

Sequencing by avidity enables high accuracy with low reagent consumption
- PMID: 37231263
- PMCID: PMC10791576
- DOI: 10.1038/s41587-023-01750-7
Sequencing by avidity enables high accuracy with low reagent consumption
Abstract
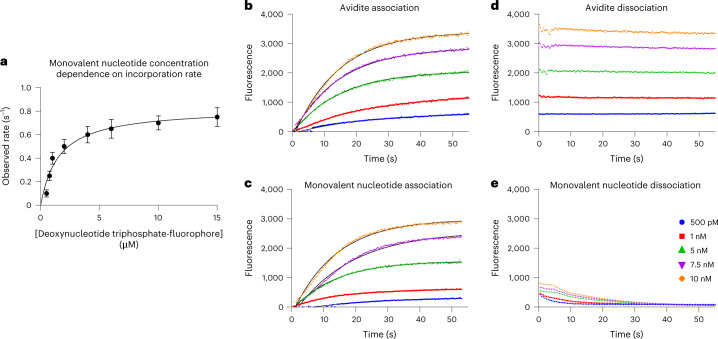
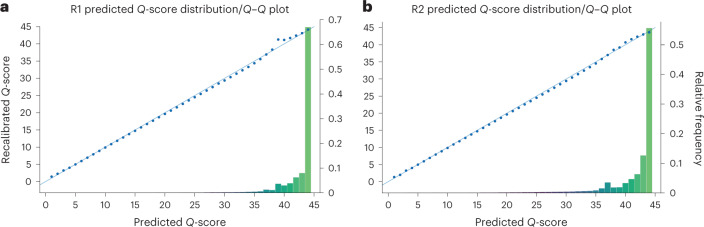
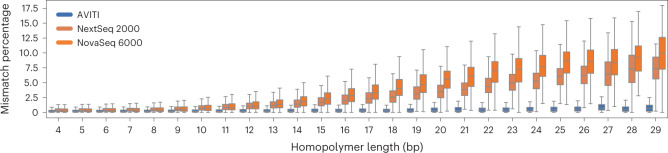
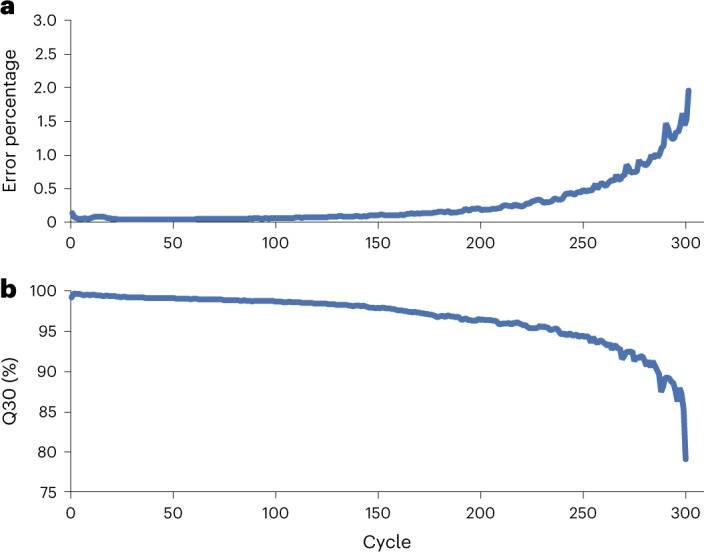
We present avidity sequencing, a sequencing chemistry that separately optimizes the processes of stepping along a DNA template and that of identifying each nucleotide within the template. Nucleotide identification uses multivalent nucleotide ligands on dye-labeled cores to form polymerase-polymer-nucleotide complexes bound to clonal copies of DNA targets. These polymer-nucleotide substrates, termed avidites, decrease the required concentration of reporting nucleotides from micromolar to nanomolar and yield negligible dissociation rates. Avidity sequencing achieves high accuracy, with 96.2% and 85.4% of base calls having an average of one error per 1,000 and 10,000 base pairs, respectively. We show that the average error rate of avidity sequencing remained stable following a long homopolymer.
© 2023. The Author(s).
Conflict of interest statement
All authors are current or former employees of Element Biosciences. All authors may hold stock options in the company.
Figures








References
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
