

A deep network-based model of hippocampal memory functions under normal and Alzheimer's disease conditions
- PMID: 37416627
- PMCID: PMC10320296
- DOI: 10.3389/fncir.2023.1092933
A deep network-based model of hippocampal memory functions under normal and Alzheimer's disease conditions
Abstract
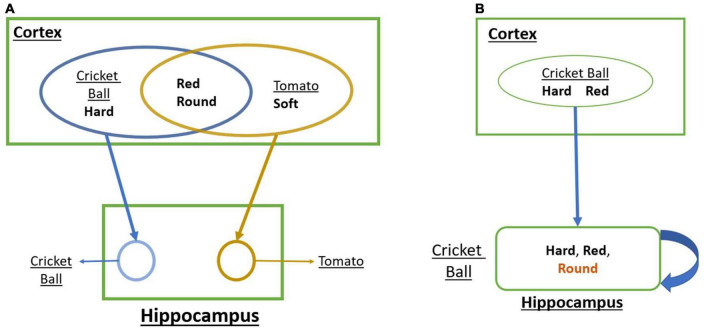
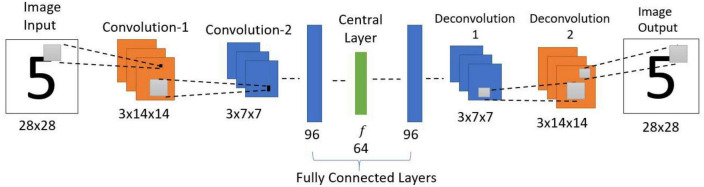
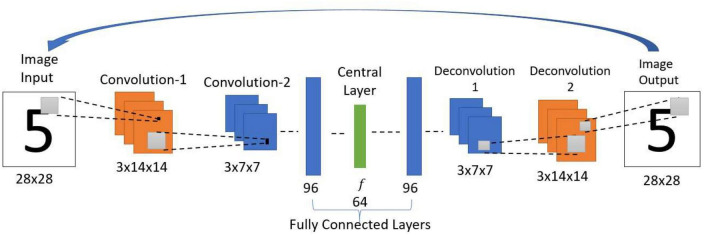
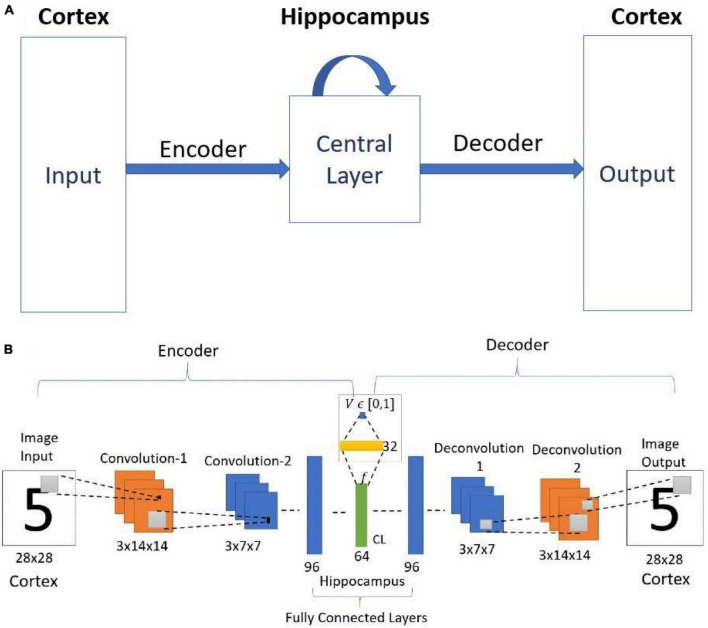
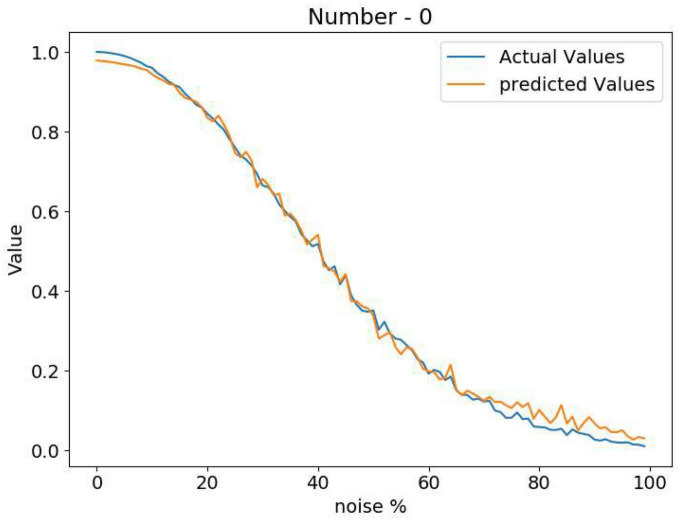
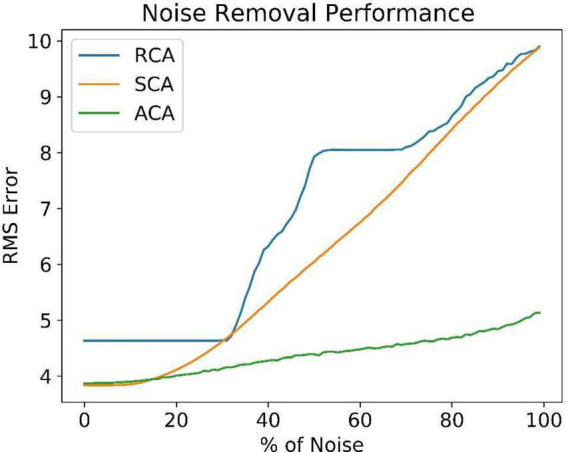
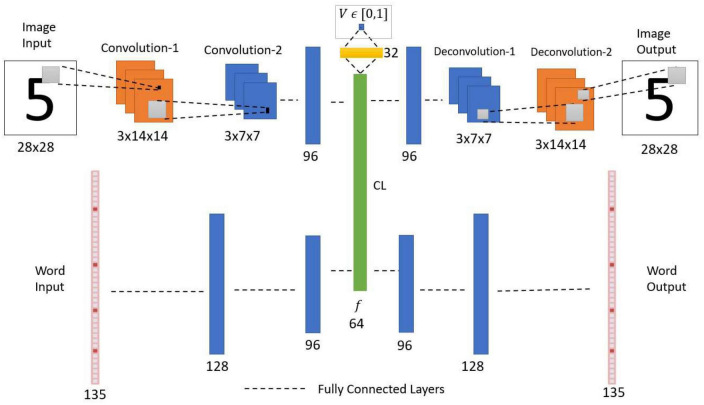
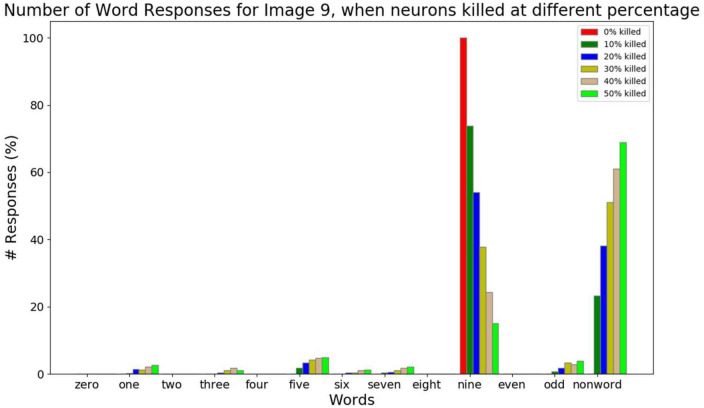
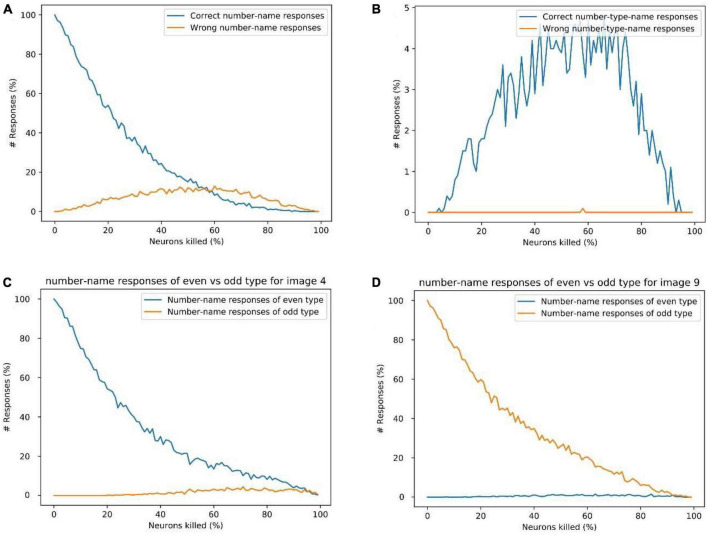
We present a deep network-based model of the associative memory functions of the hippocampus. The proposed network architecture has two key modules: (1) an autoencoder module which represents the forward and backward projections of the cortico-hippocampal projections and (2) a module that computes familiarity of the stimulus and implements hill-climbing over the familiarity which represents the dynamics of the loops within the hippocampus. The proposed network is used in two simulation studies. In the first part of the study, the network is used to simulate image pattern completion by autoassociation under normal conditions. In the second part of the study, the proposed network is extended to a heteroassociative memory and is used to simulate picture naming task in normal and Alzheimer's disease (AD) conditions. The network is trained on pictures and names of digits from 0 to 9. The encoder layer of the network is partly damaged to simulate AD conditions. As in case of AD patients, under moderate damage condition, the network recalls superordinate words ("odd" instead of "nine"). Under severe damage conditions, the network shows a null response ("I don't know"). Neurobiological plausibility of the model is extensively discussed.
Keywords: Alzheimer’s disease; associative memory recall; autoencoder; dopamine; familiarity; hippocampus; pattern completion; picture-naming task.
Copyright © 2023 Kanagamani, Chakravarthy, Ravindran and Menon.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures



Similar articles
-
An integrative memory model of recollection and familiarity to understand memory deficits.Behav Brain Sci. 2019 Feb 5;42:e281. doi: 10.1017/S0140525X19000621. Behav Brain Sci. 2019. PMID: 30719958
-
Item familiarity and controlled associative retrieval in Alzheimer's disease: an fMRI study.Cortex. 2013 Jun;49(6):1566-84. doi: 10.1016/j.cortex.2012.11.017. Epub 2012 Dec 19. Cortex. 2013. PMID: 23313012
-
Impaired recollection but spared familiarity in patients with extended hippocampal system damage revealed by 3 convergent methods.Proc Natl Acad Sci U S A. 2009 Mar 31;106(13):5442-7. doi: 10.1073/pnas.0812097106. Epub 2009 Mar 16. Proc Natl Acad Sci U S A. 2009. PMID: 19289844 Free PMC article.
-
Storage, recall, and novelty detection of sequences by the hippocampus: elaborating on the SOCRATIC model to account for normal and aberrant effects of dopamine.Hippocampus. 2001;11(5):551-68. doi: 10.1002/hipo.1071. Hippocampus. 2001. PMID: 11732708 Review.
-
Recollection and familiarity in aging individuals with mild cognitive impairment and Alzheimer's disease: a literature review.Neuropsychol Rev. 2014 Sep;24(3):313-31. doi: 10.1007/s11065-014-9265-6. Epub 2014 Aug 13. Neuropsychol Rev. 2014. PMID: 25115809 Review.
Cited by
-
A scoping review of mathematical models covering Alzheimer's disease progression.Front Neuroinform. 2024 Mar 14;18:1281656. doi: 10.3389/fninf.2024.1281656. eCollection 2024. Front Neuroinform. 2024. PMID: 38550514 Free PMC article.
References
-
- Amit D. J. (1990). Modeling brain function: The world of attractor neural networks. Trends Neurosci. 13 357–358. 10.1016/0166-2236(90)90155-4 - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Research Materials