

Linear fine-tuning: a linear transformation based transfer strategy for deep MRI reconstruction
- PMID: 37409107
- PMCID: PMC10318193
- DOI: 10.3389/fnins.2023.1202143
Linear fine-tuning: a linear transformation based transfer strategy for deep MRI reconstruction
Abstract
Introduction: Fine-tuning (FT) is a generally adopted transfer learning method for deep learning-based magnetic resonance imaging (MRI) reconstruction. In this approach, the reconstruction model is initialized with pre-trained weights derived from a source domain with ample data and subsequently updated with limited data from the target domain. However, the direct full-weight update strategy can pose the risk of "catastrophic forgetting" and overfitting, hindering its effectiveness. The goal of this study is to develop a zero-weight update transfer strategy to preserve pre-trained generic knowledge and reduce overfitting.
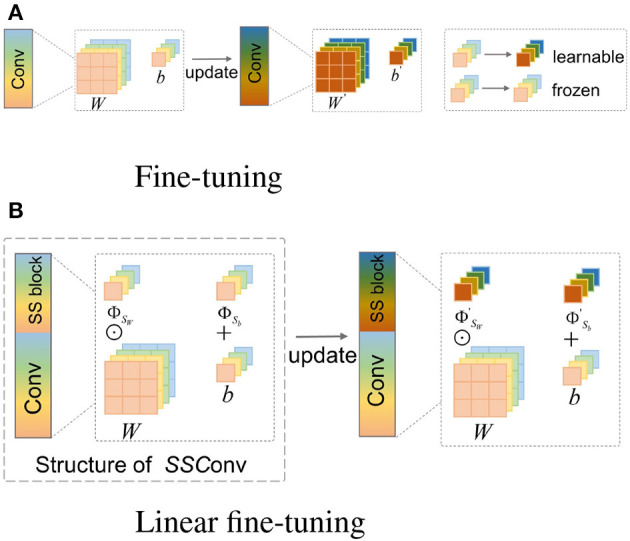
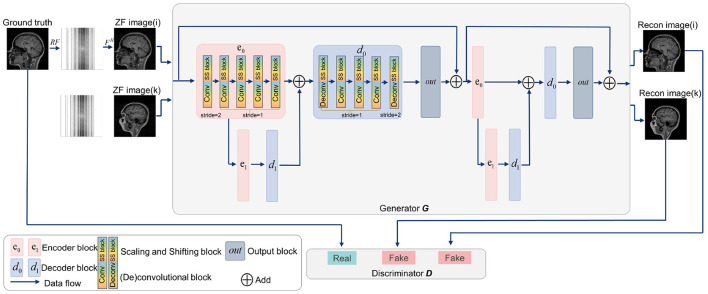
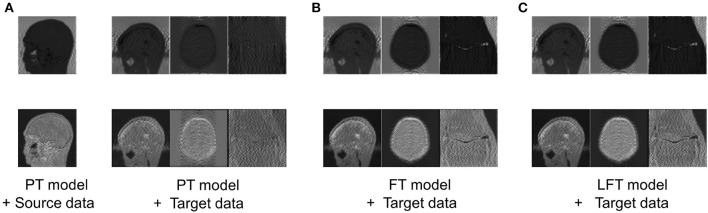
Methods: Based on the commonality between the source and target domains, we assume a linear transformation relationship of the optimal model weights from the source domain to the target domain. Accordingly, we propose a novel transfer strategy, linear fine-tuning (LFT), which introduces scaling and shifting (SS) factors into the pre-trained model. In contrast to FT, LFT only updates SS factors in the transfer phase, while the pre-trained weights remain fixed.
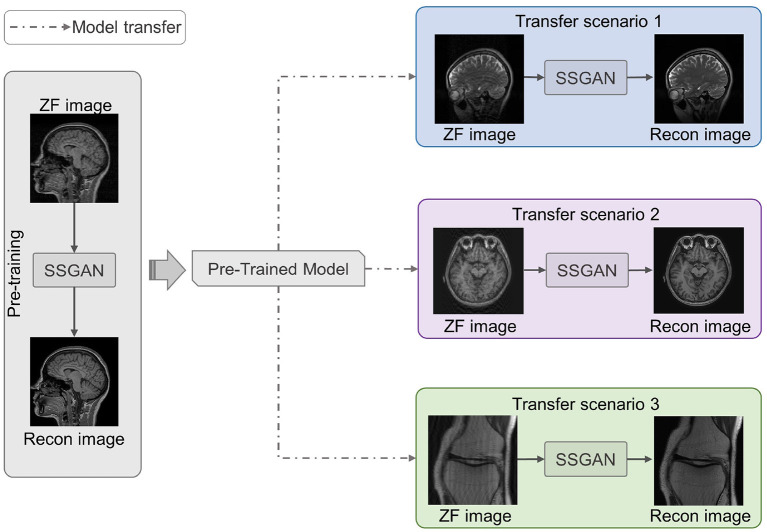
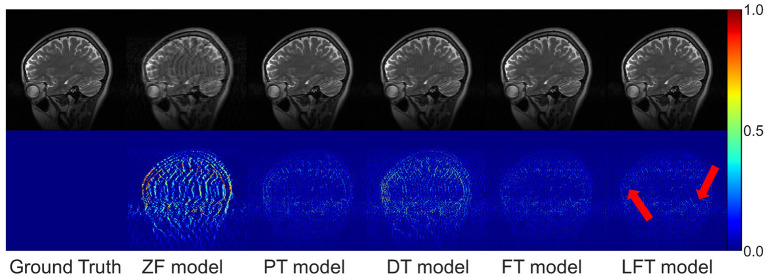
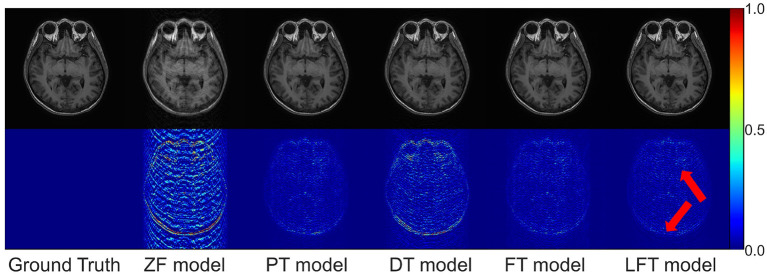
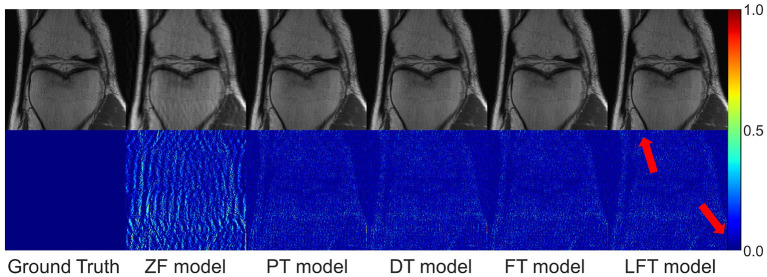
Results: To evaluate the proposed LFT, we designed three different transfer scenarios and conducted a comparative analysis of FT, LFT, and other methods at various sampling rates and data volumes. In the transfer scenario between different contrasts, LFT outperforms typical transfer strategies at various sampling rates and considerably reduces artifacts on reconstructed images. In transfer scenarios between different slice directions or anatomical structures, LFT surpasses the FT method, particularly when the target domain contains a decreasing number of training images, with a maximum improvement of up to 2.06 dB (5.89%) in peak signal-to-noise ratio.
Discussion: The LFT strategy shows great potential to address the issues of "catastrophic forgetting" and overfitting in transfer scenarios for MRI reconstruction, while reducing the reliance on the amount of data in the target domain. Linear fine-tuning is expected to shorten the development cycle of reconstruction models for adapting complicated clinical scenarios, thereby enhancing the clinical applicability of deep MRI reconstruction.
Keywords: deep learning; fine-tuning; magnetic resonance imaging reconstruction; transfer learning; transfer strategy.
Copyright © 2023 Bi, Xv, Song, Hao, Gao and Qi.
Conflict of interest statement
XH was employed by Fuqing Medical Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures
Similar articles
-
Autoencoder and restricted Boltzmann machine for transfer learning in functional magnetic resonance imaging task classification.Heliyon. 2023 Jul 16;9(7):e18086. doi: 10.1016/j.heliyon.2023.e18086. eCollection 2023 Jul. Heliyon. 2023. PMID: 37519689 Free PMC article.
-
Transfer learning in deep neural network based under-sampled MR image reconstruction.Magn Reson Imaging. 2021 Feb;76:96-107. doi: 10.1016/j.mri.2020.09.018. Epub 2020 Sep 24. Magn Reson Imaging. 2021. PMID: 32980504
-
Brain tumor classification for MR images using transfer learning and fine-tuning.Comput Med Imaging Graph. 2019 Jul;75:34-46. doi: 10.1016/j.compmedimag.2019.05.001. Epub 2019 May 18. Comput Med Imaging Graph. 2019. PMID: 31150950
-
A Transfer-Learning Approach for Accelerated MRI Using Deep Neural Networks.Magn Reson Med. 2020 Aug;84(2):663-685. doi: 10.1002/mrm.28148. Epub 2020 Jan 3. Magn Reson Med. 2020. PMID: 31898840
-
MRI super-resolution reconstruction for MRI-guided adaptive radiotherapy using cascaded deep learning: In the presence of limited training data and unknown translation model.Med Phys. 2019 Sep;46(9):4148-4164. doi: 10.1002/mp.13717. Epub 2019 Aug 7. Med Phys. 2019. PMID: 31309585
References
-
- Aletras A. H., Tilak G. S., Natanzon A., Hsu L.-Y., Gonzalez F. M., Hoyt R. F., Jr., et al. . (2006). Retrospective determination of the area at risk for reperfused acute myocardial infarction with t2-weighted cardiac magnetic resonance imaging: histopathological and displacement encoding with stimulated echoes (dense) functional validations. Circulation 113, 1865–1870. 10.1161/CIRCULATIONAHA.105.576025 - DOI - PubMed
LinkOut - more resources
Full Text Sources
Miscellaneous