

Sampling inequalities affect generalization of neuroimaging-based diagnostic classifiers in psychiatry
- PMID: 37400814
- PMCID: PMC10318841
- DOI: 10.1186/s12916-023-02941-4
Sampling inequalities affect generalization of neuroimaging-based diagnostic classifiers in psychiatry
Abstract
Background: The development of machine learning models for aiding in the diagnosis of mental disorder is recognized as a significant breakthrough in the field of psychiatry. However, clinical practice of such models remains a challenge, with poor generalizability being a major limitation.
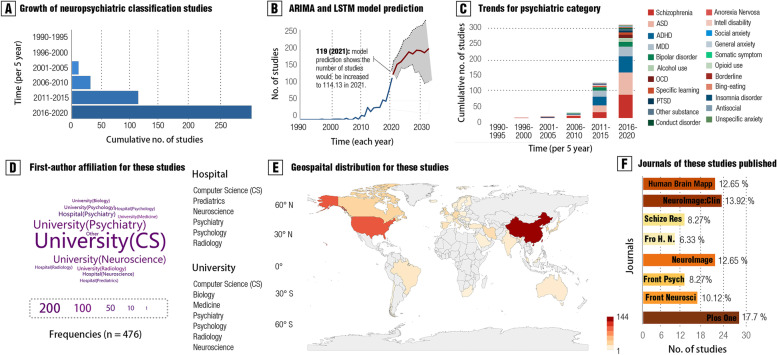
Methods: Here, we conducted a pre-registered meta-research assessment on neuroimaging-based models in the psychiatric literature, quantitatively examining global and regional sampling issues over recent decades, from a view that has been relatively underexplored. A total of 476 studies (n = 118,137) were included in the current assessment. Based on these findings, we built a comprehensive 5-star rating system to quantitatively evaluate the quality of existing machine learning models for psychiatric diagnoses.
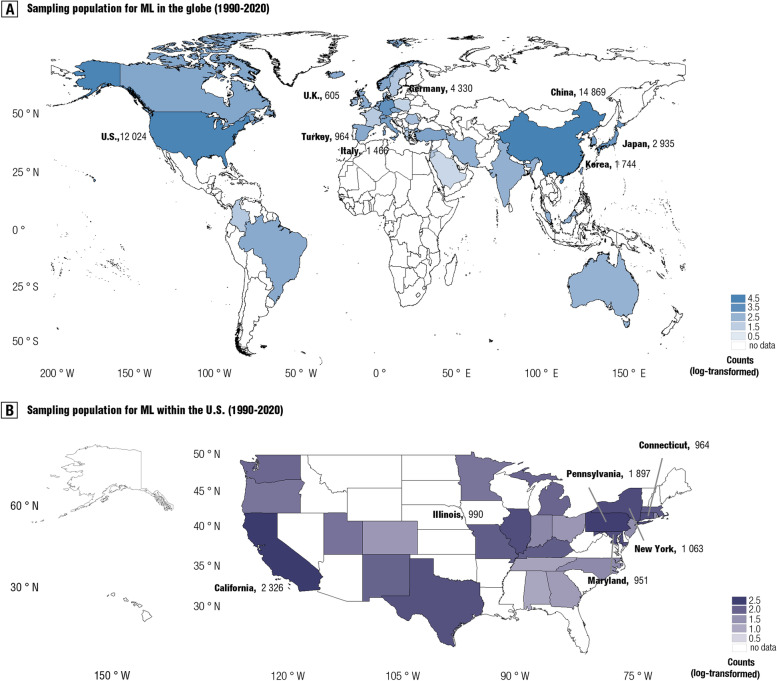
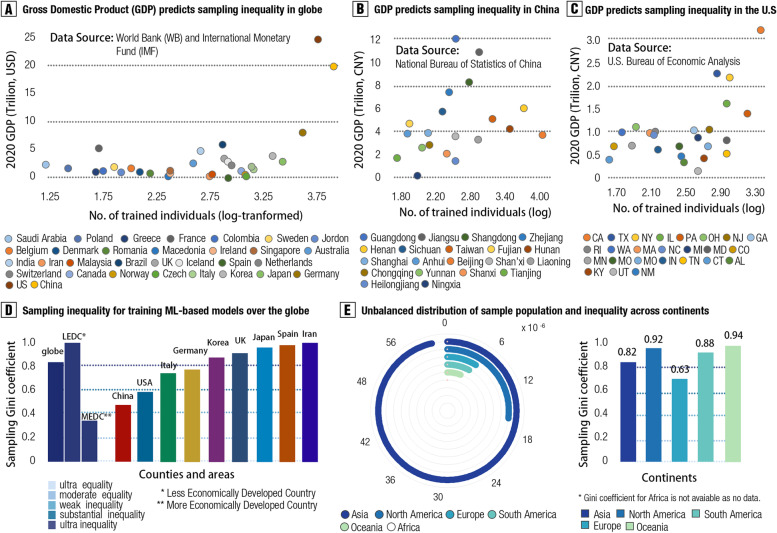
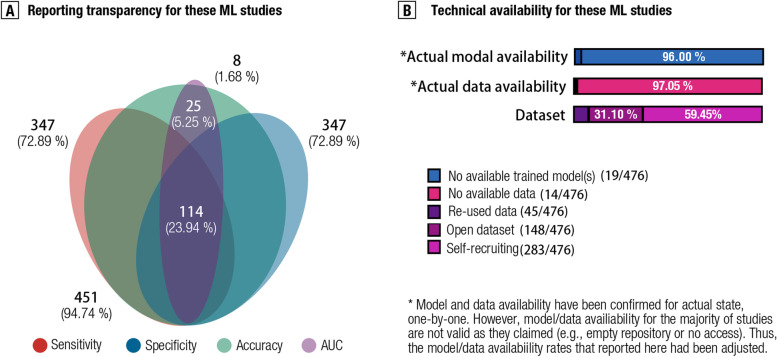
Results: A global sampling inequality in these models was revealed quantitatively (sampling Gini coefficient (G) = 0.81, p < .01), varying across different countries (regions) (e.g., China, G = 0.47; the USA, G = 0.58; Germany, G = 0.78; the UK, G = 0.87). Furthermore, the severity of this sampling inequality was significantly predicted by national economic levels (β = - 2.75, p < .001, R2adj = 0.40; r = - .84, 95% CI: - .41 to - .97), and was plausibly predictable for model performance, with higher sampling inequality for reporting higher classification accuracy. Further analyses showed that lack of independent testing (84.24% of models, 95% CI: 81.0-87.5%), improper cross-validation (51.68% of models, 95% CI: 47.2-56.2%), and poor technical transparency (87.8% of models, 95% CI: 84.9-90.8%)/availability (80.88% of models, 95% CI: 77.3-84.4%) are prevailing in current diagnostic classifiers despite improvements over time. Relating to these observations, model performances were found decreased in studies with independent cross-country sampling validations (all p < .001, BF10 > 15). In light of this, we proposed a purpose-built quantitative assessment checklist, which demonstrated that the overall ratings of these models increased by publication year but were negatively associated with model performance.
Conclusions: Together, improving sampling economic equality and hence the quality of machine learning models may be a crucial facet to plausibly translating neuroimaging-based diagnostic classifiers into clinical practice.
Keywords: Diagnostic classification; Meta-analysis; Neuroimaging; Psychiatric machine learning; Sampling inequalities.
© 2023. The Author(s).
Conflict of interest statement
The authors declare that they have no competing interests.
Figures


References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Miscellaneous
