

A critical spotlight on the paradigms of FFPE-DNA sequencing
- PMID: 37351572
- PMCID: PMC10415133
- DOI: 10.1093/nar/gkad519
A critical spotlight on the paradigms of FFPE-DNA sequencing
Abstract
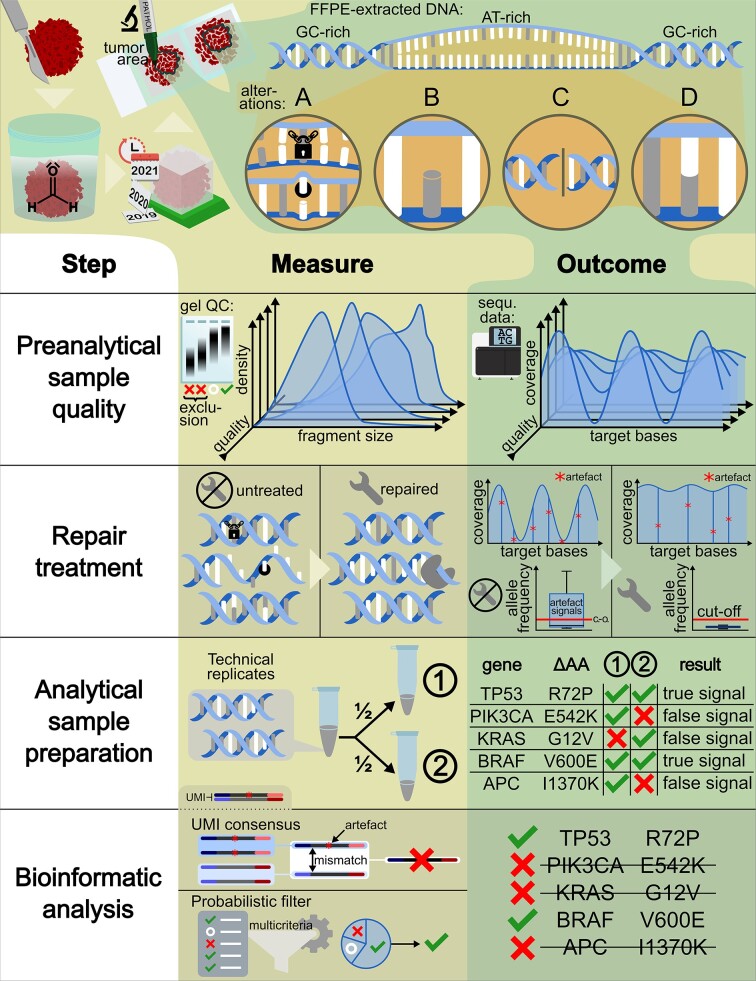
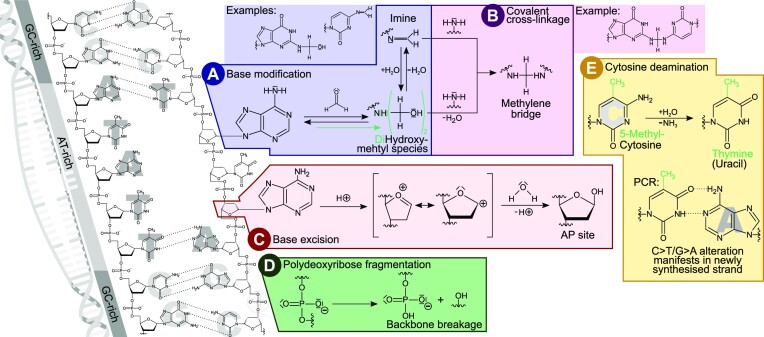
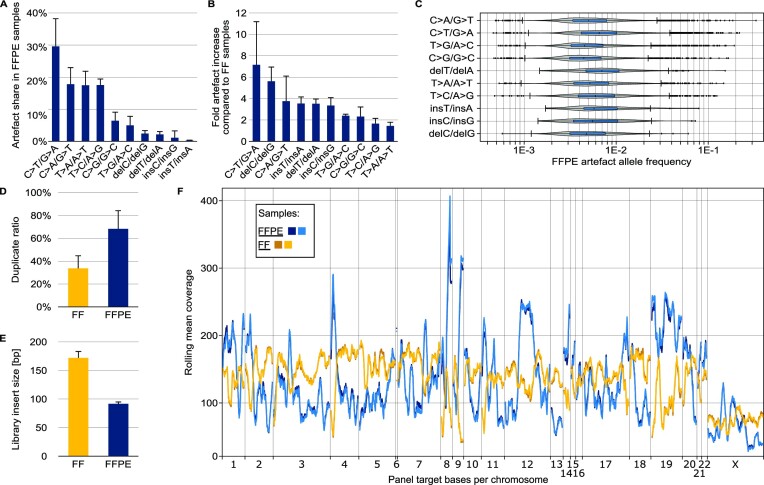
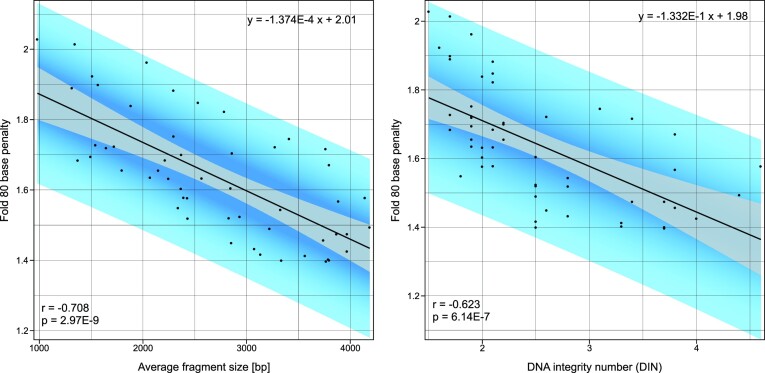
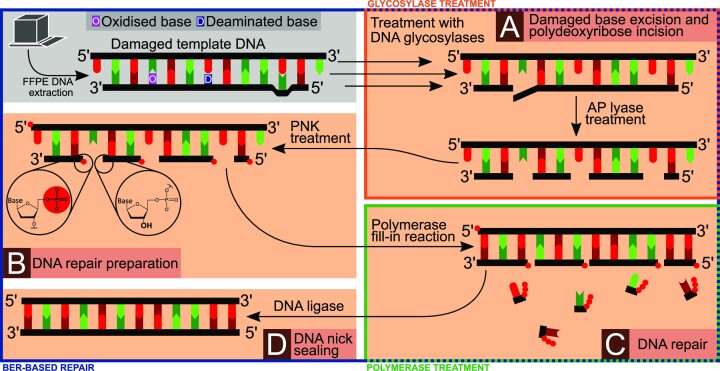
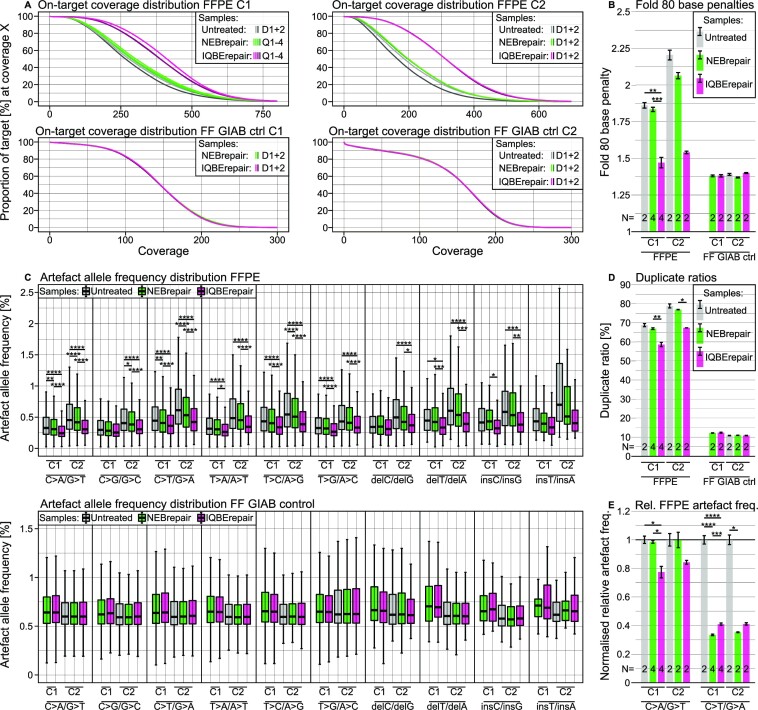
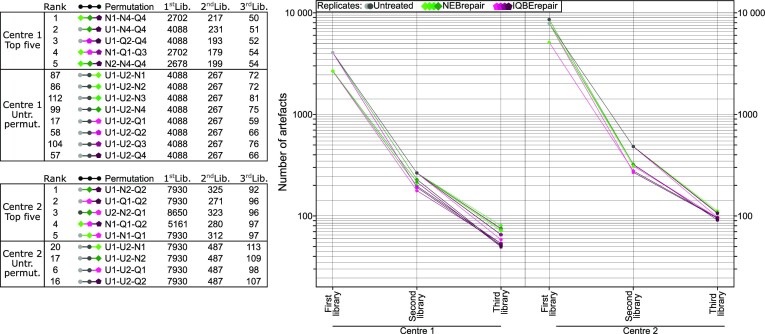
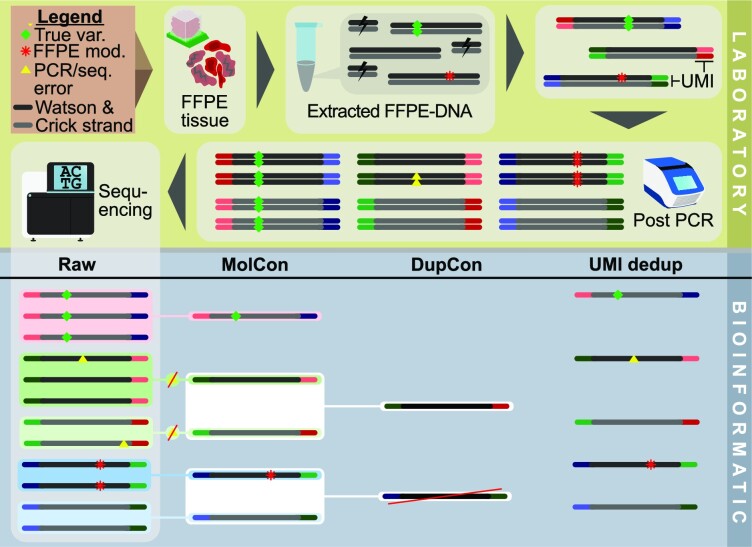
In the late 19th century, formalin fixation with paraffin-embedding (FFPE) of tissues was developed as a fixation and conservation method and is still used to this day in routine clinical and pathological practice. The implementation of state-of-the-art nucleic acid sequencing technologies has sparked much interest for using historical FFPE samples stored in biobanks as they hold promise in extracting new information from these valuable samples. However, formalin fixation chemically modifies DNA, which potentially leads to incorrect sequences or misinterpretations in downstream processing and data analysis. Many publications have concentrated on one type of DNA damage, but few have addressed the complete spectrum of FFPE-DNA damage. Here, we review mitigation strategies in (I) pre-analytical sample quality control, (II) DNA repair treatments, (III) analytical sample preparation and (IV) bioinformatic analysis of FFPE-DNA. We then provide recommendations that are tested and illustrated with DNA from 13-year-old liver specimens, one FFPE preserved and one fresh frozen, applying target-enriched sequencing. Thus, we show how DNA damage can be compensated, even when using low quantities (50 ng) of fragmented FFPE-DNA (DNA integrity number 2.0) that cannot be amplified well (Q129 bp/Q41 bp = 5%). Finally, we provide a checklist called 'ERROR-FFPE-DNA' that summarises recommendations for the minimal information in publications required for assessing fitness-for-purpose and inter-study comparison when using FFPE samples.
© The Author(s) 2023. Published by Oxford University Press on behalf of Nucleic Acids Research.
Figures
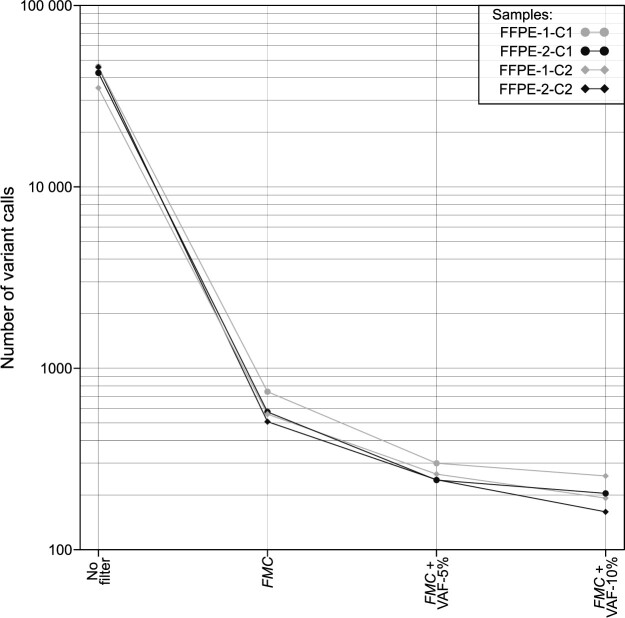
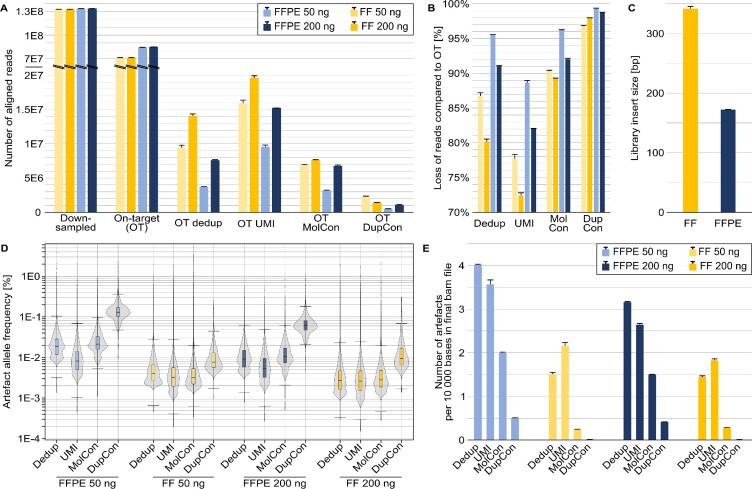
References
-
- Blum F. Notiz über die Anwendung des Formaldehyds (Formol) als Härtungs-und Konservierungsmittel. Anat. Anz. 1894; 9:229–231.
-
- Lewis F., Maughan N., Smith V., Hillan K., Quirke P.. Unlocking the archive–gene expression in paraffin-embedded tissue. J. Pathol. 2001; 195:66–71. - PubMed
-
- Arreaza G., Qiu P., Pang L., Albright A., Hong L.Z., Marton M.J., Levitan D. Pre-analytical considerations for successful next-generation sequencing (NGS): challenges and opportunities for formalin-fixed and paraffin-embedded tumor tissue (FFPE) samples. Int. J. Mol. Sci. 2016; 17:1579. - PMC - PubMed
-
- Ferlay J., Colombet M., Soerjomataram I., Mathers C., Parkin D.M., Pineros M., Znaor A., Bray F.. Estimating the global cancer incidence and mortality in 2018: GLOBOCAN sources and methods. Int. J. Cancer. 2019; 144:1941–1953. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
