

Data Science Methods and Tools for Industry 4.0: A Systematic Literature Review and Taxonomy
- PMID: 37299736
- PMCID: PMC10255695
- DOI: 10.3390/s23115010
Data Science Methods and Tools for Industry 4.0: A Systematic Literature Review and Taxonomy
Abstract
The Fourth Industrial Revolution, also named Industry 4.0, is leveraging several modern computing fields. Industry 4.0 comprises automated tasks in manufacturing facilities, which generate massive quantities of data through sensors. These data contribute to the interpretation of industrial operations in favor of managerial and technical decision-making. Data science supports this interpretation due to extensive technological artifacts, particularly data processing methods and software tools. In this regard, the present article proposes a systematic literature review of these methods and tools employed in distinct industrial segments, considering an investigation of different time series levels and data quality. The systematic methodology initially approached the filtering of 10,456 articles from five academic databases, 103 being selected for the corpus. Thereby, the study answered three general, two focused, and two statistical research questions to shape the findings. As a result, this research found 16 industrial segments, 168 data science methods, and 95 software tools explored by studies from the literature. Furthermore, the research highlighted the employment of diverse neural network subvariations and missing details in the data composition. Finally, this article organized these results in a taxonomic approach to synthesize a state-of-the-art representation and visualization, favoring future research studies in the field.
Keywords: Industry 4.0; data science; literature review; machine learning; taxonomy.
Conflict of interest statement
The authors declare no conflict of interest.
Figures






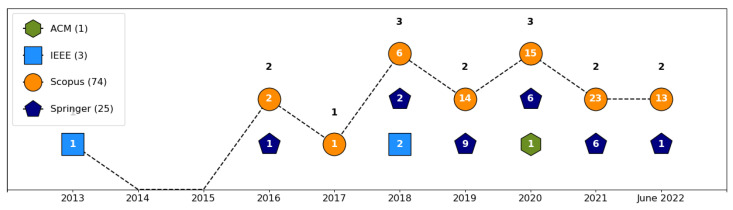
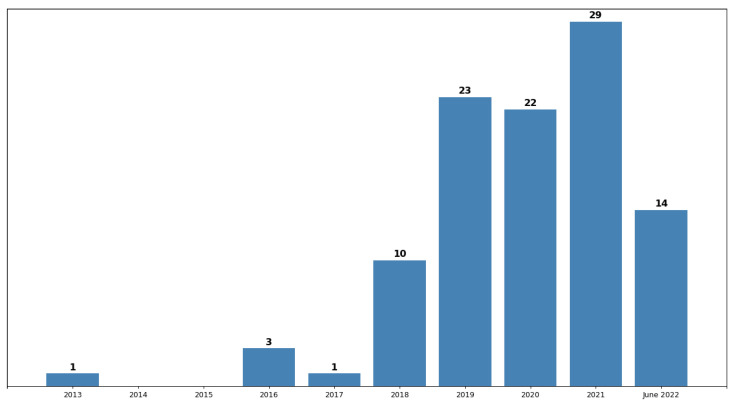





References
-
- Kagermann H., Wahlster W., Helbig J. Recommendations for Implementing the Strategic Initiative INDUSTRIE 4.0. Acatech—National Academy of Science and Engineering, Forschungsunion; Berlin, Germany: 2013. Technical Report.
-
- Lu Y. Industry 4.0: A survey on technologies, applications and open research issues. J. Ind. Inf. Integr. 2017;6:1–10. doi: 10.1016/j.jii.2017.04.005. - DOI
-
- Liao Y., Deschamps F., Loures E.d.F.R., Ramos L.F.P. Past, present and future of Industry 4.0—A systematic literature review and research agenda proposal. Int. J. Prod. Res. 2017;55:3609–3629. doi: 10.1080/00207543.2017.1308576. - DOI
-
- Bavaresco R., Arruda H., Rocha E., Barbosa J., Li G.P. Internet of Things and occupational well-being in industry 4.0: A systematic mapping study and taxonomy. Comput. Ind. Eng. 2021;161:107670. doi: 10.1016/j.cie.2021.107670. - DOI
-
- Davenport T.H., Patil D.J. Data Scientist: The Sexiest Job of the 21st Century. Harv. Bus. Rev. 2012;90:70–76. - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
