

ChatGPT's quiz skills in different otolaryngology subspecialties: an analysis of 2576 single-choice and multiple-choice board certification preparation questions
- PMID: 37285018
- PMCID: PMC10382366
- DOI: 10.1007/s00405-023-08051-4
ChatGPT's quiz skills in different otolaryngology subspecialties: an analysis of 2576 single-choice and multiple-choice board certification preparation questions
Abstract
Purpose: With the increasing adoption of artificial intelligence (AI) in various domains, including healthcare, there is growing acceptance and interest in consulting AI models to provide medical information and advice. This study aimed to evaluate the accuracy of ChatGPT's responses to practice quiz questions designed for otolaryngology board certification and decipher potential performance disparities across different otolaryngology subspecialties.
Methods: A dataset covering 15 otolaryngology subspecialties was collected from an online learning platform funded by the German Society of Oto-Rhino-Laryngology, Head and Neck Surgery, designed for board certification examination preparation. These questions were entered into ChatGPT, with its responses being analyzed for accuracy and variance in performance.
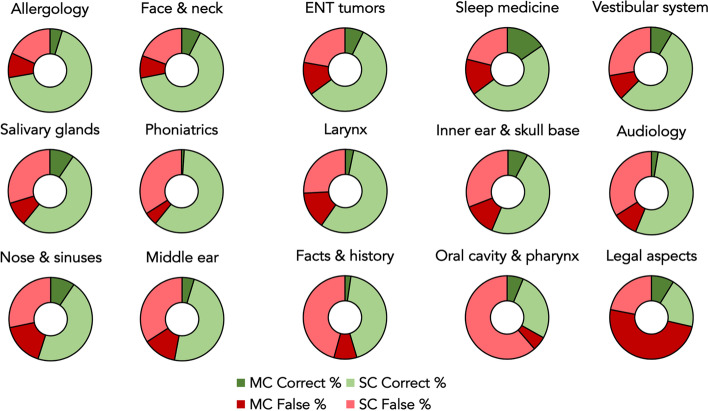
Results: The dataset included 2576 questions (479 multiple-choice and 2097 single-choice), of which 57% (n = 1475) were answered correctly by ChatGPT. An in-depth analysis of question style revealed that single-choice questions were associated with a significantly higher rate (p < 0.001) of correct responses (n = 1313; 63%) compared to multiple-choice questions (n = 162; 34%). Stratified by question categories, ChatGPT yielded the highest rate of correct responses (n = 151; 72%) in the field of allergology, whereas 7 out of 10 questions (n = 65; 71%) on legal otolaryngology aspects were answered incorrectly.
Conclusion: The study reveals ChatGPT's potential as a supplementary tool for otolaryngology board certification preparation. However, its propensity for errors in certain otolaryngology areas calls for further refinement. Future research should address these limitations to improve ChatGPT's educational use. An approach, with expert collaboration, is recommended for the reliable and accurate integration of such AI models.
Keywords: AI; Artificial intelligence; ChatGPT; Multiple-choice; Otolaryngology quiz; Single-choice.
© 2023. The Author(s).
Conflict of interest statement
The authors have no relevant financial or non-financial interests to disclose. Jan-Christoffer Lüers, M.D., Ph.D. is the developer and owner of the online learning platform.
Figures


Comment in
-
Examining otolaryngologists' attitudes towards large language models (LLMs) such as ChatGPT: a comprehensive deep learning analysis.Eur Arch Otorhinolaryngol. 2024 Feb;281(2):1061-1063. doi: 10.1007/s00405-023-08325-x. Epub 2023 Nov 13. Eur Arch Otorhinolaryngol. 2024. PMID: 37955694 No abstract available.
References
MeSH terms
LinkOut - more resources
Full Text Sources
