

Are musical activities associated with enhanced speech perception in noise in adults? A systematic review and meta-analysis
- PMID: 37397808
- PMCID: PMC10313871
- DOI: 10.1016/j.crneur.2023.100083
Are musical activities associated with enhanced speech perception in noise in adults? A systematic review and meta-analysis
Abstract
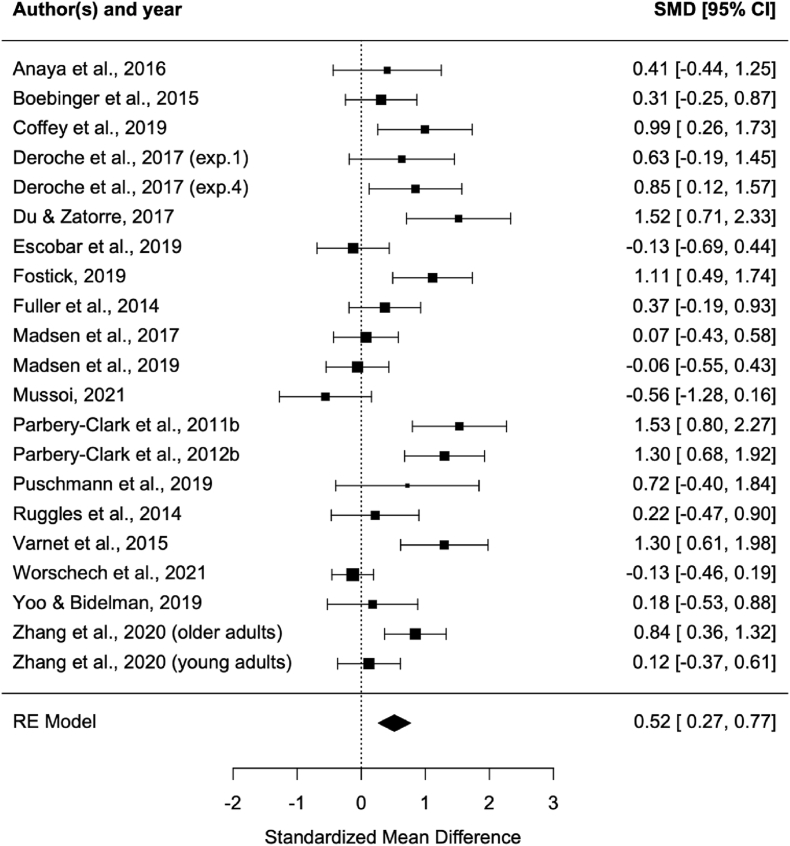
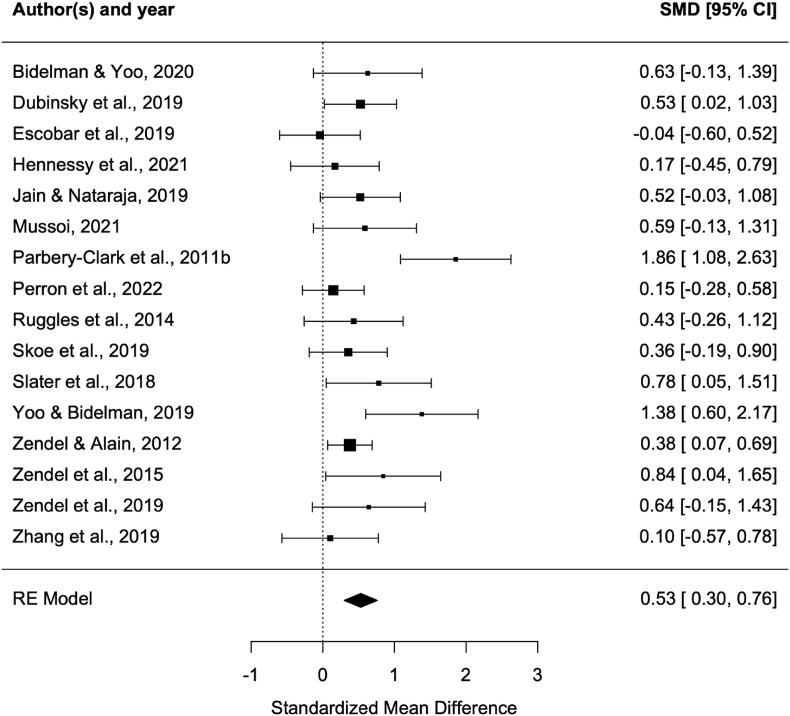
The ability to process speech in noise (SPiN) declines with age, with a detrimental impact on life quality. Music-making activities such as singing and playing a musical instrument have raised interest as potential prevention strategies for SPiN perception decline because of their positive impact on several brain system, especially the auditory system, which is critical for SPiN. However, the literature on the effect of musicianship on SPiN performance has yielded mixed results. By critically assessing the existing literature with a systematic review and a meta-analysis, we aim to provide a comprehensive portrait of the relationship between music-making activities and SPiN in different experimental conditions. 38/49 articles, most focusing on young adults, were included in the quantitative analysis. The results show a positive relationship between music-making activities and SPiN, with the strongest effects found in the most challenging listening conditions, and little to no effect in less challenging situations. This pattern of results supports the notion of a relative advantage for musicians on SPiN performance and clarify the scope of this effect. However, further studies, especially with older adults, using adequate randomization methods, are needed to extend the present conclusions and assess the potential for musical activities to be used to mitigate SPiN decline in seniors.
Keywords: Auditory masking; Cocktail party listening; Experience-dependent plasticity; Learning transfer; Musician; Speech processing; Speech-in-noise.
© 2023 The Authors.
Conflict of interest statement
Pascale Tremblay reports financial support was provided in the form of a research grant by the 10.13039/501100000038Natural Sciences and Engineering Research Council of Canada.
Figures








References
Publication types
LinkOut - more resources
Full Text Sources
