. PMID: 38951512 Free PMC article.
Abstract
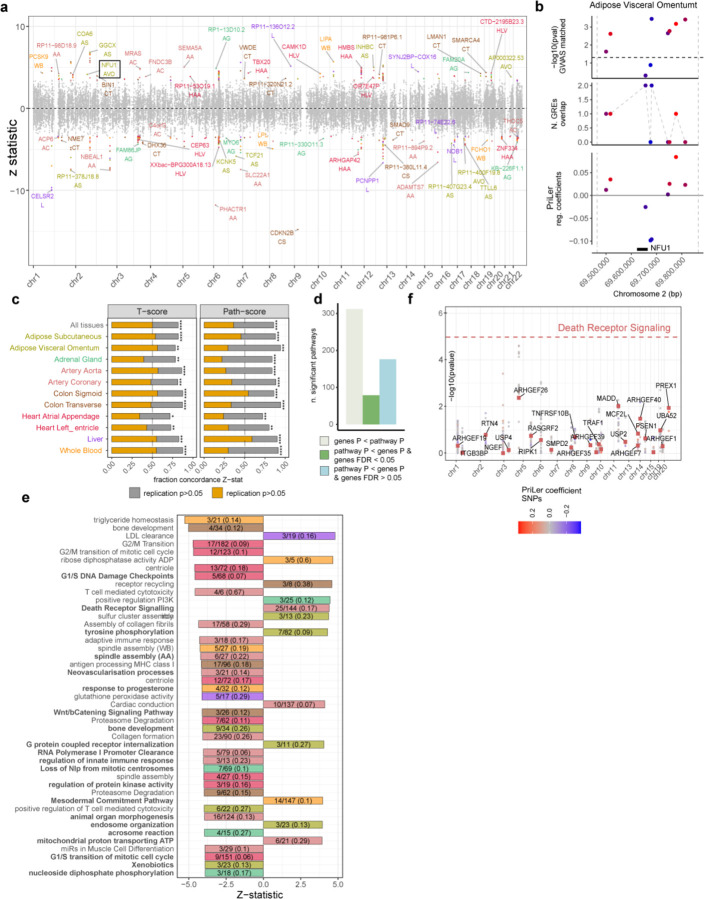
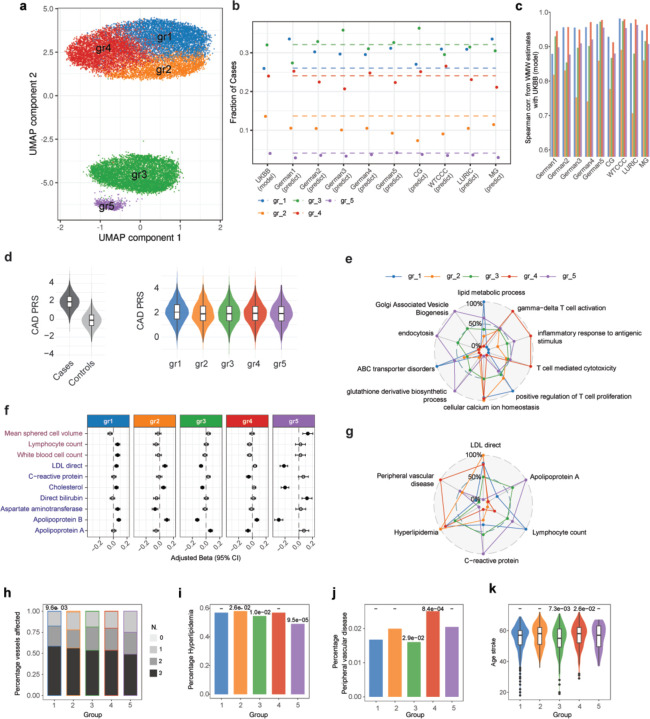
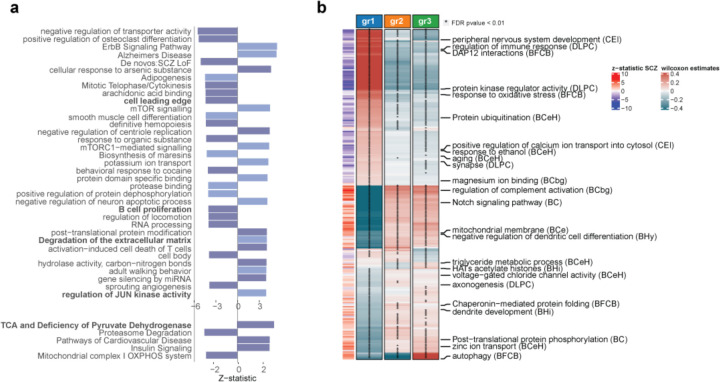
Genome-wide association studies have unearthed a wealth of genetic associations across many complex diseases. However, translating these associations into biological mechanisms contributing to disease etiology and heterogeneity has been challenging. Here, we hypothesize that the effects of disease-associated genetic variants converge onto distinct cell type specific molecular pathways within distinct subgroups of patients. In order to test this hypothesis, we develop the CASTom-iGEx pipeline to operationalize individual level genotype data to interpret personal polygenic risk and identify the genetic basis of clinical heterogeneity. The paradigmatic application of this approach to coronary artery disease and schizophrenia reveals a convergence of disease associated variant effects onto known and novel genes, pathways, and biological processes. The biological process specific genetic liabilities are not equally distributed across patients. Instead, they defined genetically distinct groups of patients, characterized by different profiles across pathways, endophenotypes, and disease severity. These results provide further evidence for a genetic contribution to clinical heterogeneity and point to the existence of partially distinct pathomechanisms across patient subgroups. Thus, the universally applicable approach presented here has the potential to constitute an important component of future personalized medicine concepts.
Conflict of interest statement
Competing interest: F.I. receives funding from Open Targets, a public-private initiative involving academia and industry, and performs consultancy for the joint AstraZeneca-CRUK functional genomics centre and for Mosaic Therapeutics. TFMA is a salaried employee of Boehringer Ingelheim Pharma outside the submitted work.
Figures

References
-
- McCarthy M. I. et al. Genome-wide association studies for complex traits: consensus, uncertainty and challenges. Nat Rev Genet 9, 356–369 (2008). https://doi.org: 10.1038/nrg2344 - DOI - PubMed
-
- Gallagher M. D. & Chen-Plotkin A. S. The Post-GWAS Era: From Association to Function. Am J Hum Genet 102, 717–730 (2018). https://doi.org: 10.1016/j.ajhg.2018.04.002 - DOI - PMC - PubMed
-
- Visscher P. M. et al. 10 Years of GWAS Discovery: Biology, Function, and Translation. Am J Hum Genet 101, 5–22 (2017). https://doi.org: 10.1016/j.ajhg.2017.06.005 - DOI - PMC - PubMed
-
- Finucane H. K. et al. Partitioning heritability by functional annotation using genome-wide association summary statistics. Nat Genet 47, 1228–1235 (2015). https://doi.org: 10.1038/ng.3404 - DOI - PMC - PubMed
-
- Bernstein B. E. et al. An integrated encyclopedia of DNA elements in the human genome. Nature 489, 57–74 (2012). https://doi.org: 10.1038/nature11247 - DOI - PMC - PubMed
Publication types
Grants and funding
- R01 MH109897/MH/NIMH NIH HHS/United States
- R37 MH057881/MH/NIMH NIH HHS/United States
- R01 MH075916/MH/NIMH NIH HHS/United States
- U01 MH103392/MH/NIMH NIH HHS/United States
- R01 MH109677/MH/NIMH NIH HHS/United States
- P50 MH084053/MH/NIMH NIH HHS/United States
- HHSN271201300031C/DA/NIDA NIH HHS/United States
- R01 MH110921/MH/NIMH NIH HHS/United States
- P50 MH066392/MH/NIMH NIH HHS/United States
- R01 MH080405/MH/NIMH NIH HHS/United States
- R01 MH085542/MH/NIMH NIH HHS/United States
- R01 MH097276/MH/NIMH NIH HHS/United States
- P01 AG002219/AG/NIA NIH HHS/United States
- R01 MH093725/MH/NIMH NIH HHS/United States
- P50 AG005138/AG/NIA NIH HHS/United States
LinkOut - more resources
Full Text Sources