

Evaluating the limits of AI in medical specialisation: ChatGPT's performance on the UK Neurology Specialty Certificate Examination
- PMID: 37337531
- PMCID: PMC10277081
- DOI: 10.1136/bmjno-2023-000451
Evaluating the limits of AI in medical specialisation: ChatGPT's performance on the UK Neurology Specialty Certificate Examination
Abstract
Background: Large language models such as ChatGPT have demonstrated potential as innovative tools for medical education and practice, with studies showing their ability to perform at or near the passing threshold in general medical examinations and standardised admission tests. However, no studies have assessed their performance in the UK medical education context, particularly at a specialty level, and specifically in the field of neurology and neuroscience.
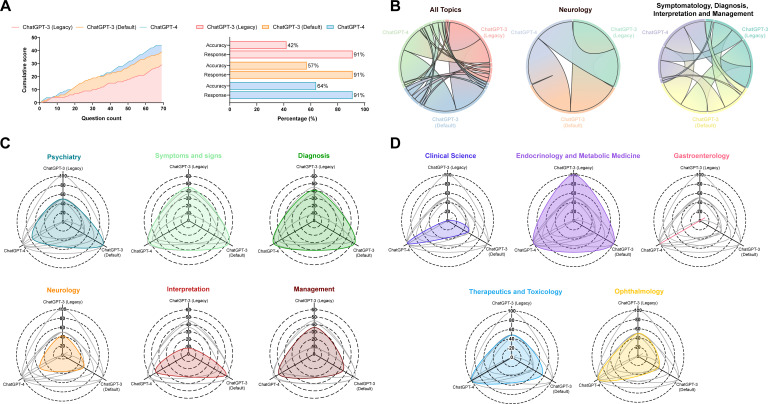
Methods: We evaluated the performance of ChatGPT in higher specialty training for neurology and neuroscience using 69 questions from the Pool-Specialty Certificate Examination (SCE) Neurology Web Questions bank. The dataset primarily focused on neurology (80%). The questions spanned subtopics such as symptoms and signs, diagnosis, interpretation and management with some questions addressing specific patient populations. The performance of ChatGPT 3.5 Legacy, ChatGPT 3.5 Default and ChatGPT-4 models was evaluated and compared.
Results: ChatGPT 3.5 Legacy and ChatGPT 3.5 Default displayed overall accuracies of 42% and 57%, respectively, falling short of the passing threshold of 58% for the 2022 SCE neurology examination. ChatGPT-4, on the other hand, achieved the highest accuracy of 64%, surpassing the passing threshold and outperforming its predecessors across disciplines and subtopics.
Conclusions: The advancements in ChatGPT-4's performance compared with its predecessors demonstrate the potential for artificial intelligence (AI) models in specialised medical education and practice. However, our findings also highlight the need for ongoing development and collaboration between AI developers and medical experts to ensure the models' relevance and reliability in the rapidly evolving field of medicine.
Keywords: clinical neurology; health policy & practice; medicine.
© Author(s) (or their employer(s)) 2023. Re-use permitted under CC BY-NC. No commercial re-use. See rights and permissions. Published by BMJ.
Conflict of interest statement
Competing interests: None declared.
Figures
References
-
- Kevin S. Microsoft teams up with OpenAi to exclusively license GPT-3 language model. n.d. Available: https://blogs.microsoft.com/blog/2020/09/22/microsoft-teams-up-with-open...
-
- Nagarhalli TP, Vaze V, Rana NK. A review of current trends in the development of Chatbot systems. 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS); Coimbatore, India.2020:706–10 10.1109/ICACCS48705.2020.9074420 - DOI
LinkOut - more resources
Full Text Sources