

Reinforcement learning establishes a minimal metacognitive process to monitor and control motor learning performance
- PMID: 37422476
- PMCID: PMC10329706
- DOI: 10.1038/s41467-023-39536-9
Reinforcement learning establishes a minimal metacognitive process to monitor and control motor learning performance
Abstract
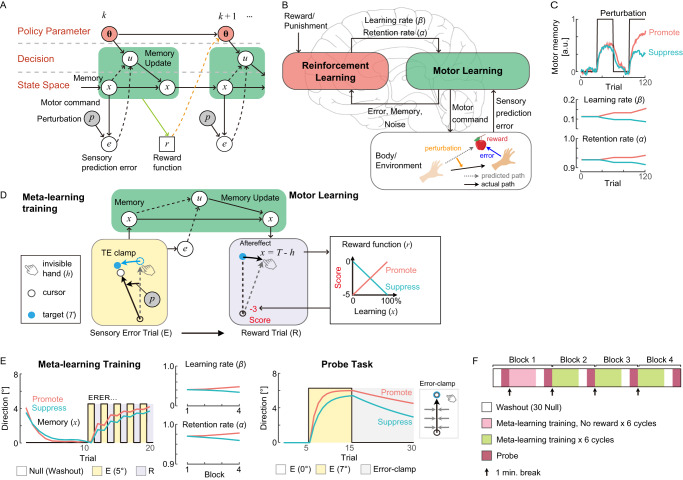
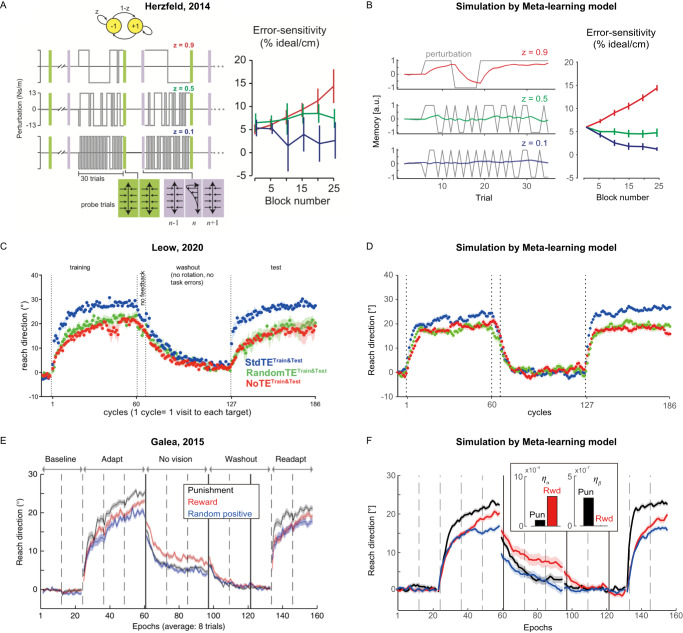
Humans and animals develop learning-to-learn strategies throughout their lives to accelerate learning. One theory suggests that this is achieved by a metacognitive process of controlling and monitoring learning. Although such learning-to-learn is also observed in motor learning, the metacognitive aspect of learning regulation has not been considered in classical theories of motor learning. Here, we formulated a minimal mechanism of this process as reinforcement learning of motor learning properties, which regulates a policy for memory update in response to sensory prediction error while monitoring its performance. This theory was confirmed in human motor learning experiments, in which the subjective sense of learning-outcome association determined the direction of up- and down-regulation of both learning speed and memory retention. Thus, it provides a simple, unifying account for variations in learning speeds, where the reinforcement learning mechanism monitors and controls the motor learning process.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures


Similar articles
-
From internal models toward metacognitive AI.Biol Cybern. 2021 Oct;115(5):415-430. doi: 10.1007/s00422-021-00904-7. Biol Cybern. 2021. PMID: 34677628 Free PMC article.
-
Interactions between motor exploration and reinforcement learning.J Neurophysiol. 2019 Aug 1;122(2):797-808. doi: 10.1152/jn.00390.2018. Epub 2019 Jun 26. J Neurophysiol. 2019. PMID: 31242063 Free PMC article.
-
Metacognitive judgments during visuomotor learning reflect the integration of error history.J Neurophysiol. 2023 Aug 1;130(2):264-277. doi: 10.1152/jn.00022.2023. Epub 2023 Jun 28. J Neurophysiol. 2023. PMID: 37377281
-
Measuring Metacognitive Knowledge, Monitoring, and Control in the Pharmacy Classroom and Experiential Settings.Am J Pharm Educ. 2020 May;84(5):7730. doi: 10.5688/ajpe7730. Am J Pharm Educ. 2020. PMID: 32577037 Free PMC article. Review.
-
Metacognitive resources for adaptive learning⋆.Neurosci Res. 2022 May;178:10-19. doi: 10.1016/j.neures.2021.09.003. Epub 2021 Sep 15. Neurosci Res. 2022. PMID: 34534617 Review.
Cited by
-
Motor synergy and energy efficiency emerge in whole-body locomotion learning.Sci Rep. 2025 Jan 3;15(1):712. doi: 10.1038/s41598-024-82472-x. Sci Rep. 2025. PMID: 39753645 Free PMC article.
-
The effects of reward and punishment on the performance of ping-pong ball bouncing.Front Behav Neurosci. 2024 Jun 27;18:1433649. doi: 10.3389/fnbeh.2024.1433649. eCollection 2024. Front Behav Neurosci. 2024. PMID: 38993267 Free PMC article.
-
Exploring motor skill acquisition in bimanual coordination: insights from navigating a novel maze task.Sci Rep. 2024 Aug 14;14(1):18887. doi: 10.1038/s41598-024-69200-1. Sci Rep. 2024. PMID: 39143119 Free PMC article.
-
Meta-learning of human motor adaptation via the dorsal premotor cortex.Proc Natl Acad Sci U S A. 2024 Oct 29;121(44):e2417543121. doi: 10.1073/pnas.2417543121. Epub 2024 Oct 23. Proc Natl Acad Sci U S A. 2024. PMID: 39441634 Free PMC article.
-
Learning-to-learn as a metacognitive correlate of functional outcomes after stroke: a cohort study.Eur J Phys Rehabil Med. 2024 Oct;60(5):750-760. doi: 10.23736/S1973-9087.24.08446-6. Epub 2024 Jul 29. Eur J Phys Rehabil Med. 2024. PMID: 39073359 Free PMC article.
References
-
- Colthorpe K, Sharifirad T, Ainscough L, Anderson S, Zimbardi K. Prompting undergraduate students’ metacognition of learning: implementing “meta-learning’ assessment tasks in the biomedical sciences. Assess. Eval. High. Edu. 2018;43:272–285. doi: 10.1080/02602938.2017.1334872. - DOI
-
- Derry SJ, Murphy DA. Designing systems that train learning-ability - from theory to practice. Rev. Educ. Res. 1986;56:1–39. doi: 10.3102/00346543056001001. - DOI
-
- Anne Pirrie A, Thoutenhoofd E. Learning to learn in the European Reference Framework for lifelong learning. Oxf. Rev. Educ. 2013;39:609–626. doi: 10.1080/03054985.2013.840280. - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
