

This is a preprint.
An Open-Source Tool for Automated Human-Level Circling Behavior Detection
- PMID: 37398316
- PMCID: PMC10312579
- DOI: 10.1101/2023.05.30.540066
An Open-Source Tool for Automated Human-Level Circling Behavior Detection
Update in
-
An open-source tool for automated human-level circling behavior detection.Sci Rep. 2024 Sep 8;14(1):20914. doi: 10.1038/s41598-024-71665-z. Sci Rep. 2024. PMID: 39245735 Free PMC article.
Abstract
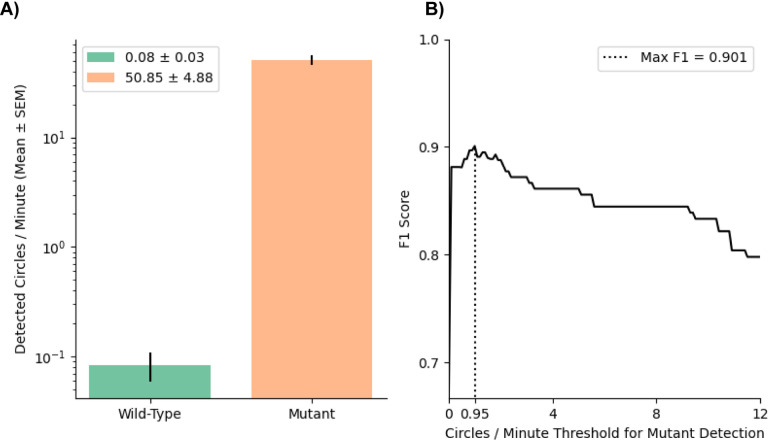
Quantifying behavior and relating it to underlying biological states is of paramount importance in many life science fields. Although barriers to recording postural data have been reduced by progress in deep-learning-based computer vision tools for keypoint tracking, extracting specific behaviors from this data remains challenging. Manual behavior coding, the present gold standard, is labor-intensive and subject to intra- and inter-observer variability. Automatic methods are stymied by the difficulty of explicitly defining complex behaviors, even ones which appear obvious to the human eye. Here, we demonstrate an effective technique for detecting one such behavior, a form of locomotion characterized by stereotyped spinning, termed 'circling'. Though circling has an extensive history as a behavioral marker, at present there exists no standard automated detection method. Accordingly, we developed a technique to identify instances of the behavior by applying simple postprocessing to markerless keypoint data from videos of freely-exploring (Cib2-/-;Cib3-/-) mutant mice, a strain we previously found to exhibit circling. Our technique agrees with human consensus at the same level as do individual observers, and it achieves >90% accuracy in discriminating videos of wild type mice from videos of mutants. As using this technique requires no experience writing or modifying code, it also provides a convenient, noninvasive, quantitative tool for analyzing circling mouse models. Additionally, as our approach was agnostic to the underlying behavior, these results support the feasibility of algorithmically detecting specific, research-relevant behaviors using readily-interpretable parameters tuned on the basis of human consensus.
Figures





References
-
- van den Boom B. J. G., Pavlidi P., Wolf C. J. H., Mooij A. H. & Willuhn I. Automated classification of self-grooming in mice using open-source software. J. Neurosci. Methods 289, 48–56 (2017). - PubMed
-
- Mathis A. et al. DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 21, 1281–1289 (2018). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials