

The autocorrelated Bayesian sampler: A rational process for probability judgments, estimates, confidence intervals, choices, confidence judgments, and response times
- PMID: 37289507
- PMCID: PMC11115360
- DOI: 10.1037/rev0000427
The autocorrelated Bayesian sampler: A rational process for probability judgments, estimates, confidence intervals, choices, confidence judgments, and response times
Abstract
Normative models of decision-making that optimally transform noisy (sensory) information into categorical decisions qualitatively mismatch human behavior. Indeed, leading computational models have only achieved high empirical corroboration by adding task-specific assumptions that deviate from normative principles. In response, we offer a Bayesian approach that implicitly produces a posterior distribution of possible answers (hypotheses) in response to sensory information. But we assume that the brain has no direct access to this posterior, but can only sample hypotheses according to their posterior probabilities. Accordingly, we argue that the primary problem of normative concern in decision-making is integrating stochastic hypotheses, rather than stochastic sensory information, to make categorical decisions. This implies that human response variability arises mainly from posterior sampling rather than sensory noise. Because human hypothesis generation is serially correlated, hypothesis samples will be autocorrelated. Guided by this new problem formulation, we develop a new process, the Autocorrelated Bayesian Sampler (ABS), which grounds autocorrelated hypothesis generation in a sophisticated sampling algorithm. The ABS provides a single mechanism that qualitatively explains many empirical effects of probability judgments, estimates, confidence intervals, choice, confidence judgments, response times, and their relationships. Our analysis demonstrates the unifying power of a perspective shift in the exploration of normative models. It also exemplifies the proposal that the "Bayesian brain" operates using samples not probabilities, and that variability in human behavior may primarily reflect computational rather than sensory noise. (PsycInfo Database Record (c) 2024 APA, all rights reserved).
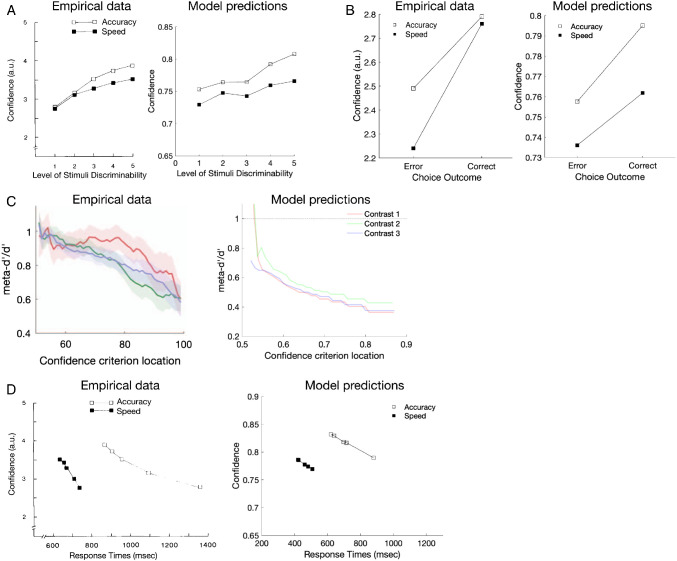
Figures















References
-
- Abbott J. T., & Griffiths T. L. (2011). Exploring the influence of particle filter parameters on order effects in causal learning. In Carlson L., Hoelscher C., & Shipley T. F. (Eds.), Proceedings of the annual meeting of the cognitive science society (pp. 2950–2955). Cognitive Science Society.
-
- Anderson J. R. (1991). The adaptive nature of human categorization. Psychological Review, 98(3), 409–429. 10.1037/0033-295X.98.3.409 - DOI
-
- Andrieu C., De Freitas N., Doucet A., & Jordan M. I. (2003). An introduction to MCMC for machine learning. Machine Learning, 50(1), 5–43. 10.1023/A:1020281327116 - DOI
-
- Aragones E., Gilboa I., Postlewaite A., & Schmeidler D. (2005). Fact-free learning. The American Economic Review, 95(5), 1355–1368. 10.1257/000282805775014308 - DOI
