

An intrinsically interpretable neural network architecture for sequence-to-function learning
- PMID: 37387140
- PMCID: PMC10311317
- DOI: 10.1093/bioinformatics/btad271
An intrinsically interpretable neural network architecture for sequence-to-function learning
Abstract
Motivation: Sequence-based deep learning approaches have been shown to predict a multitude of functional genomic readouts, including regions of open chromatin and RNA expression of genes. However, a major limitation of current methods is that model interpretation relies on computationally demanding post hoc analyses, and even then, one can often not explain the internal mechanics of highly parameterized models. Here, we introduce a deep learning architecture called totally interpretable sequence-to-function model (tiSFM). tiSFM improves upon the performance of standard multilayer convolutional models while using fewer parameters. Additionally, while tiSFM is itself technically a multilayer neural network, internal model parameters are intrinsically interpretable in terms of relevant sequence motifs.
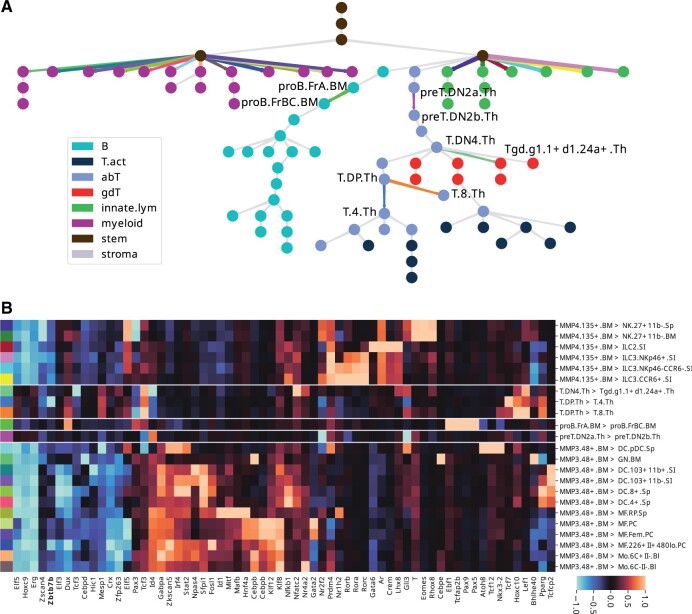
Results: We analyze published open chromatin measurements across hematopoietic lineage cell-types and demonstrate that tiSFM outperforms a state-of-the-art convolutional neural network model custom-tailored to this dataset. We also show that it correctly identifies context-specific activities of transcription factors with known roles in hematopoietic differentiation, including Pax5 and Ebf1 for B-cells, and Rorc for innate lymphoid cells. tiSFM's model parameters have biologically meaningful interpretations, and we show the utility of our approach on a complex task of predicting the change in epigenetic state as a function of developmental transition.
Availability and implementation: The source code, including scripts for the analysis of key findings, can be found at https://github.com/boooooogey/ATAConv, implemented in Python.
© The Author(s) 2023. Published by Oxford University Press.
Conflict of interest statement
None declared.
Figures




Update of
-
An intrinsically interpretable neural network architecture for sequence to function learning.bioRxiv [Preprint]. 2023 Mar 28:2023.01.25.525572. doi: 10.1101/2023.01.25.525572. bioRxiv. 2023. Update in: Bioinformatics. 2023 Jun 30;39(39 Suppl 1):i413-i422. doi: 10.1093/bioinformatics/btad271. PMID: 36747873 Free PMC article. Updated. Preprint.
References
-
- Alipanahi B, Delong A, Weirauch MT. et al. Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Nat Biotechnol 2015;33:831–8. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
