

Health system-scale language models are all-purpose prediction engines
- PMID: 37286606
- PMCID: PMC10338337
- DOI: 10.1038/s41586-023-06160-y
Health system-scale language models are all-purpose prediction engines
Abstract
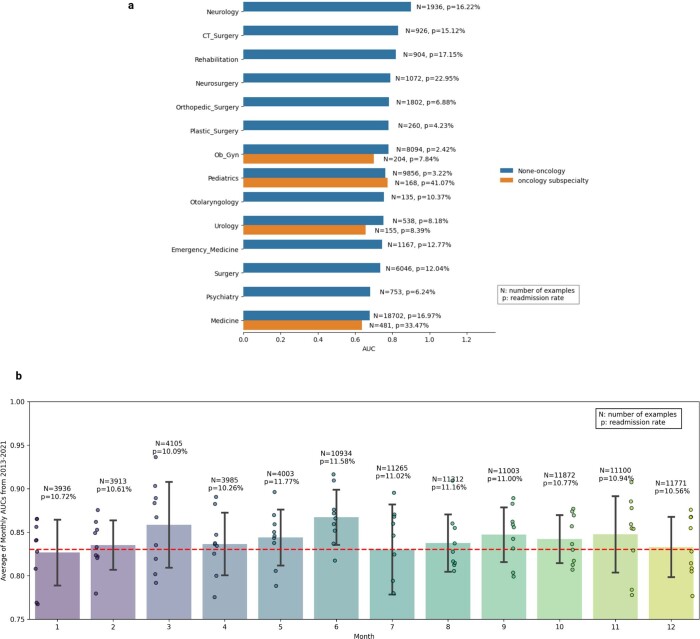
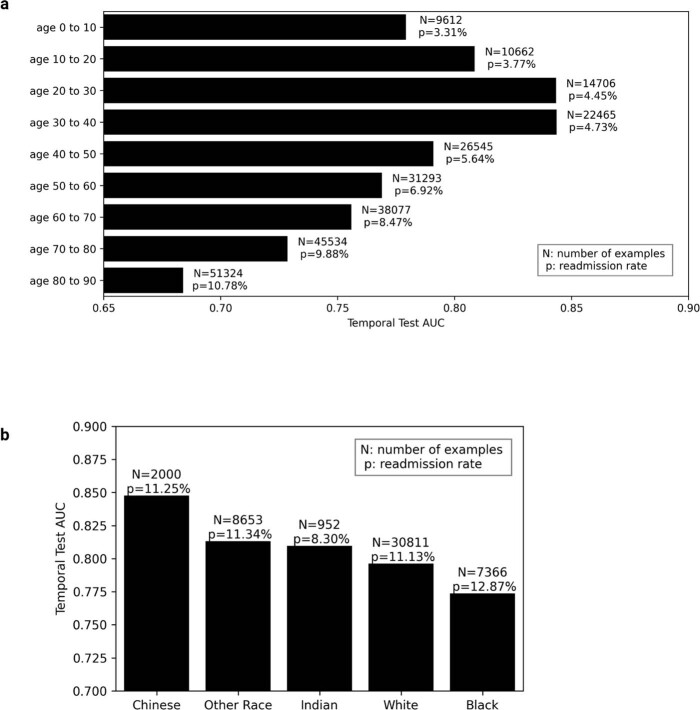
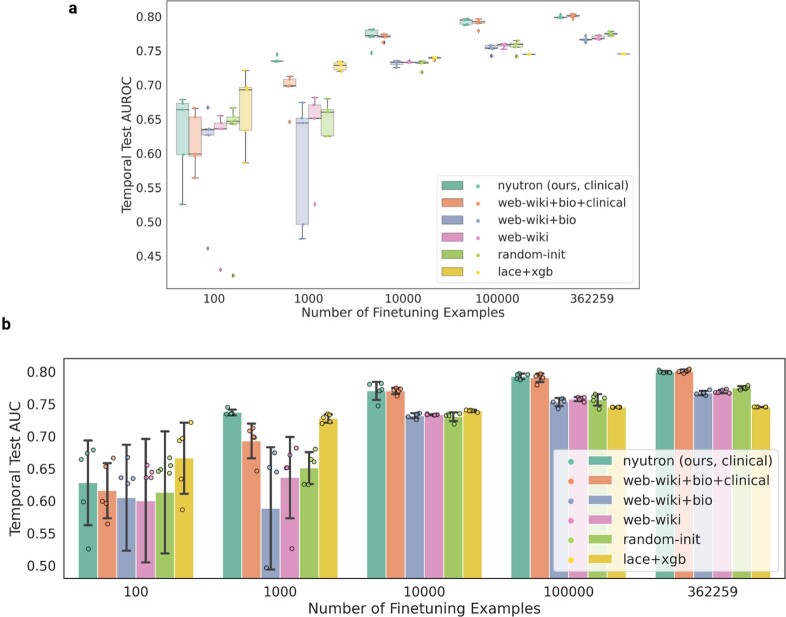
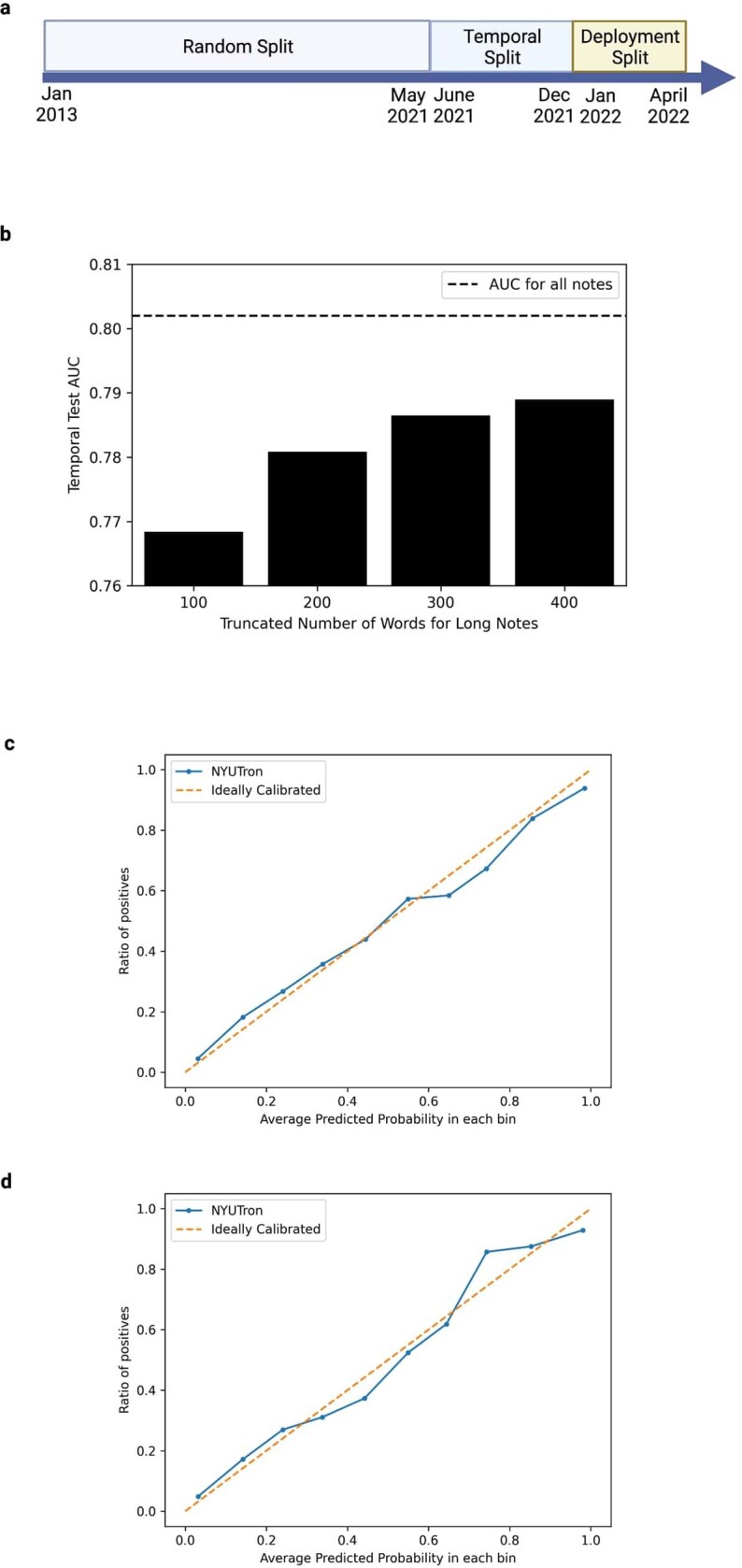
Physicians make critical time-constrained decisions every day. Clinical predictive models can help physicians and administrators make decisions by forecasting clinical and operational events. Existing structured data-based clinical predictive models have limited use in everyday practice owing to complexity in data processing, as well as model development and deployment1-3. Here we show that unstructured clinical notes from the electronic health record can enable the training of clinical language models, which can be used as all-purpose clinical predictive engines with low-resistance development and deployment. Our approach leverages recent advances in natural language processing4,5 to train a large language model for medical language (NYUTron) and subsequently fine-tune it across a wide range of clinical and operational predictive tasks. We evaluated our approach within our health system for five such tasks: 30-day all-cause readmission prediction, in-hospital mortality prediction, comorbidity index prediction, length of stay prediction, and insurance denial prediction. We show that NYUTron has an area under the curve (AUC) of 78.7-94.9%, with an improvement of 5.36-14.7% in the AUC compared with traditional models. We additionally demonstrate the benefits of pretraining with clinical text, the potential for increasing generalizability to different sites through fine-tuning and the full deployment of our system in a prospective, single-arm trial. These results show the potential for using clinical language models in medicine to read alongside physicians and provide guidance at the point of care.
© 2023. The Author(s).
Conflict of interest statement
E.K.O. reports consulting with Sofinnova and Google, income from Merck & Co. and Mirati Therapeutics, and equity in Artisight. N.P.N., M.F. and A.B.C. are employed by NVIDIA. D.K. reports consulting with Elekta. K.C. is employed by Prescient Design, a Genentech accelerator, a subsidiary of Roche. There are no other potential conflicts of interest. The work presented herein was performed exclusively within the NYU Langone Health System.
Figures
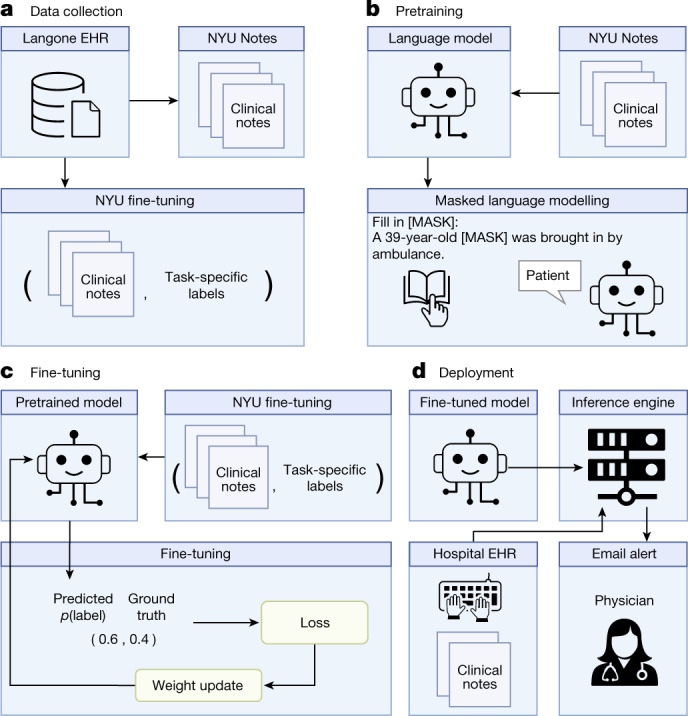
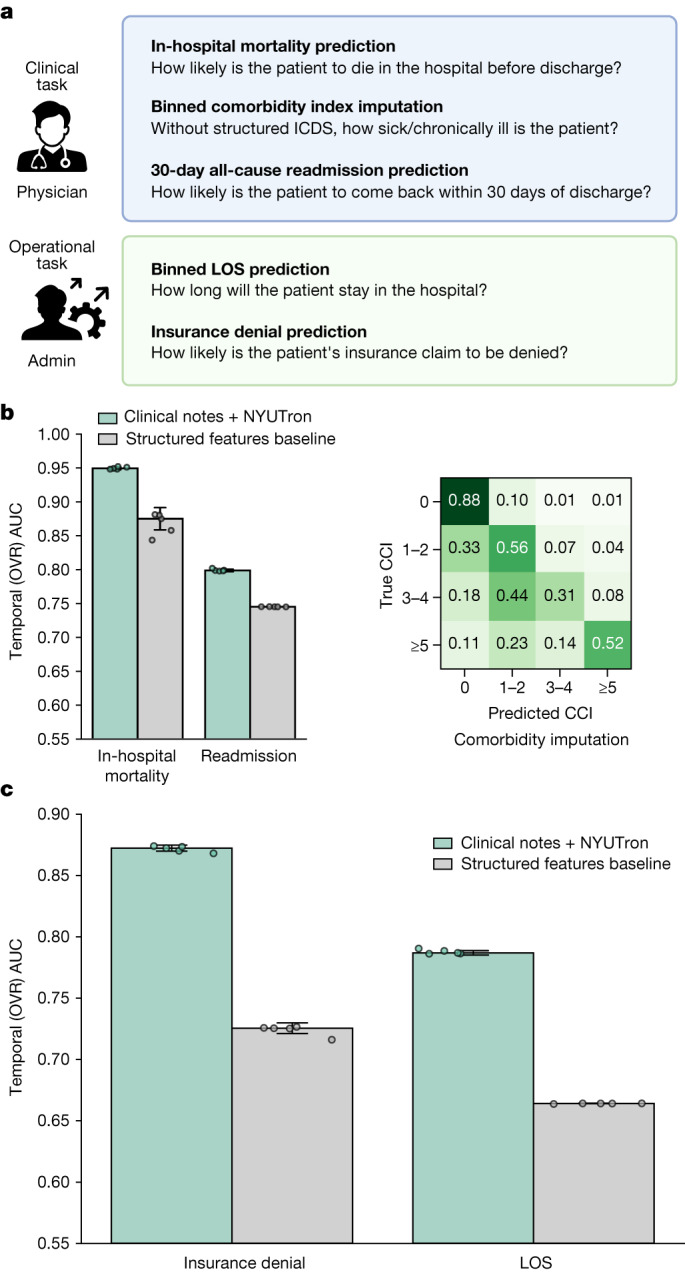
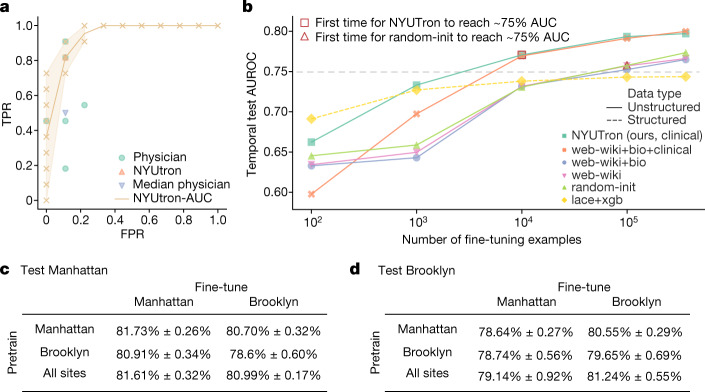
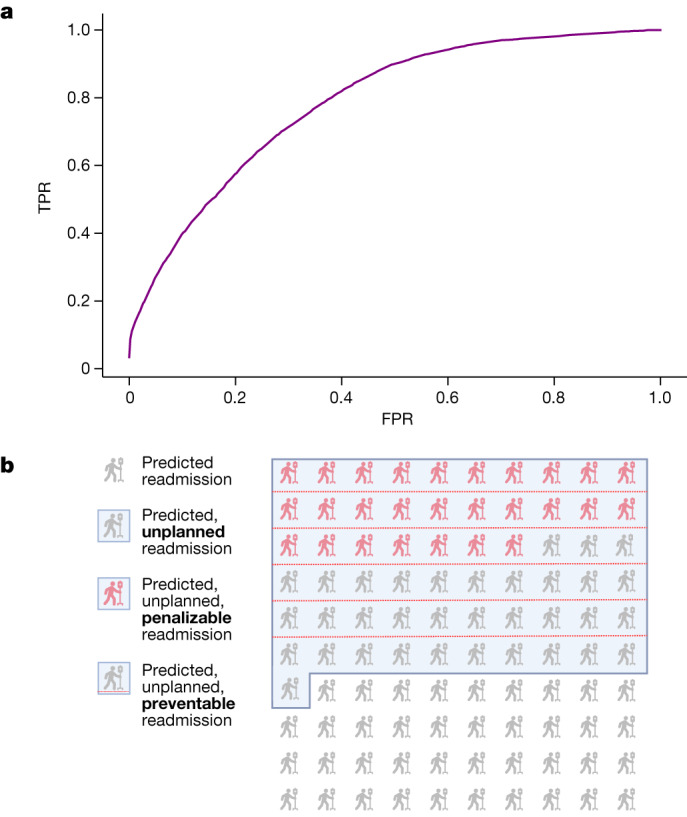
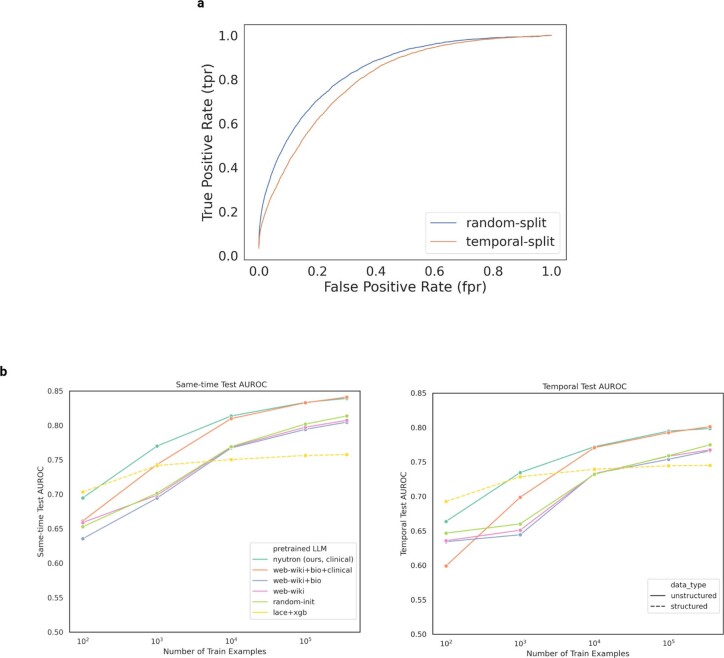
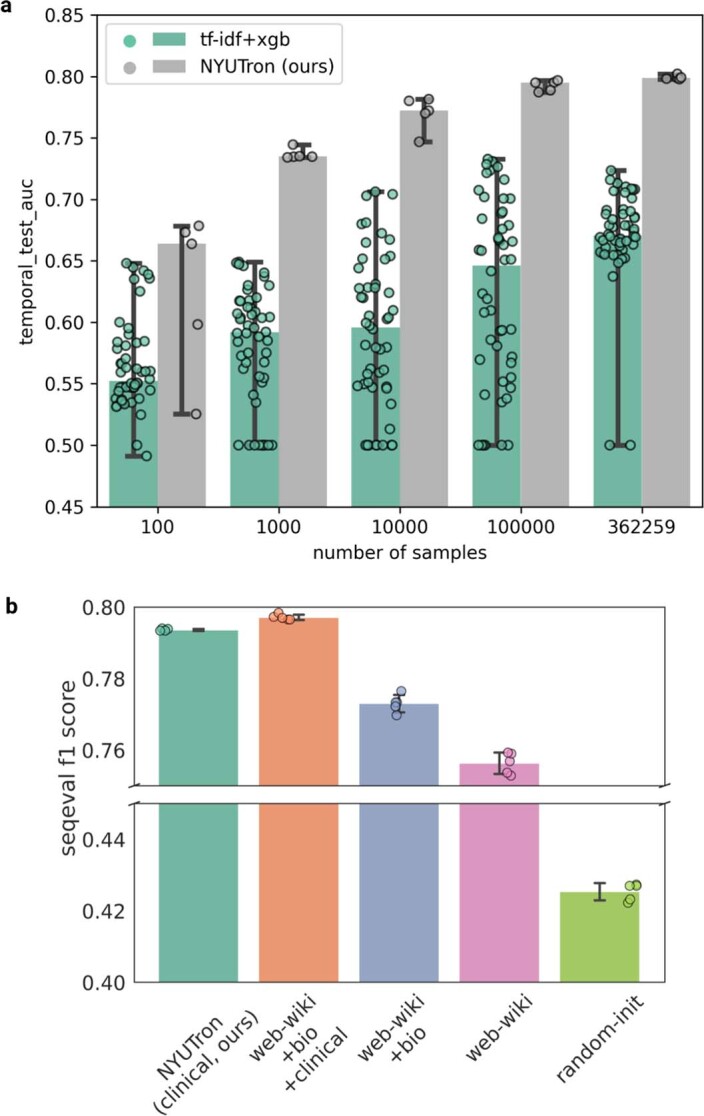
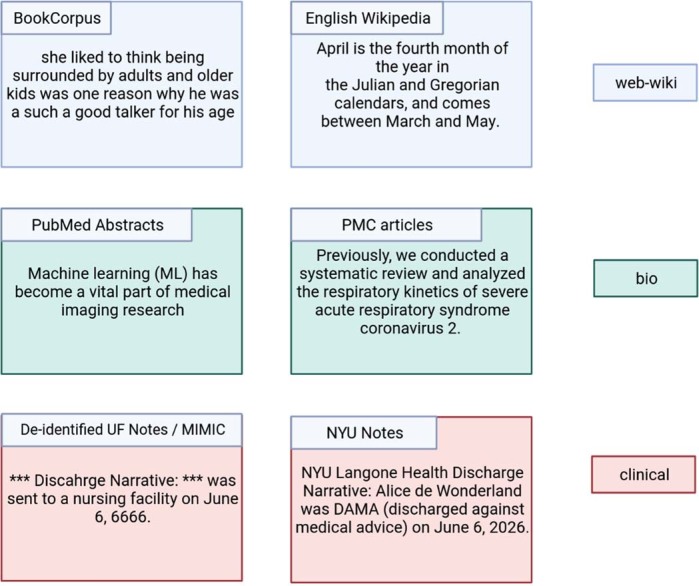
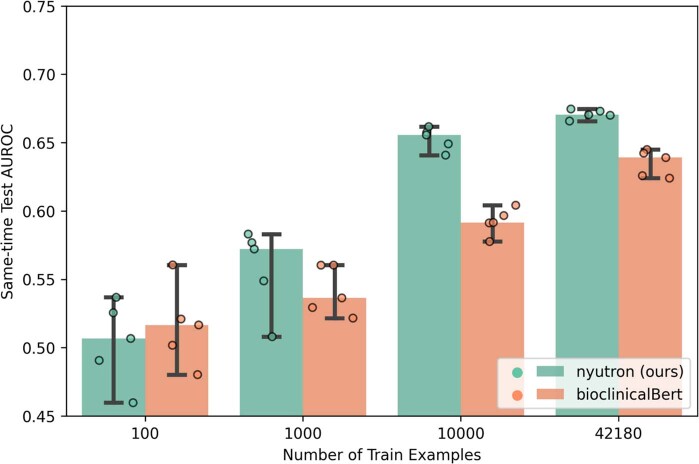
References
-
- Roberts M, et al. Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans. Nat. Mach. Intel. 2021;3:199–217. doi: 10.1038/s42256-021-00307-0. - DOI
-
- Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. in Proc. 2019 NAACL: Human Language Technologies (eds Burstein, J., Doran, C. & Solorio, T.) 4171–4186 (Association for Computational Linguistics, 2019).
-
- Brown, T. B. et al. Language models are few-shot learners. in Proc. NeurIPS (eds Wallach, H. et al.) 1877–1901 (Neural Information Processing Systems, 2020).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
