

Classification of imbalanced data using machine learning algorithms to predict the risk of renal graft failures in Ethiopia
- PMID: 37217892
- PMCID: PMC10201495
- DOI: 10.1186/s12911-023-02185-5
Classification of imbalanced data using machine learning algorithms to predict the risk of renal graft failures in Ethiopia
Abstract
Introduction: The prevalence of end-stage renal disease has raised the need for renal replacement therapy over recent decades. Even though a kidney transplant offers an improved quality of life and lower cost of care than dialysis, graft failure is possible after transplantation. Hence, this study aimed to predict the risk of graft failure among post-transplant recipients in Ethiopia using the selected machine learning prediction models.
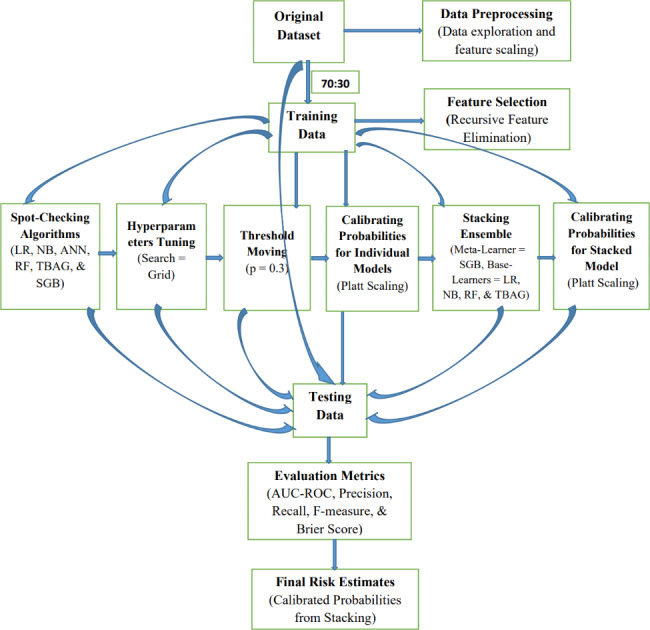
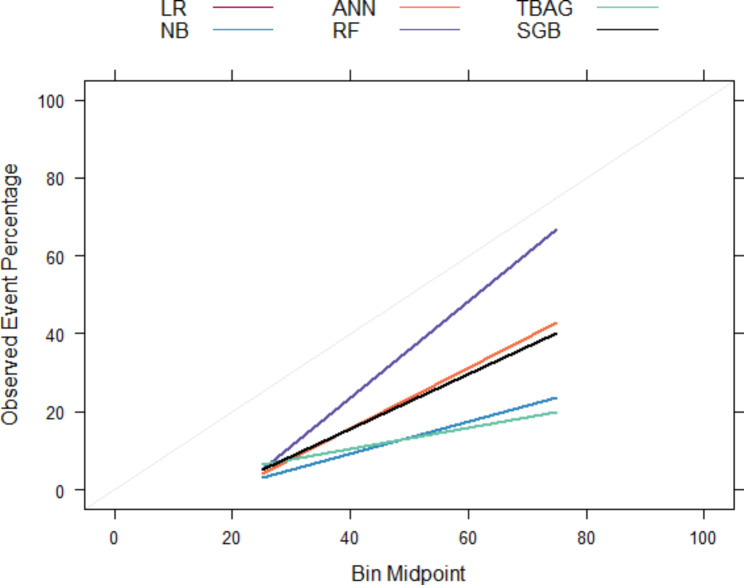
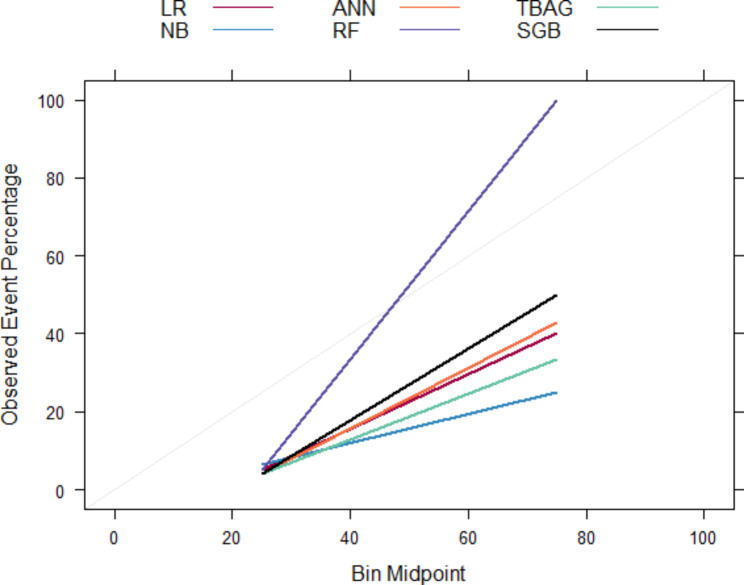
Methodology: The data was extracted from the retrospective cohort of kidney transplant recipients at the Ethiopian National Kidney Transplantation Center from September 2015 to February 2022. In response to the imbalanced nature of the data, we performed hyperparameter tuning, probability threshold moving, tree-based ensemble learning, stacking ensemble learning, and probability calibrations to improve the prediction results. Merit-based selected probabilistic (logistic regression, naive Bayes, and artificial neural network) and tree-based ensemble (random forest, bagged tree, and stochastic gradient boosting) models were applied. Model comparison was performed in terms of discrimination and calibration performance. The best-performing model was then used to predict the risk of graft failure.
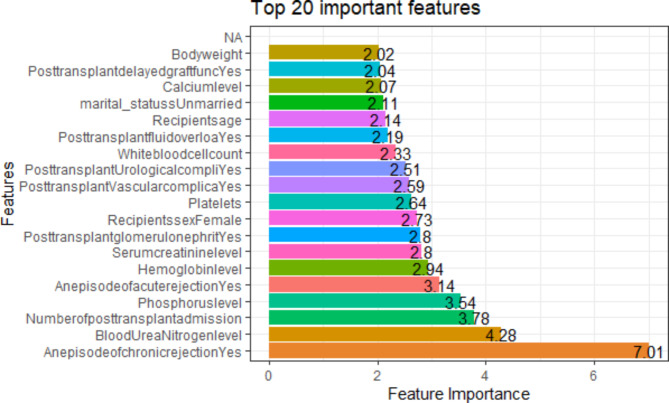
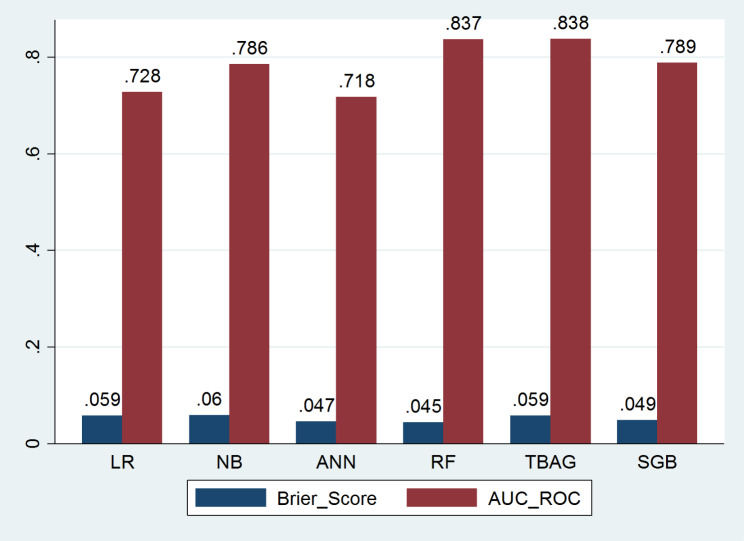
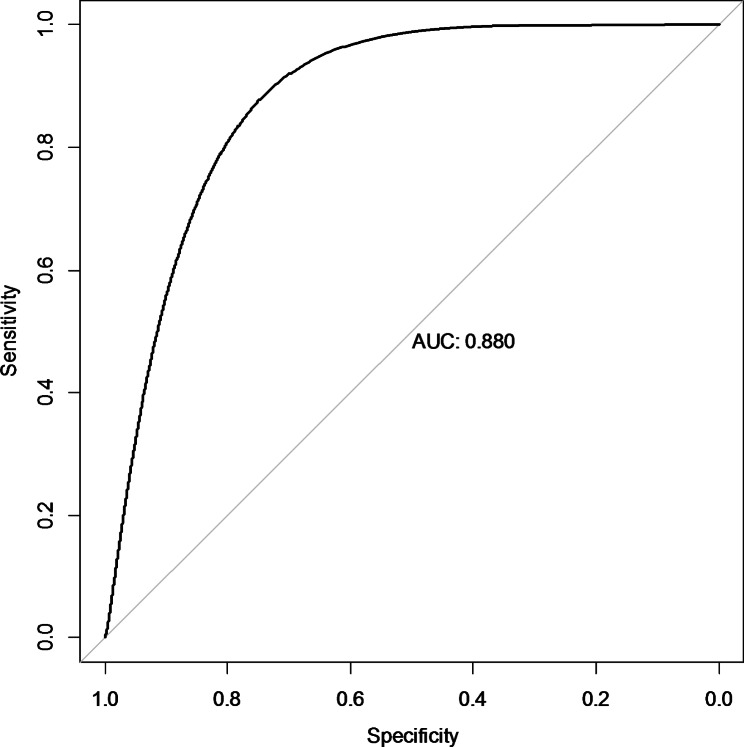
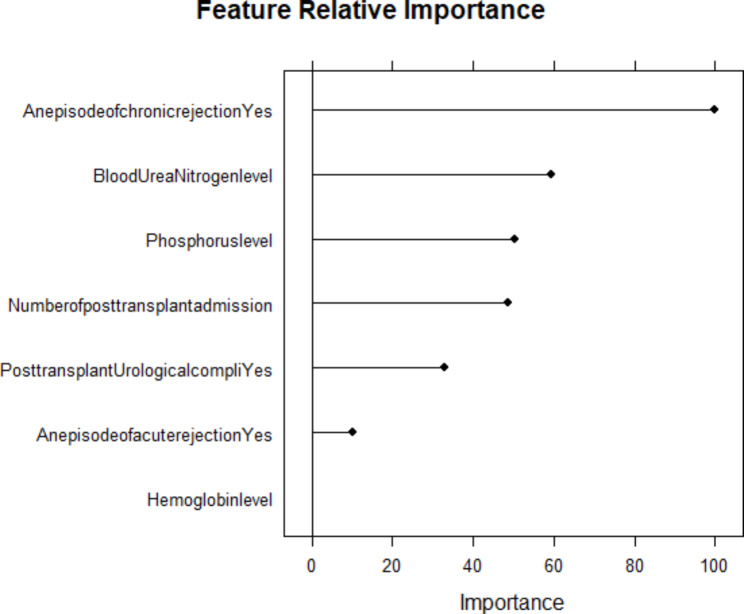
Results: A total of 278 completed cases were analyzed, with 21 graft failures and 3 events per predictor. Of these, 74.8% are male, and 25.2% are female, with a median age of 37. From the comparison of models at the individual level, the bagged tree and random forest have top and equal discrimination performance (AUC-ROC = 0.84). In contrast, the random forest has the best calibration performance (brier score = 0.045). Under testing the individual model as a meta-learner for stacking ensemble learning, the result of stochastic gradient boosting as a meta-learner has the top discrimination (AUC-ROC = 0.88) and calibration (brier score = 0.048) performance. Regarding feature importance, chronic rejection, blood urea nitrogen, number of post-transplant admissions, phosphorus level, acute rejection, and urological complications are the top predictors of graft failure.
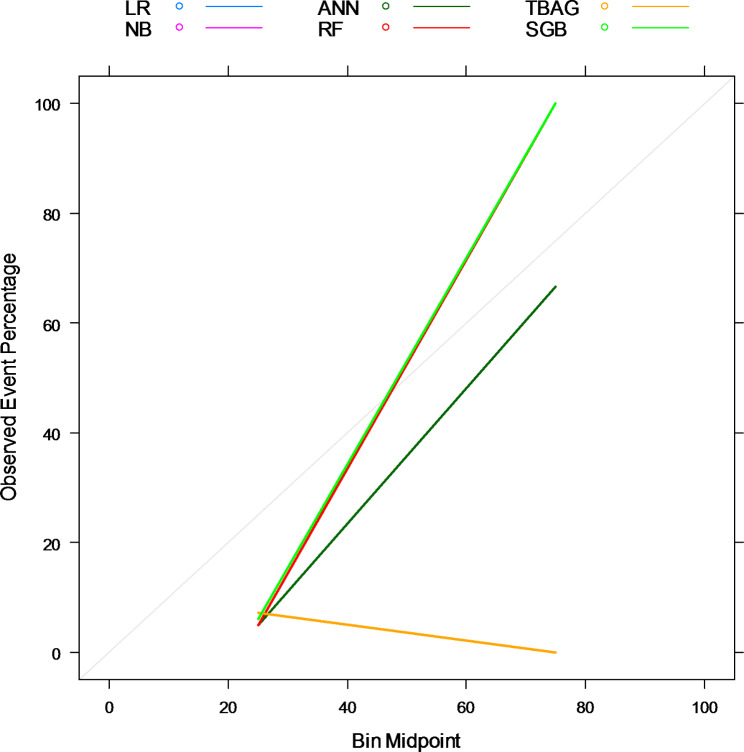
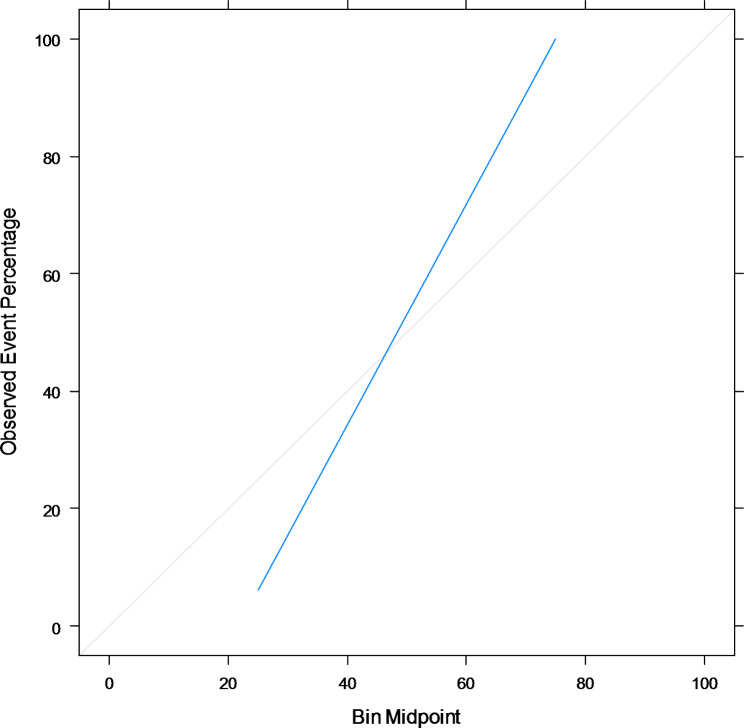
Conclusions: Bagging, boosting, and stacking, with probability calibration, are good choices for clinical risk predictions working on imbalanced data. The data-driven probability threshold is more beneficial than the natural threshold of 0.5 to improve the prediction result from imbalanced data. Integrating various techniques in a systematic framework is a smart strategy to improve prediction results from imbalanced data. It is recommended for clinical experts in kidney transplantation to use the final calibrated model as a decision support system to predict the risk of graft failure for individual patients.
Keywords: Graft failure; Imbalanced Data; Probabilistic models; Renal transplantation; Stacking ensemble; Tree-based ensembles.
© 2023. The Author(s).
Conflict of interest statement
Authors declared no conflict of interest between the author and institutions.
Figures
References
-
- Stamenic, D., Joint modelling of longitudinal and time-to-event data: analysis of predictive factors of graft outcomes in kidney transplant recipients. 2018, Université de Limoges.
-
- Hart, A., et al., OPTN/SRTR 2017 annual data report: kidney 2019. 19: p. 19–123. - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
