

Coherent category training enhances generalization in prototype-based categories
- PMID: 37227877
- PMCID: PMC11034797
- DOI: 10.1037/xlm0001243
Coherent category training enhances generalization in prototype-based categories
Abstract
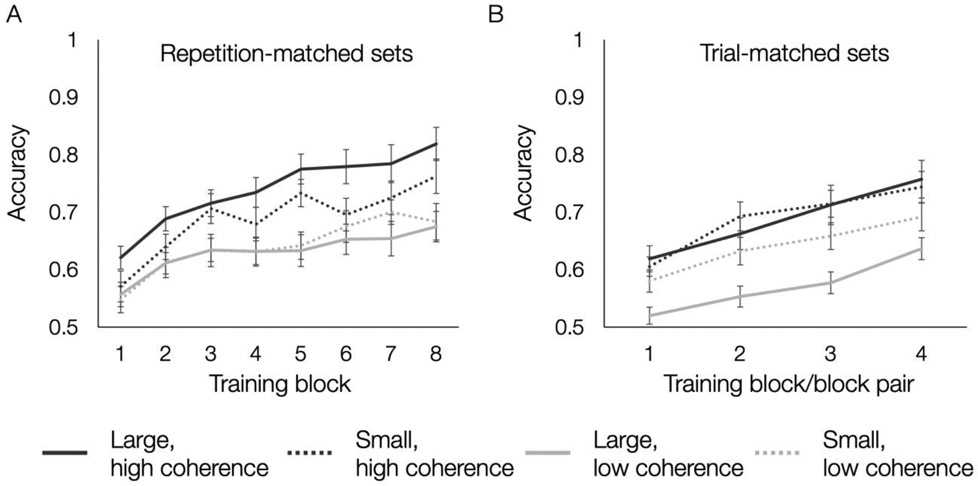
A major question for the study of learning and memory is how to tailor learning experiences to promote knowledge that generalizes to new situations. In two experiments, we used category learning as a representative domain to test two factors thought to influence the acquisition of conceptual knowledge: the number of training examples (set size) and the similarity of training examples to the category average (set coherence). Across participants, size and coherence of category training sets were varied in a fully crossed design. After training, participants demonstrated the breadth of their category knowledge by categorizing novel examples varying in their distance from the category center. Results showed better generalization following more coherent training sets, even when categorizing items furthest from the category center. Training set size had limited effects on performance. We also tested the types of representations underlying categorization decisions by fitting formal prototype and exemplar models. Prototype models posit abstract category representations based on the category's central tendency, whereas exemplar models posit that categories are represented by individual category members. In Experiment 1, low coherence training led to fewer participants relying on prototype representations, except when training length was extended. In Experiment 2, low coherence training led to chance performance and no clear representational strategy for nearly half of the participants. The results indicate that highlighting commonalities among exemplars during training facilitates learning and generalization and may also affect the types of concept representations that individuals form. (PsycInfo Database Record (c) 2023 APA, all rights reserved).
Figures








Similar articles
-
Training set coherence and set size effects on concept generalization and recognition.J Exp Psychol Learn Mem Cogn. 2020 Aug;46(8):1442-1464. doi: 10.1037/xlm0000824. Epub 2020 Feb 27. J Exp Psychol Learn Mem Cogn. 2020. PMID: 32105147 Free PMC article.
-
High coherence among training exemplars promotes broad generalization of face families.J Exp Psychol Learn Mem Cogn. 2025 Apr 7. doi: 10.1037/xlm0001478. Online ahead of print. J Exp Psychol Learn Mem Cogn. 2025. PMID: 40193499
-
Abstract Memory Representations in the Ventromedial Prefrontal Cortex and Hippocampus Support Concept Generalization.J Neurosci. 2018 Mar 7;38(10):2605-2614. doi: 10.1523/JNEUROSCI.2811-17.2018. Epub 2018 Feb 7. J Neurosci. 2018. PMID: 29437891 Free PMC article.
-
Model-guided search for optimal natural-science-category training exemplars: A work in progress.Psychon Bull Rev. 2019 Feb;26(1):48-76. doi: 10.3758/s13423-018-1508-8. Psychon Bull Rev. 2019. PMID: 29987765 Review.
-
Prototype-based category learning in autism: A review.Neurosci Biobehav Rev. 2021 Aug;127:607-618. doi: 10.1016/j.neubiorev.2021.05.016. Epub 2021 May 19. Neurosci Biobehav Rev. 2021. PMID: 34022278 Review.
Cited by
-
High variability orthographic training: Learning words in a logographic script through training with multiple typefaces.Psychon Bull Rev. 2025 Oct;32(5):2090-2103. doi: 10.3758/s13423-025-02646-0. Epub 2025 Mar 17. Psychon Bull Rev. 2025. PMID: 40097898 Free PMC article.
-
The influence of categorical stimuli on relational memory binding.Learn Mem. 2024 Oct 31;31(10-11):a054006. doi: 10.1101/lm.054006.124. Print 2024 Oct-Nov. Learn Mem. 2024. PMID: 39481887
References
-
- Ashby FG, & Maddox WT (1992). Complex decision rules in categorization: Contrasting novice and experienced performance. Journal of Experimental Psychology: Human Perception and Performance, 18(1), 50. 10.1037/0096-1523.18.1.50 - DOI
-
- Bowman CR, Iwashita T, & Zeithamova D (2022). The effects of age on prototype- and exemplar-based categorization. Psychology and Aging, 37(7), 800–815. 10.31234/OSF.IO/A3VUJ - DOI - PMC - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
