

Algorithmic fairness in artificial intelligence for medicine and healthcare
- PMID: 37380750
- PMCID: PMC10632090
- DOI: 10.1038/s41551-023-01056-8
Algorithmic fairness in artificial intelligence for medicine and healthcare
Abstract
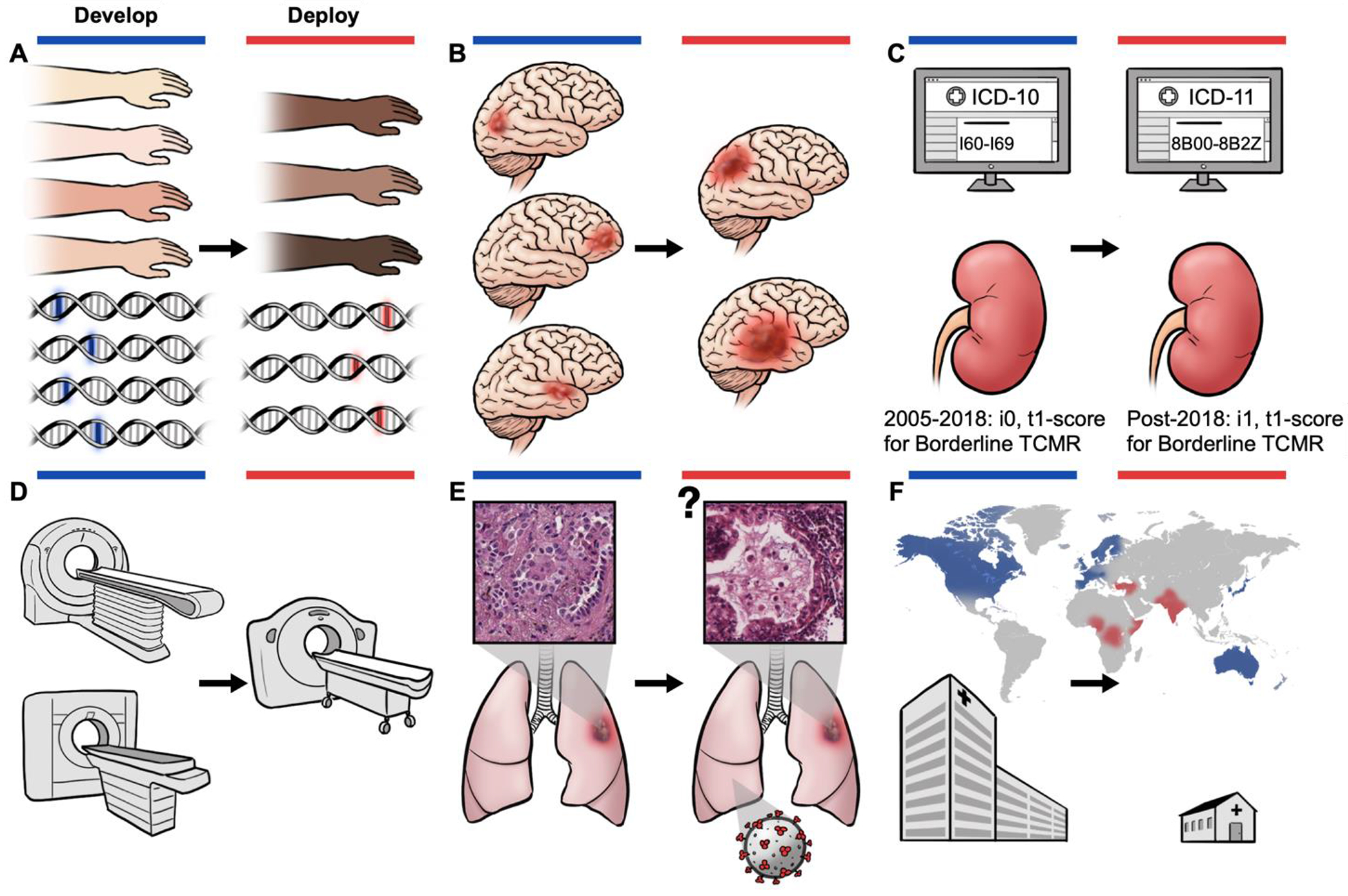
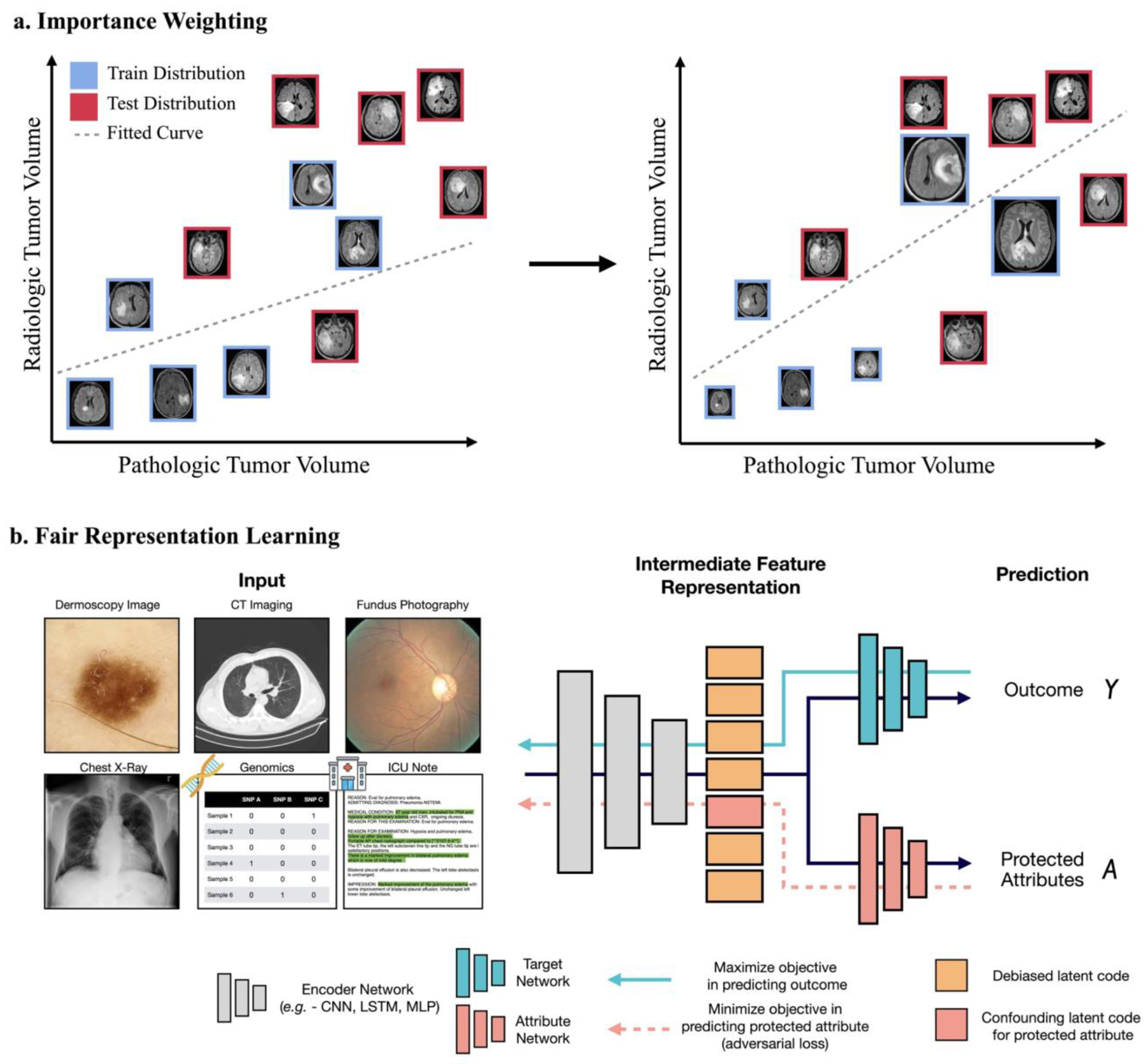
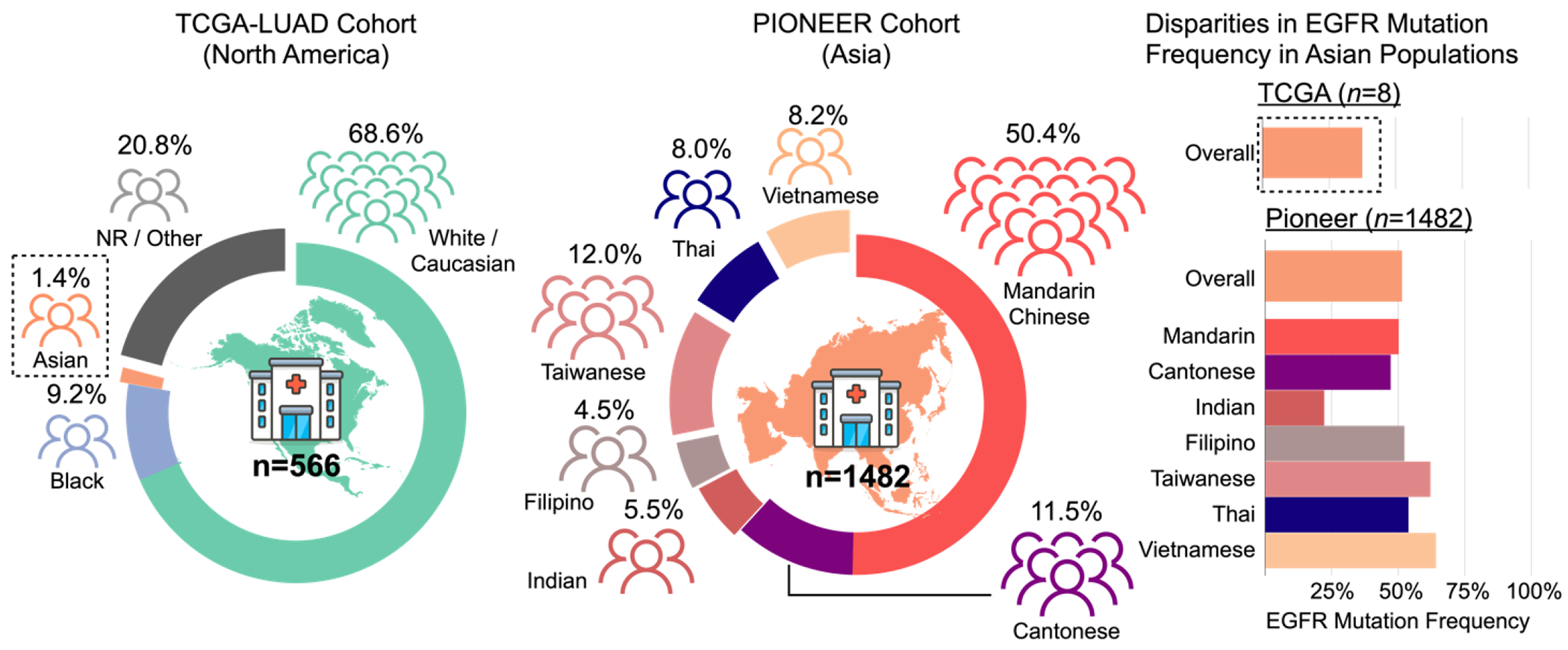
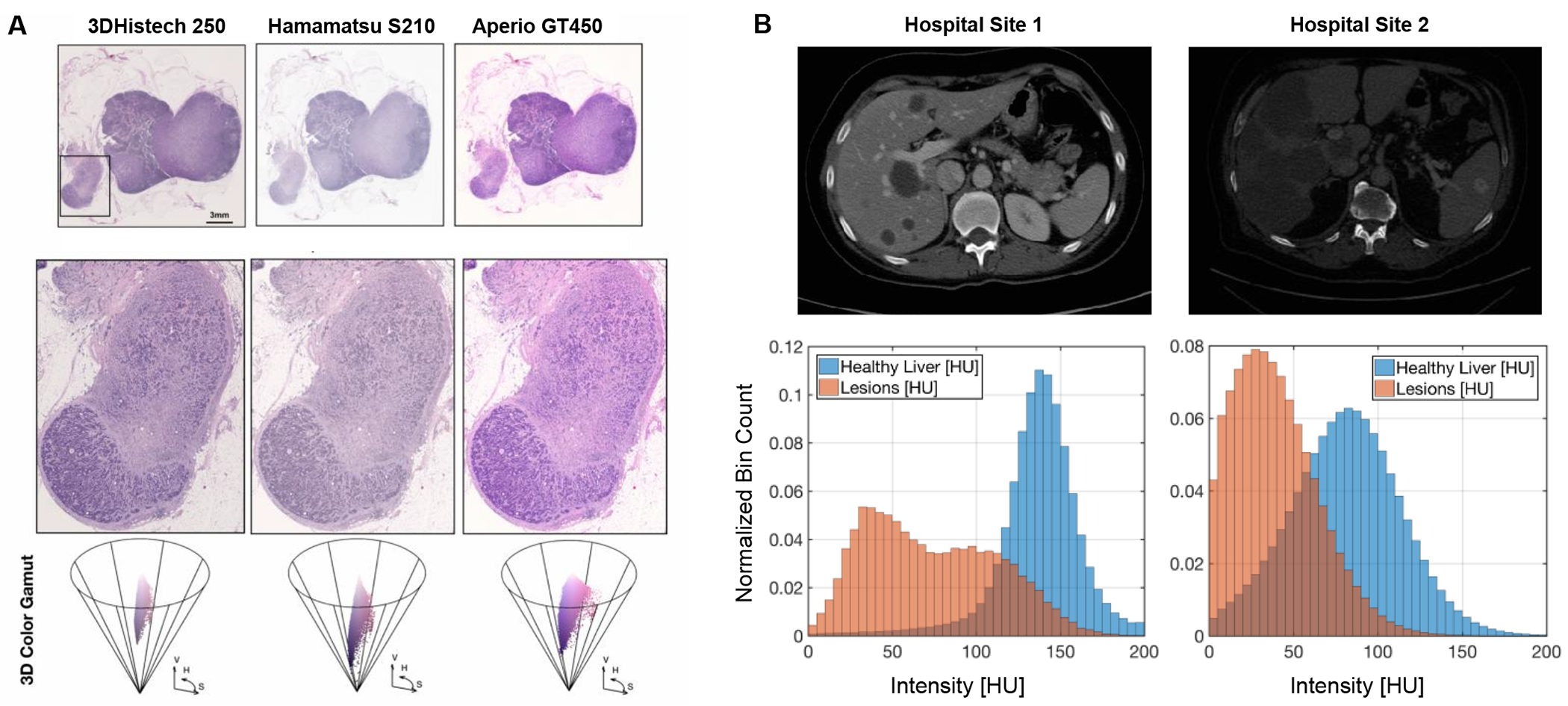
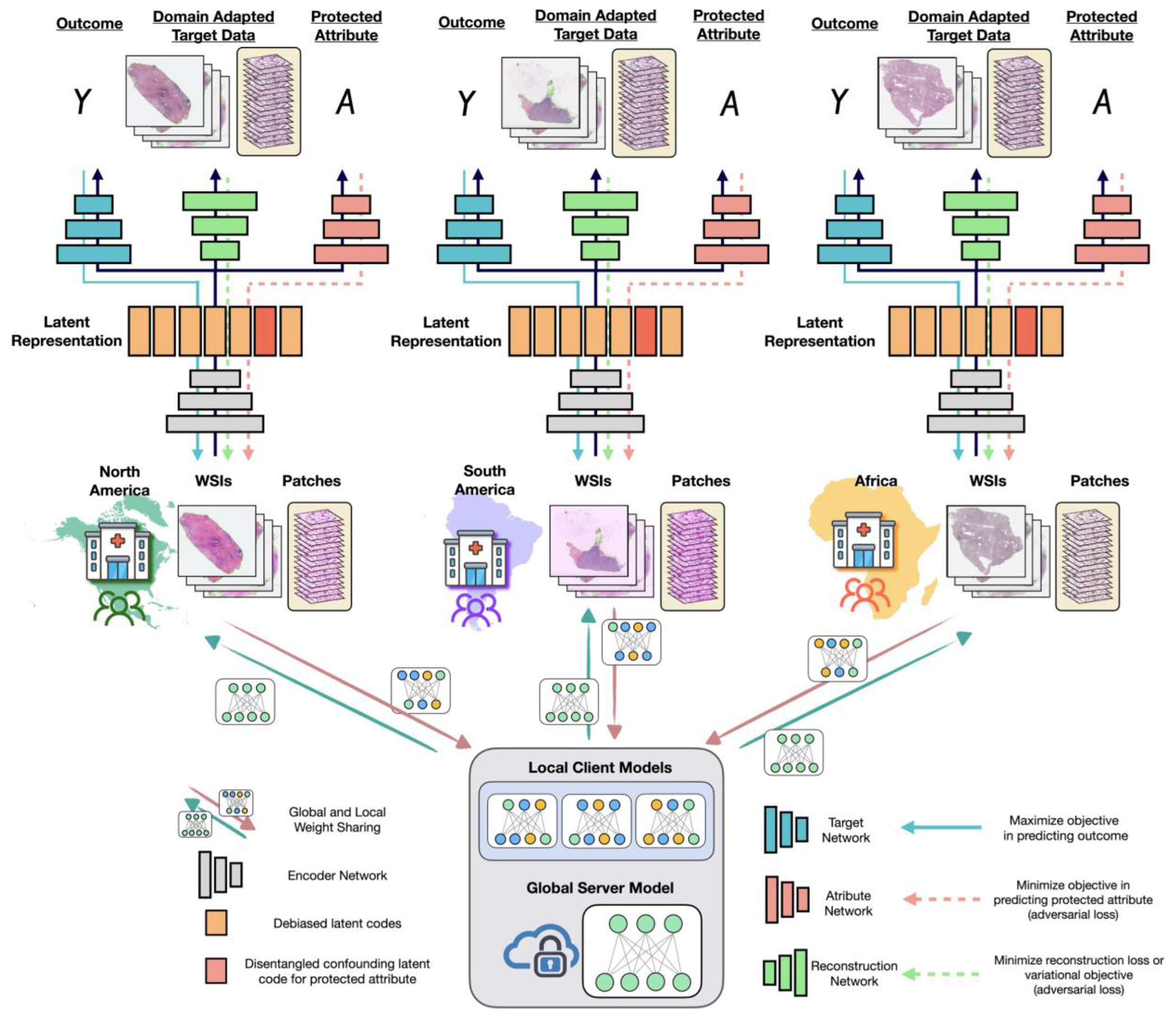
In healthcare, the development and deployment of insufficiently fair systems of artificial intelligence (AI) can undermine the delivery of equitable care. Assessments of AI models stratified across subpopulations have revealed inequalities in how patients are diagnosed, treated and billed. In this Perspective, we outline fairness in machine learning through the lens of healthcare, and discuss how algorithmic biases (in data acquisition, genetic variation and intra-observer labelling variability, in particular) arise in clinical workflows and the resulting healthcare disparities. We also review emerging technology for mitigating biases via disentanglement, federated learning and model explainability, and their role in the development of AI-based software as a medical device.
© 2023. Springer Nature Limited.
Figures
References
-
- Buolamwini J & Gebru T Gender shades: intersectional accuracy disparities in commercial gender classification. In Conf. on Fairness, Accountability and Transparency 77–91 (PMLR, 2018).
-
- Obermeyer Z, Powers B, Vogeli C & Mullainathan S Dissecting racial bias in an algorithm used to manage the health of populations. Science 366, 447–453 (2019). - PubMed
-
- Pierson E, Cutler DM, Leskovec J, Mullainathan S & Obermeyer Z An algorithmic approach to reducing unexplained pain disparities in underserved populations. Nat. Med 27, 136–140 (2021). - PubMed
-
- McCradden MD, Joshi S, Mazwi M & Anderson JA Ethical limitations of algorithmic fairness solutions in health care machine learning. Lancet Digit. Health 2, e221–e223 (2020). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
