

PreCoF: counterfactual explanations for fairness
- PMID: 37363047
- PMCID: PMC10047477
- DOI: 10.1007/s10994-023-06319-8
PreCoF: counterfactual explanations for fairness
Abstract
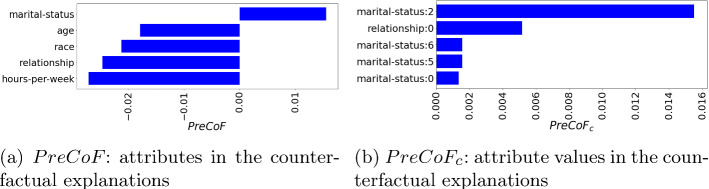
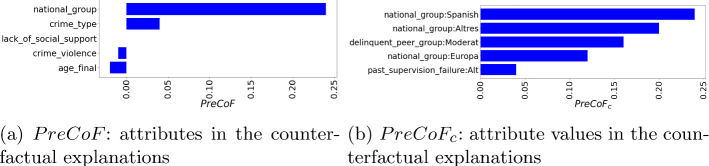
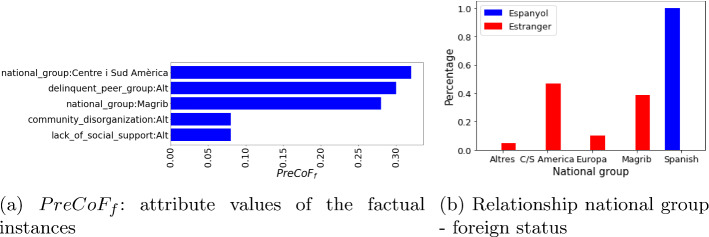
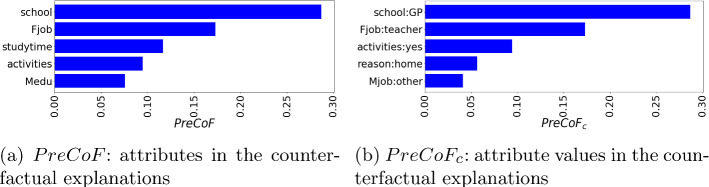
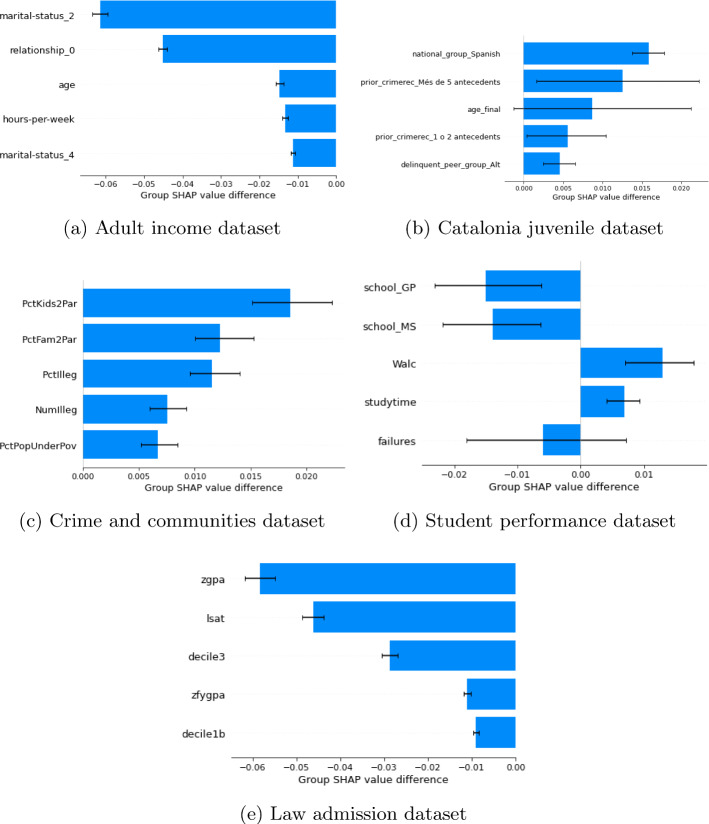
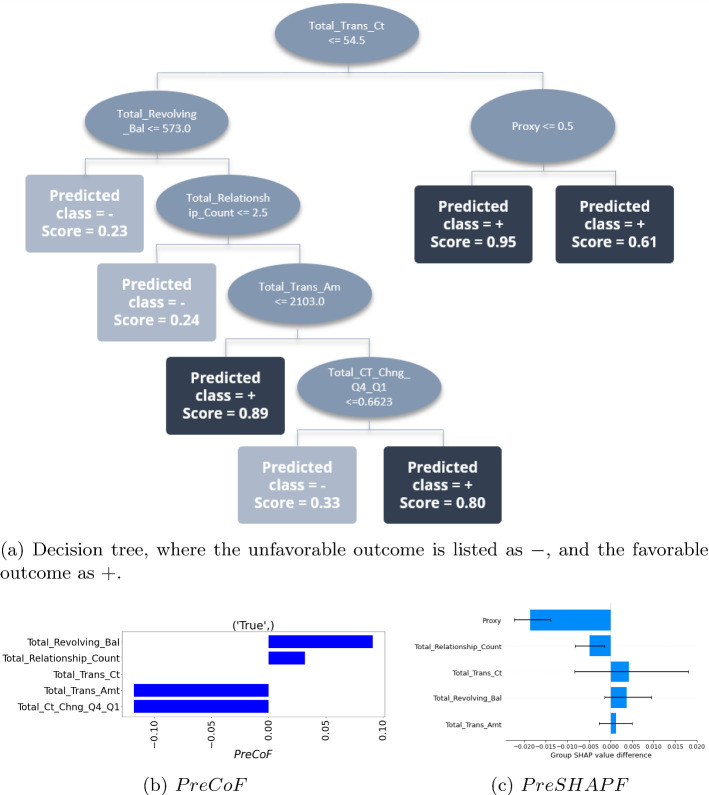
This paper studies how counterfactual explanations can be used to assess the fairness of a model. Using machine learning for high-stakes decisions is a threat to fairness as these models can amplify bias present in the dataset, and there is no consensus on a universal metric to detect this. The appropriate metric and method to tackle the bias in a dataset will be case-dependent, and it requires insight into the nature of the bias first. We aim to provide this insight by integrating explainable AI (XAI) research with the fairness domain. More specifically, apart from being able to use (Predictive) Counterfactual Explanations to detect explicit bias when the model is directly using the sensitive attribute, we show that it can also be used to detect implicit bias when the model does not use the sensitive attribute directly but does use other correlated attributes leading to a substantial disadvantage for a protected group. We call this metric PreCoF, or Predictive Counterfactual Fairness. Our experimental results show that our metric succeeds in detecting occurrences of implicit bias in the model by assessing which attributes are more present in the explanations of the protected group compared to the unprotected group. These results could help policymakers decide on whether this discrimination is justified or not.
Keywords: Counterfactual explanations; Data science ethics; Explainable Artificial Intelligence; Fairness.
© The Author(s), under exclusive licence to Springer Science+Business Media LLC, part of Springer Nature 2023, Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Conflict of interest statement
Conflict of interestNot applicable.
Figures




References
-
- Adadi A, Berrada M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI) IEEE Access. 2018;6:52138–52160. doi: 10.1109/ACCESS.2018.2870052. - DOI
-
- Asuncion, A., & Newman, D. (2007). UCI Machine Learning Repository.
-
- Black, E., Yeom, S., & Fredrikson, M. (2020). Fliptest: Fairness testing via optimal transport. In: Proceedings of the 2020 conference on fairness, accountability, and transparency (pp. 111–121).
-
- Bonchi F, Hajian S, Mishra B, Ramazzotti D. Exposing the probabilistic causal structure of discrimination. International Journal of Data Science and Analytics. 2017;3(1):1–21. doi: 10.1007/s41060-016-0040-z. - DOI
-
- Bordt, S., Finck, M., Raidl, E., & von Luxburg, U. (2022). Post-hoc explanations fail to achieve their purpose in adversarial contexts. arXiv preprint arXiv:2201.10295 .
LinkOut - more resources
Full Text Sources
Miscellaneous