

Evaluating GPT as an Adjunct for Radiologic Decision Making: GPT-4 Versus GPT-3.5 in a Breast Imaging Pilot
- PMID: 37356806
- PMCID: PMC10733745
- DOI: 10.1016/j.jacr.2023.05.003
Evaluating GPT as an Adjunct for Radiologic Decision Making: GPT-4 Versus GPT-3.5 in a Breast Imaging Pilot
Abstract
Objective: Despite rising popularity and performance, studies evaluating the use of large language models for clinical decision support are lacking. Here, we evaluate ChatGPT (Generative Pre-trained Transformer)-3.5 and GPT-4's (OpenAI, San Francisco, California) capacity for clinical decision support in radiology via the identification of appropriate imaging services for two important clinical presentations: breast cancer screening and breast pain.
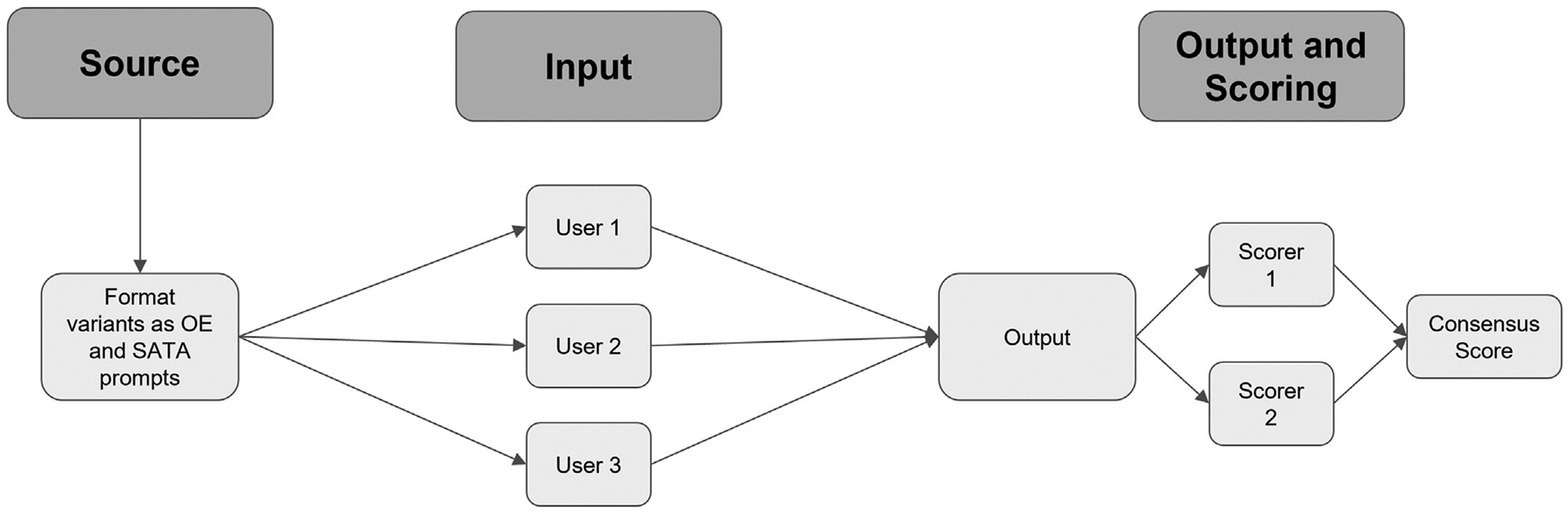
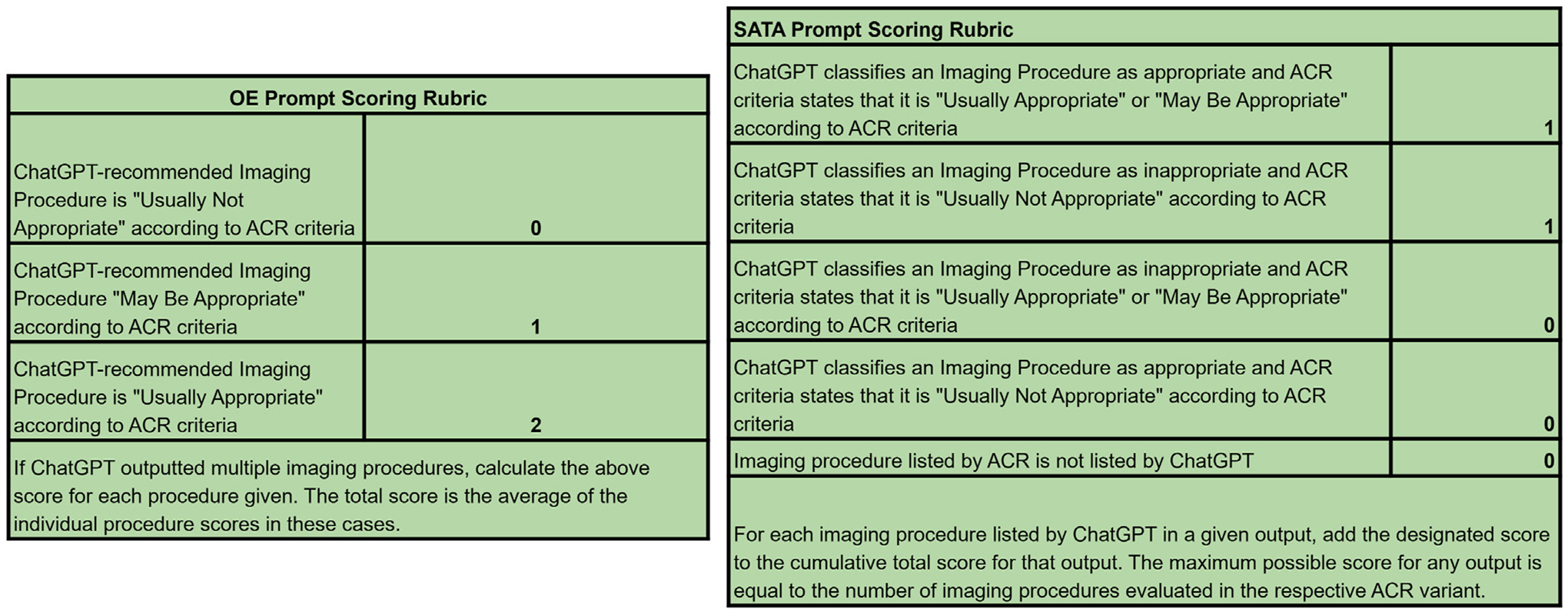
Methods: We compared ChatGPT's responses to the ACR Appropriateness Criteria for breast pain and breast cancer screening. Our prompt formats included an open-ended (OE) and a select all that apply (SATA) format. Scoring criteria evaluated whether proposed imaging modalities were in accordance with ACR guidelines. Three replicate entries were conducted for each prompt, and the average of these was used to determine final scores.
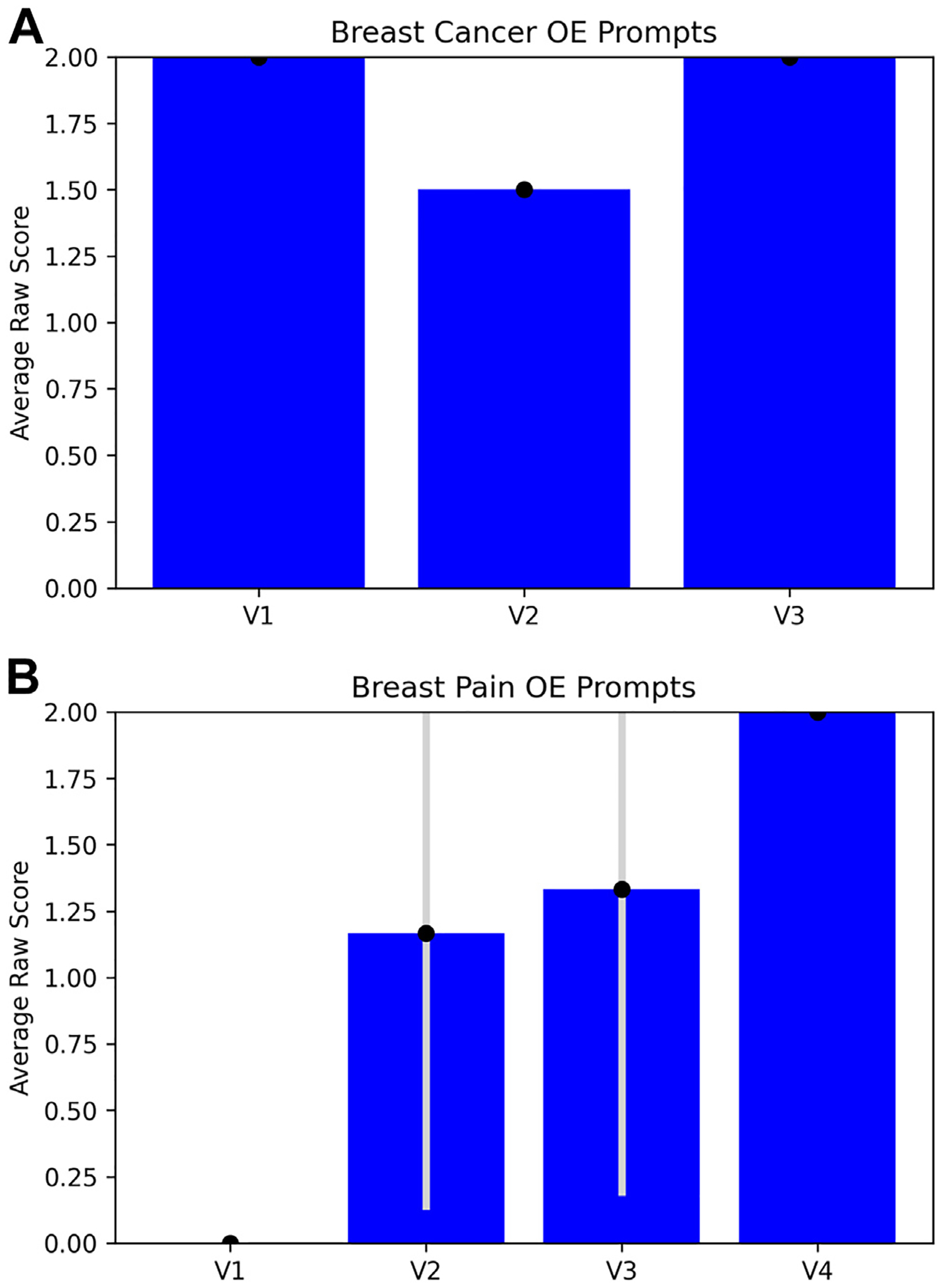
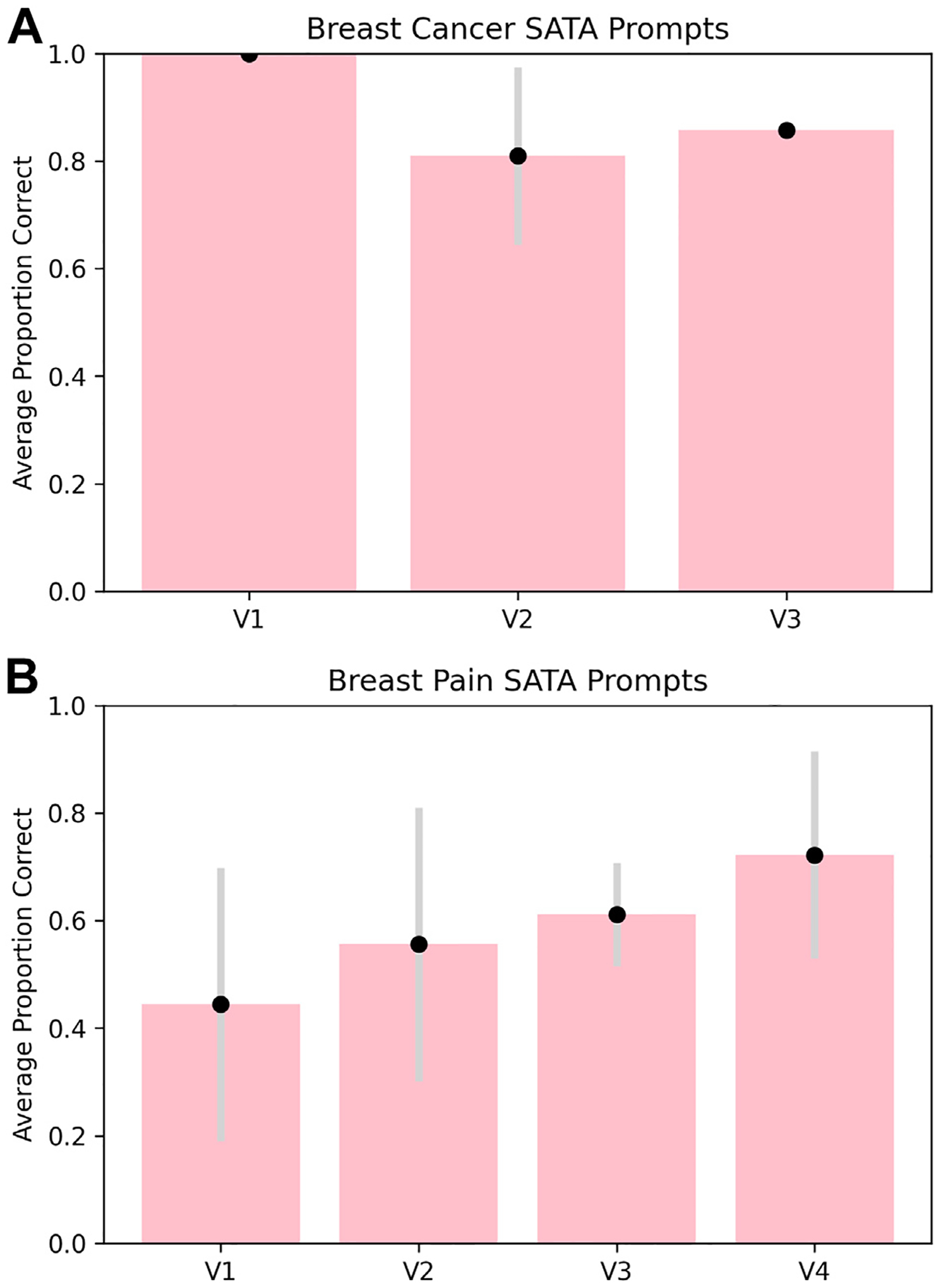
Results: Both ChatGPT-3.5 and ChatGPT-4 achieved an average OE score of 1.830 (out of 2) for breast cancer screening prompts. ChatGPT-3.5 achieved a SATA average percentage correct of 88.9%, compared with ChatGPT-4's average percentage correct of 98.4% for breast cancer screening prompts. For breast pain, ChatGPT-3.5 achieved an average OE score of 1.125 (out of 2) and a SATA average percentage correct of 58.3%, as compared with an average OE score of 1.666 (out of 2) and a SATA average percentage correct of 77.7%.
Discussion: Our results demonstrate the eventual feasibility of using large language models like ChatGPT for radiologic decision making, with the potential to improve clinical workflow and responsible use of radiology services. More use cases and greater accuracy are necessary to evaluate and implement such tools.
Keywords: AI; ChatGPT; breast imaging; clinical decision making; clinical decision support.
Copyright © 2023 American College of Radiology. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
The authors state that they have no conflict of interest related to the material discussed in this article. The authors are non-partner/non-partnership track/employees.
Figures
Update of
-
Evaluating ChatGPT as an Adjunct for Radiologic Decision-Making.medRxiv [Preprint]. 2023 Feb 7:2023.02.02.23285399. doi: 10.1101/2023.02.02.23285399. medRxiv. 2023. Update in: J Am Coll Radiol. 2023 Oct;20(10):990-997. doi: 10.1016/j.jacr.2023.05.003. PMID: 36798292 Free PMC article. Updated. Preprint.
Comment in
-
Combining ChatGPT and machine learning: A viable alternative for discussion in oral medicine.Oral Dis. 2024 Jul;30(5):3521-3522. doi: 10.1111/odi.14706. Epub 2023 Jul 30. Oral Dis. 2024. PMID: 37518993 No abstract available.
-
Transforming Radiology with Artificial Intelligence Visual Chatbot: A Balanced Perspective.J Am Coll Radiol. 2024 Feb;21(2):224-225. doi: 10.1016/j.jacr.2023.07.023. Epub 2023 Sep 1. J Am Coll Radiol. 2024. PMID: 37659450 No abstract available.
-
Comment on: Combining ChatGPT and machine learning: A viable alternative in oral medicine.Oral Dis. 2024 Jul;30(5):3528. doi: 10.1111/odi.14742. Epub 2023 Sep 20. Oral Dis. 2024. PMID: 37731266 No abstract available.
References
-
- Bizzo BC, Almeida RR, Michalski MH, Alkasab TK. Artificial intelligence and clinical decision support for radiologists and referring providers. J Am Coll Radiol 2019;16:1351–6. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
