

Rapidly adaptable automated interpretation of point-of-care COVID-19 diagnostics
- PMID: 37353603
- PMCID: PMC10290128
- DOI: 10.1038/s43856-023-00312-x
Rapidly adaptable automated interpretation of point-of-care COVID-19 diagnostics
Abstract
Background: Point-of-care diagnostic devices, such as lateral-flow assays, are becoming widely used by the public. However, efforts to ensure correct assay operation and result interpretation rely on hardware that cannot be easily scaled or image processing approaches requiring large training datasets, necessitating large numbers of tests and expert labeling with validated specimens for every new test kit format.
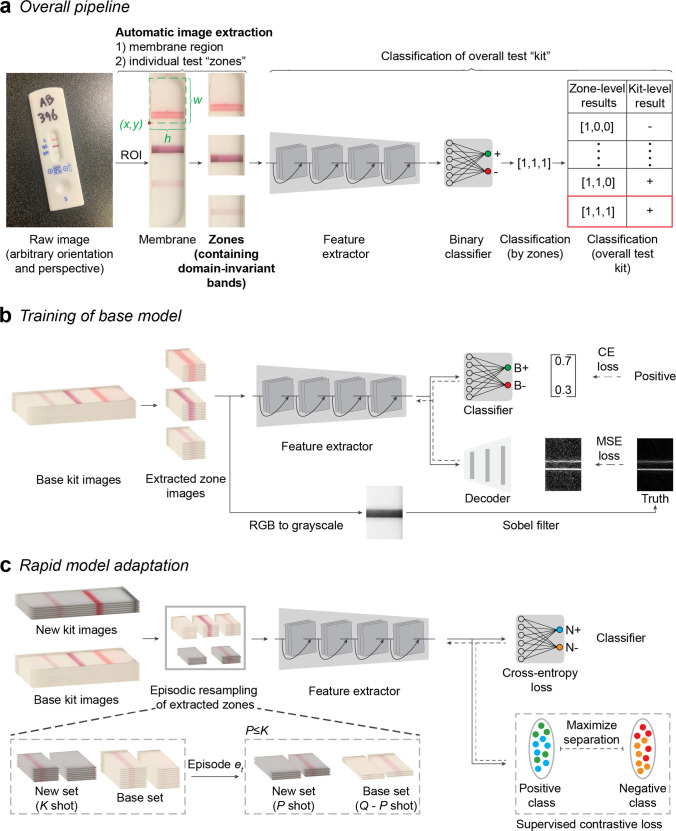
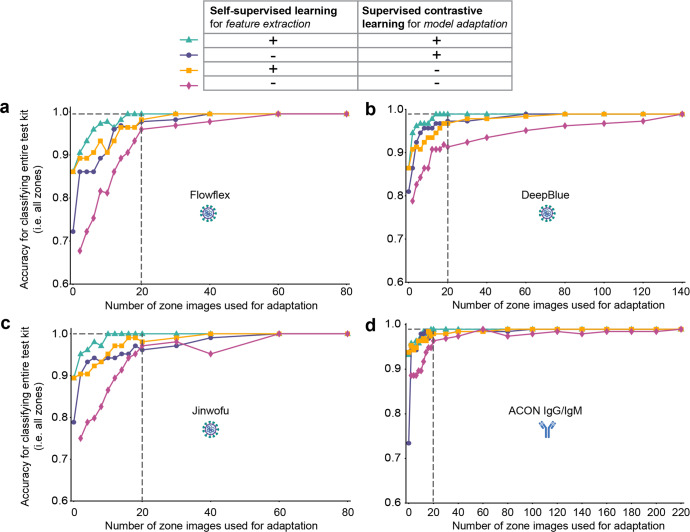
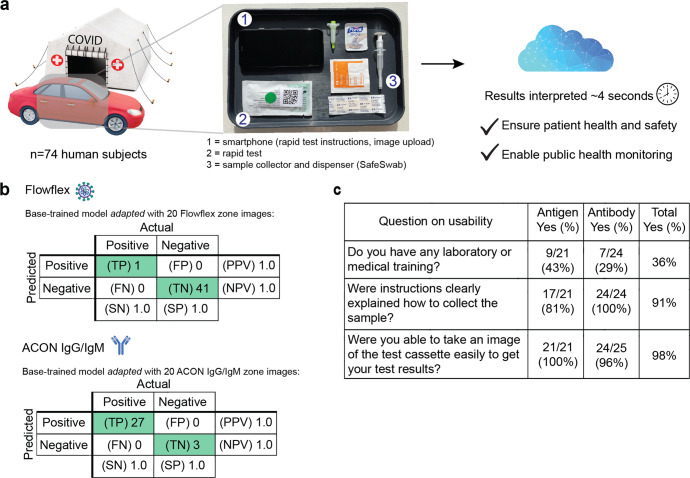
Methods: We developed a software architecture called AutoAdapt POC that integrates automated membrane extraction, self-supervised learning, and few-shot learning to automate the interpretation of POC diagnostic tests using smartphone cameras in a scalable manner. A base model pre-trained on a single LFA kit is adapted to five different COVID-19 tests (three antigen, two antibody) using just 20 labeled images.
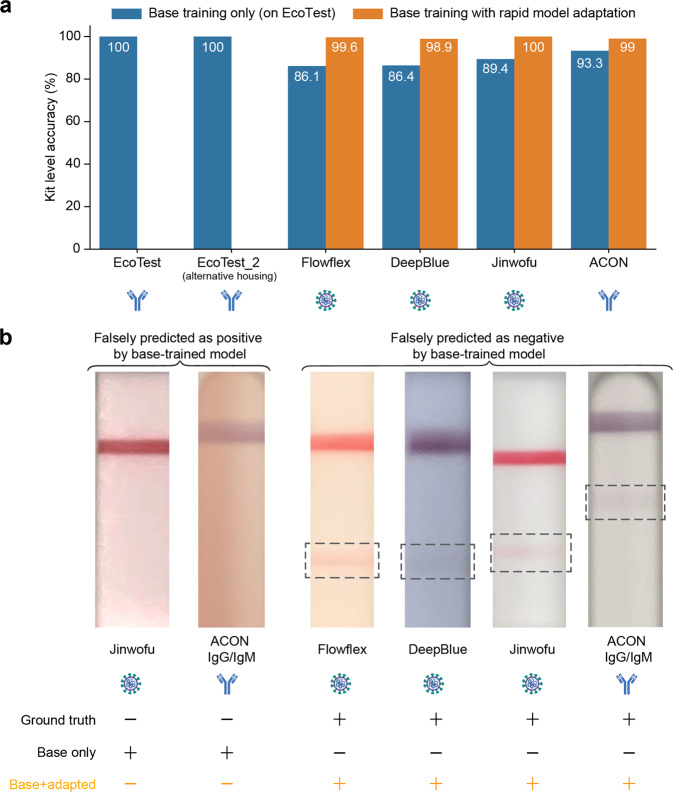
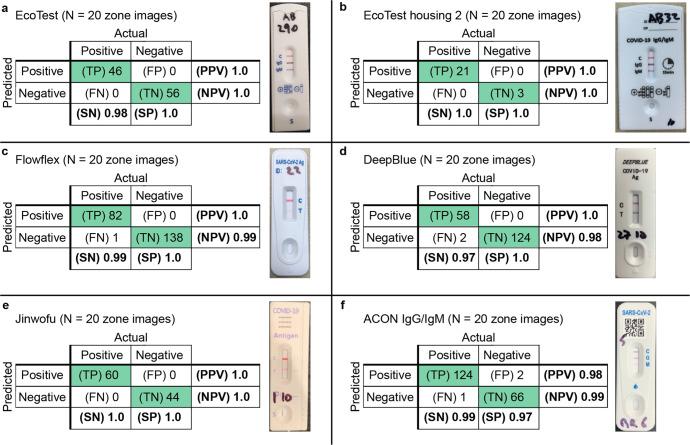
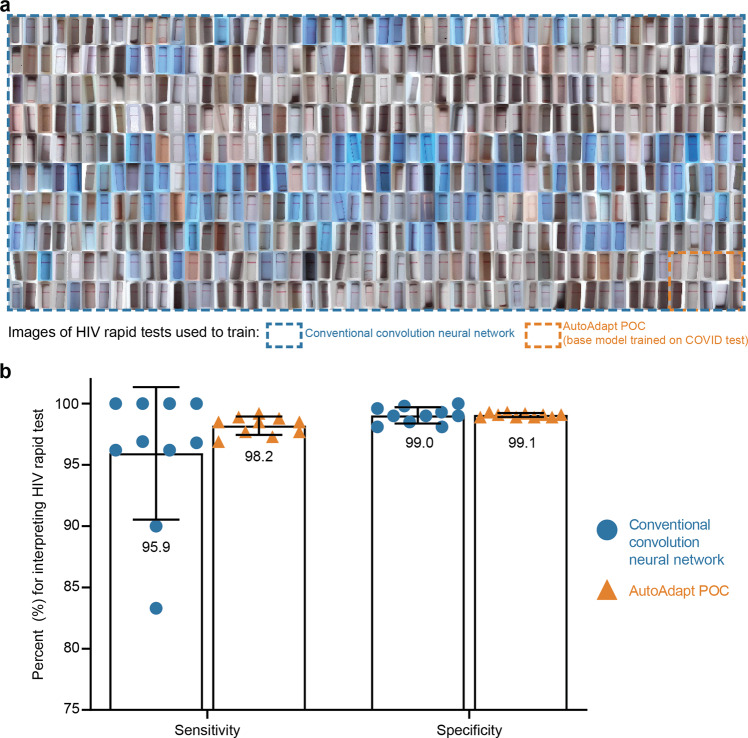
Results: Here we show AutoAdapt POC to yield 99% to 100% accuracy over 726 tests (350 positive, 376 negative). In a COVID-19 drive-through study with 74 untrained users self-testing, 98% found image collection easy, and the rapidly adapted models achieved classification accuracies of 100% on both COVID-19 antigen and antibody test kits. Compared with traditional visual interpretation on 105 test kit results, the algorithm correctly identified 100% of images; without a false negative as interpreted by experts. Finally, compared to a traditional convolutional neural network trained on an HIV test kit, the algorithm showed high accuracy while requiring only 1/50th of the training images.
Conclusions: The study demonstrates how rapid domain adaptation in machine learning can provide quality assurance, linkage to care, and public health tracking for untrained users across diverse POC diagnostic tests.
Plain language summary
It can be difficult to correctly interpret the results of rapid diagnostic tests that give a visual readout, such as COVID rapid tests. We developed a computational algorithm to interpret rapid test results using an image taken by a smartphone camera. This algorithm can easily be adapted for use on results from different test kits. The algorithm was accurate at interpreting results obtained by members of the public using various COVID rapid tests and diagnostic tests with similar outputs used for other infections. The use of this algorithm should enable accurate interpretation of rapid diagnostic tests by members of the public and hence enable improved medical care.
© 2023. The Author(s).
Conflict of interest statement
S.K.S., S.C., S.A., U.M., J.M., G.H., and D.C. declare the following competing interests: A version of this algorithm had been licensed by Columbia University to Safe Health Systems, Inc. Authors with affiliation to Safe Health Systems, Inc. have or had financial interest in Safe Health Systems. All other authors declare no other competing interests.
Figures

References
LinkOut - more resources
Full Text Sources
