

Physics-informed reinforcement learning for motion control of a fish-like swimming robot
- PMID: 37400473
- PMCID: PMC10318098
- DOI: 10.1038/s41598-023-36399-4
Physics-informed reinforcement learning for motion control of a fish-like swimming robot
Abstract
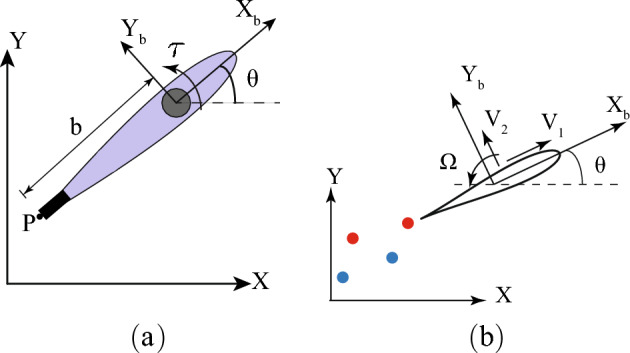
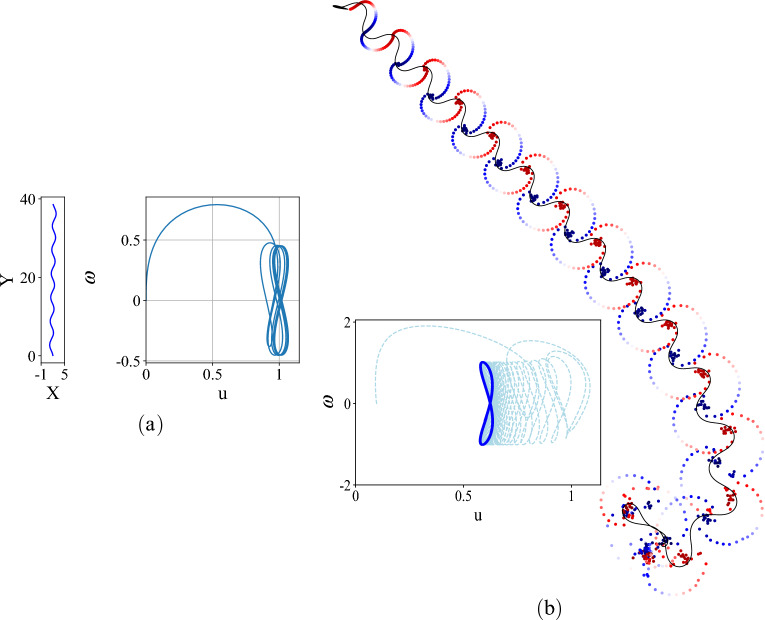
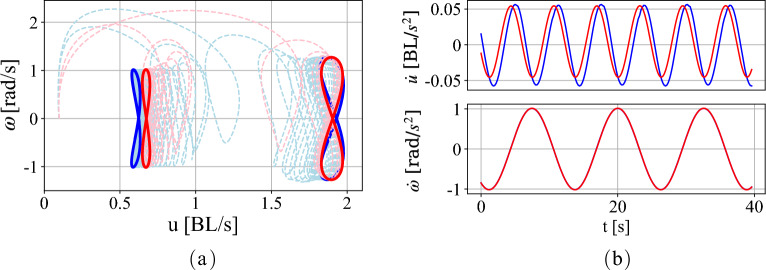
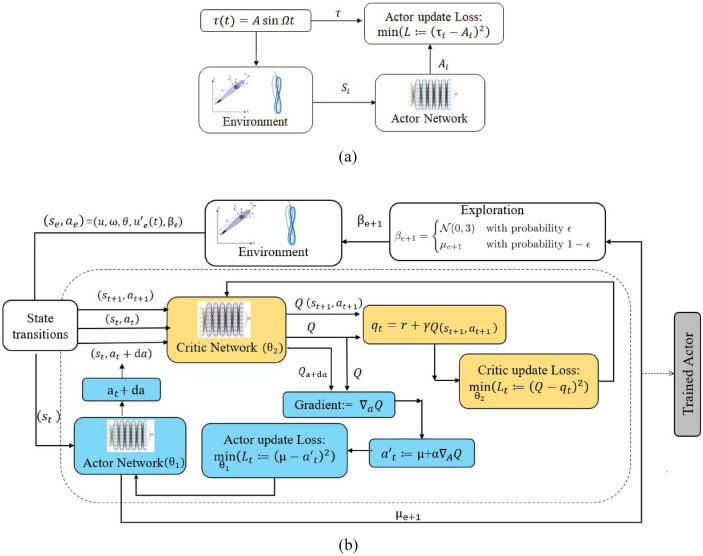
Motion control of fish-like swimming robots presents many challenges due to the unstructured environment and unmodelled governing physics of the fluid-robot interaction. Commonly used low-fidelity control models using simplified formulas for drag and lift forces do not capture key physics that can play an important role in the dynamics of small-sized robots with limited actuation. Deep Reinforcement Learning (DRL) holds considerable promise for motion control of robots with complex dynamics. Reinforcement learning methods require large amounts of training data exploring a large subset of the relevant state space, which can be expensive, time consuming, or unsafe to obtain. Data from simulations can be used in the initial stages of DRL, but in the case of swimming robots, the complexity of fluid-body interactions makes large numbers of simulations infeasible from the perspective of time and computational resources. Surrogate models that capture the primary physics of the system can be a useful starting point for training a DRL agent which is subsequently transferred to train with a higher fidelity simulation. We demonstrate the utility of such physics-informed reinforcement learning to train a policy that can enable velocity and path tracking for a planar swimming (fish-like) rigid Joukowski hydrofoil. This is done through a curriculum where the DRL agent is first trained to track limit cycles in a velocity space for a representative nonholonomic system, and then transferred to train on a small simulation data set of the swimmer. The results show the utility of physics-informed reinforcement learning for the control of fish-like swimming robots.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures

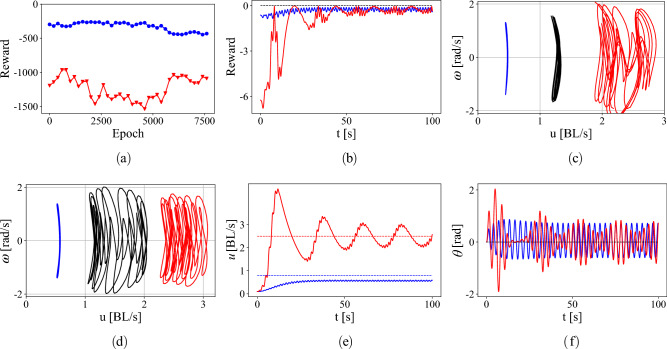
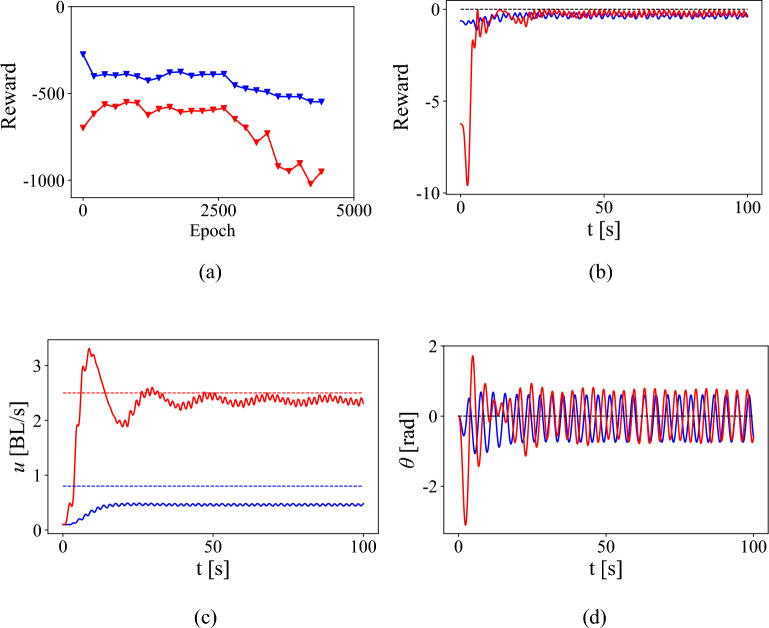
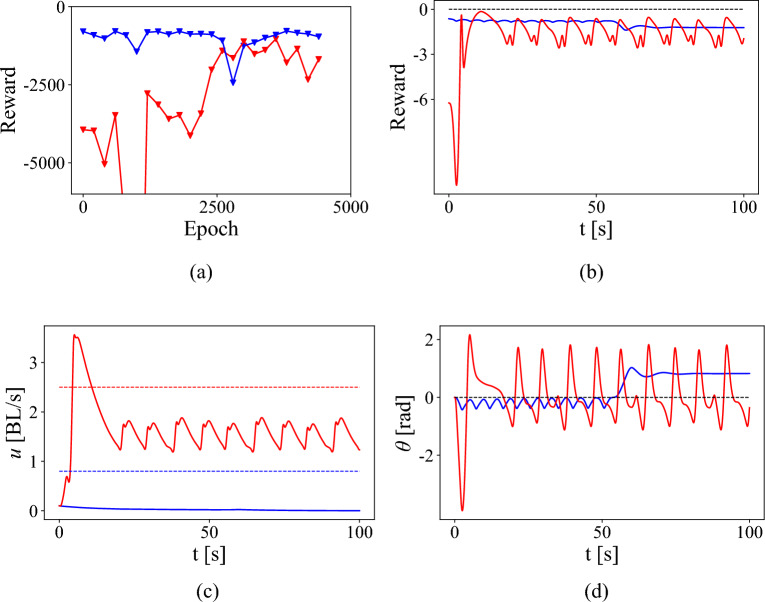

References
-
- Triantafyllou MS, Weymouth GD, Miao J. Biomimetic survival hydrodynamics and flow sensing. Annu. Rev. Fluid Mech. 2016;48:1–10. doi: 10.1146/annurev-fluid-122414-034329. - DOI
-
- Triantafyllou MS, Triantafyllou G. An efficient swimming machine. Sci. Am. 1995;272:64. doi: 10.1038/scientificamerican0395-64. - DOI
-
- Zhong Y, Li Z, Du R. A novel robot fish with wire-driven active body and compliant tail. IEEE/ASME Trans. Mech. 2017;22:1633–1643. doi: 10.1109/TMECH.2017.2712820. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
