

DeepBreath-automated detection of respiratory pathology from lung auscultation in 572 pediatric outpatients across 5 countries
- PMID: 37268730
- PMCID: PMC10238513
- DOI: 10.1038/s41746-023-00838-3
DeepBreath-automated detection of respiratory pathology from lung auscultation in 572 pediatric outpatients across 5 countries
Abstract
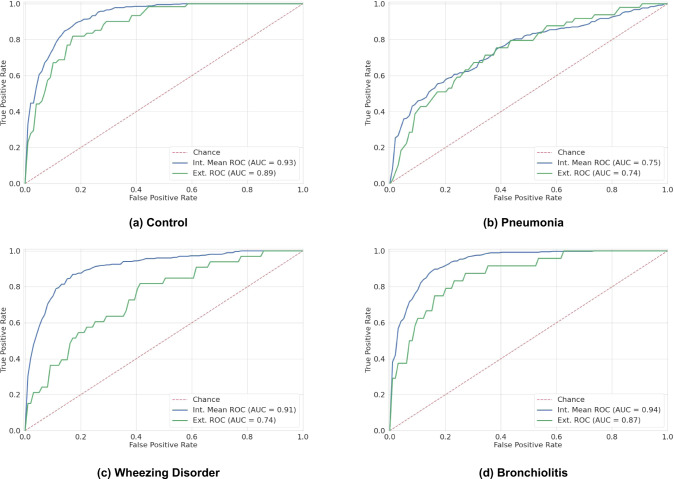
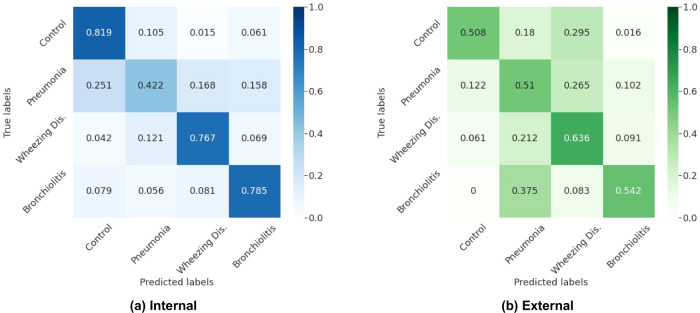
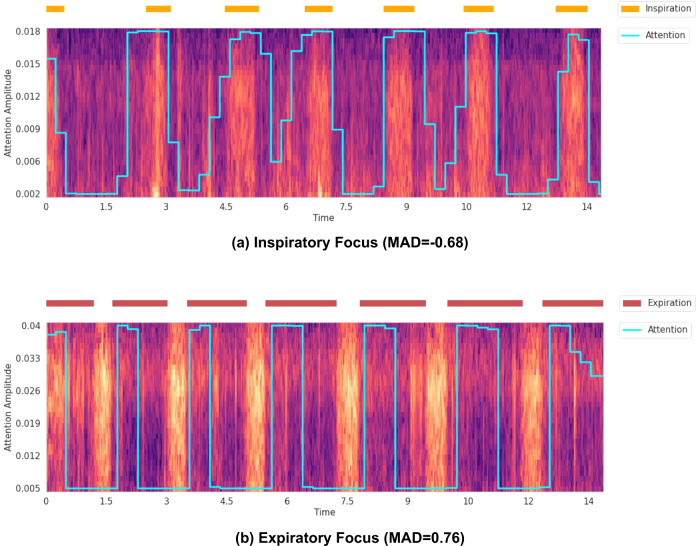
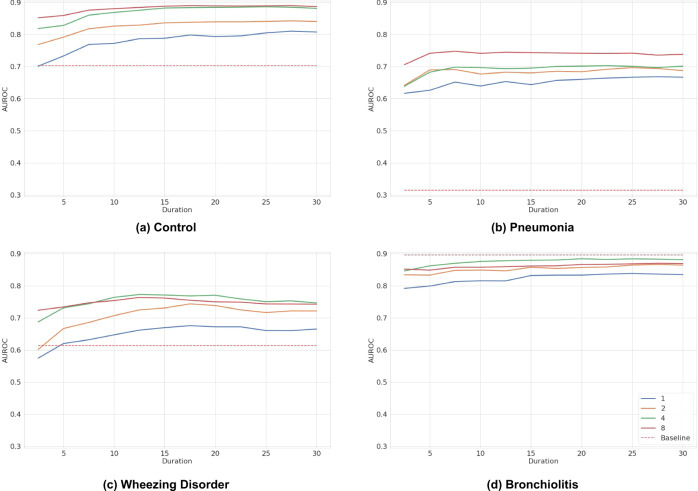
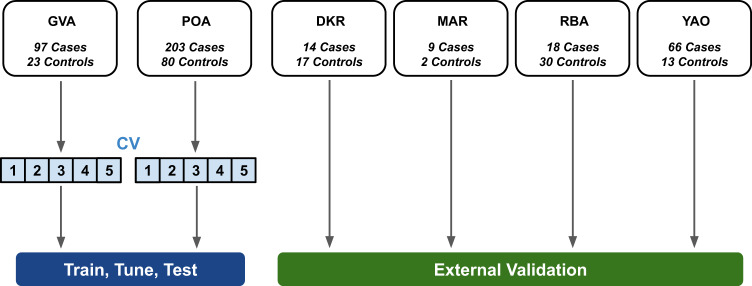
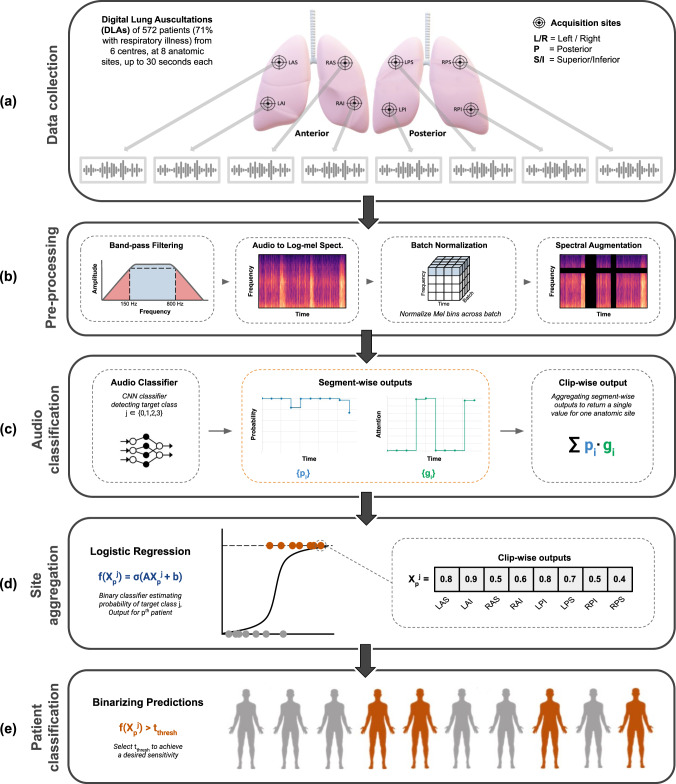
The interpretation of lung auscultation is highly subjective and relies on non-specific nomenclature. Computer-aided analysis has the potential to better standardize and automate evaluation. We used 35.9 hours of auscultation audio from 572 pediatric outpatients to develop DeepBreath : a deep learning model identifying the audible signatures of acute respiratory illness in children. It comprises a convolutional neural network followed by a logistic regression classifier, aggregating estimates on recordings from eight thoracic sites into a single prediction at the patient-level. Patients were either healthy controls (29%) or had one of three acute respiratory illnesses (71%) including pneumonia, wheezing disorders (bronchitis/asthma), and bronchiolitis). To ensure objective estimates on model generalisability, DeepBreath is trained on patients from two countries (Switzerland, Brazil), and results are reported on an internal 5-fold cross-validation as well as externally validated (extval) on three other countries (Senegal, Cameroon, Morocco). DeepBreath differentiated healthy and pathological breathing with an Area Under the Receiver-Operator Characteristic (AUROC) of 0.93 (standard deviation [SD] ± 0.01 on internal validation). Similarly promising results were obtained for pneumonia (AUROC 0.75 ± 0.10), wheezing disorders (AUROC 0.91 ± 0.03), and bronchiolitis (AUROC 0.94 ± 0.02). Extval AUROCs were 0.89, 0.74, 0.74 and 0.87 respectively. All either matched or were significant improvements on a clinical baseline model using age and respiratory rate. Temporal attention showed clear alignment between model prediction and independently annotated respiratory cycles, providing evidence that DeepBreath extracts physiologically meaningful representations. DeepBreath provides a framework for interpretable deep learning to identify the objective audio signatures of respiratory pathology.
© 2023. The Author(s).
Conflict of interest statement
A.Ge. and A.P. intend to develop a smart stethoscope ‘Onescope’, which may be commercialised. All other authors declare no Competing Financial or Non-Financial Interests.
Figures

References
-
- Abdel-Hamid O, et al. Convolutional neural networks for speech recognition. IEEE/ACM Trans Audio Speech, Language Process. 2014;22:1533–1545. doi: 10.1109/TASLP.2014.2339736. - DOI
-
- Kong Q, et al. PANNs: Large-scale pretrained audio neural networks for audio pattern recognition. IEEE/ACM Transac Audio Speech Language Processing. 2020;28:2880–2894. doi: 10.1109/TASLP.2020.3030497. - DOI
-
- Hershey, S. et al. Cnn architectures for large-scale audio classification. In 2017 ieee international conference on acoustics, speech and signal processing (icassp), 131–135 (IEEE, 2017).
