

A transformers-based approach for fine and coarse-grained classification and generation of MIDI songs and soundtracks
- PMID: 37409082
- PMCID: PMC10319258
- DOI: 10.7717/peerj-cs.1410
A transformers-based approach for fine and coarse-grained classification and generation of MIDI songs and soundtracks
Abstract
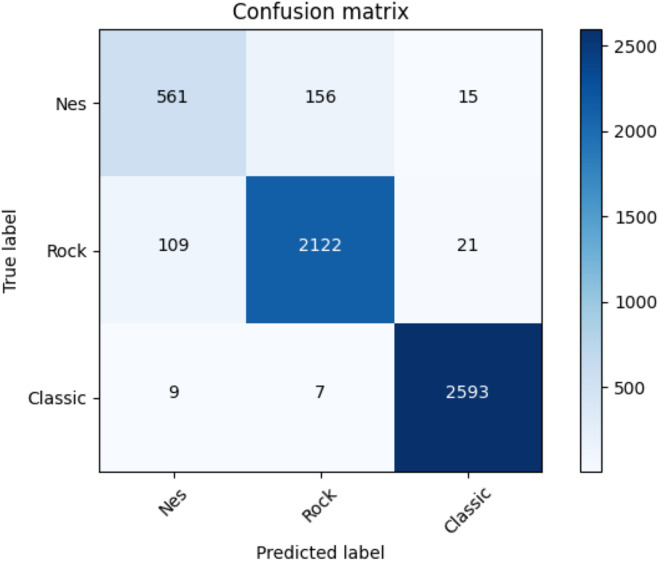
Music is an extremely subjective art form whose commodification via the recording industry in the 20th century has led to an increasingly subdivided set of genre labels that attempt to organize musical styles into definite categories. Music psychology has been studying the processes through which music is perceived, created, responded to, and incorporated into everyday life, and, modern artificial intelligence technology can be exploited in such a direction. Music classification and generation are emerging fields that gained much attention recently, especially with the latest discoveries within deep learning technologies. Self attention networks have in fact brought huge benefits for several tasks of classification and generation in different domains where data of different types were used (text, images, videos, sounds). In this article, we want to analyze the effectiveness of Transformers for both classification and generation tasks and study the performances of classification at different granularity and of generation using different human and automatic metrics. The input data consist of MIDI sounds that we have considered from different datasets: sounds from 397 Nintendo Entertainment System video games, classical pieces, and rock songs from different composers and bands. We have performed classification tasks within each dataset to identify the types or composers of each sample (fine-grained) and classification at a higher level. In the latter, we combined the three datasets together with the goal of identifying for each sample just NES, rock, or classical (coarse-grained) pieces. The proposed transformers-based approach outperformed competitors based on deep learning and machine learning approaches. Finally, the generation task has been carried out on each dataset and the resulting samples have been evaluated using human and automatic metrics (the local alignment).
Keywords: Classification; Deep Learning; Generation; MIDI; Transformers.
©2023 Angioni et al.
Conflict of interest statement
The authors declare there are no competing interests.
Figures









References
-
- Atzeni M, Recupero DR. Multi-domain sentiment analysis with mimicked and polarized word embeddings for human-robot interaction. Future Generation Computer Systems. 2020;110:984–999. doi: 10.1016/j.future.2019.10.012. - DOI
-
- Baevski A, Zhou H, Mohamed A, Auli M. Wav2vec 2.0: a framework for self-supervised learning of speech representations. Proceedings of the 34th international conference on neural information processing systems. NIPS’20; Red Hook. 2020.
-
- Barra S, Carta SM, Corriga A, Podda AS, Recupero DR. Deep learning and time series-to-image encoding for financial forecasting. IEEE/CAA Journal of Automatica Sinica. 2020;7(3):683–692. doi: 10.1109/jas.2020.1003132. - DOI
-
- Bernardo A, Langlois T. Automatic classification of MIDI tracks. In: Cordeiro J, Filipe J, editors. ICEIS 2008—proceedings of the tenth international conference on enterprise information systems, volume AIDSS, Barcelona, Spain, June 12–16, 2008; 2008. pp. 539–543.
-
- Bountouridis D, Brown DG, Wiering F, Veltkamp RC. Melodic similarity and applications using biologically-inspired techniques. Applied Sciences. 2017;7(12):1242. doi: 10.3390/app7121242. - DOI
LinkOut - more resources
Full Text Sources