

Vision transformer architecture and applications in digital health: a tutorial and survey
- PMID: 37428360
- PMCID: PMC10333157
- DOI: 10.1186/s42492-023-00140-9
Vision transformer architecture and applications in digital health: a tutorial and survey
Abstract
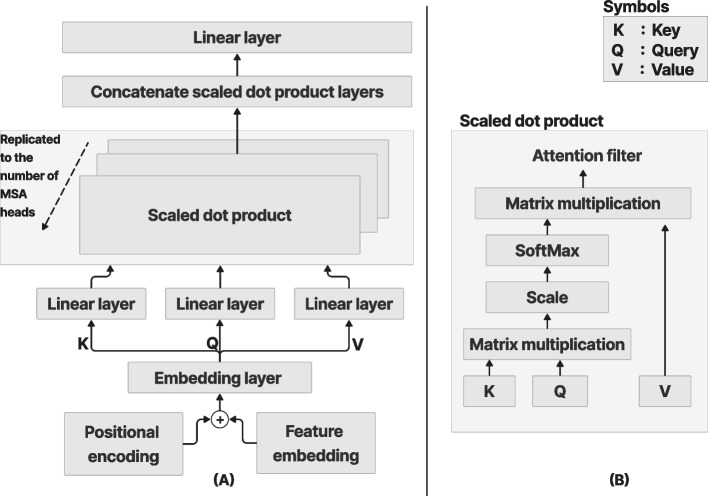
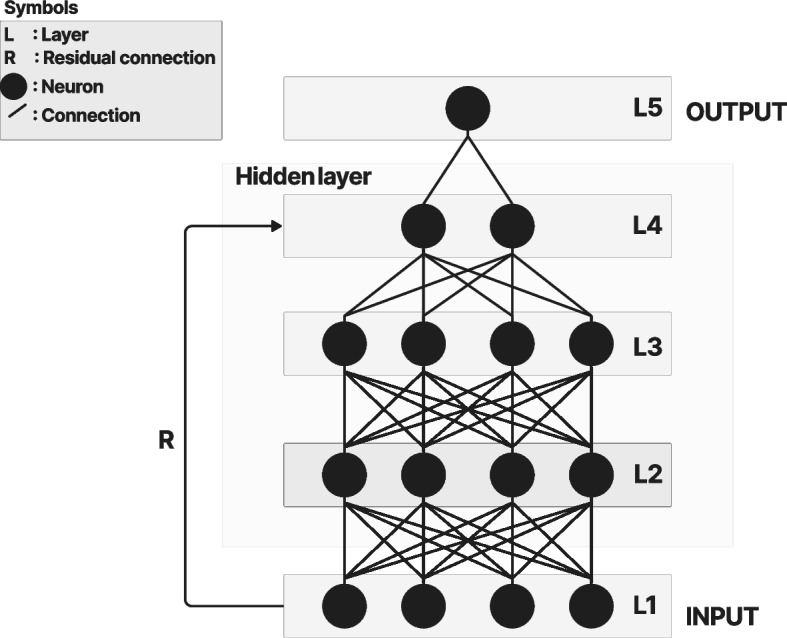
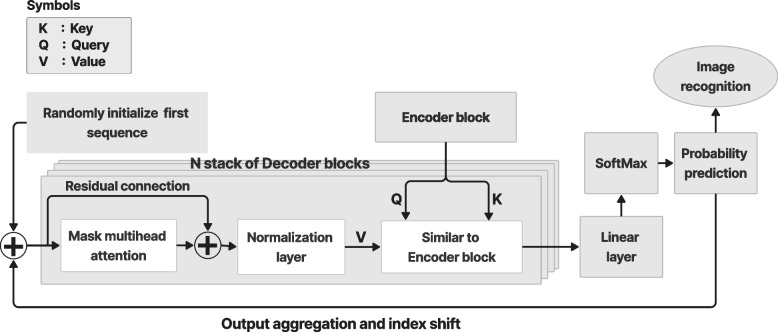
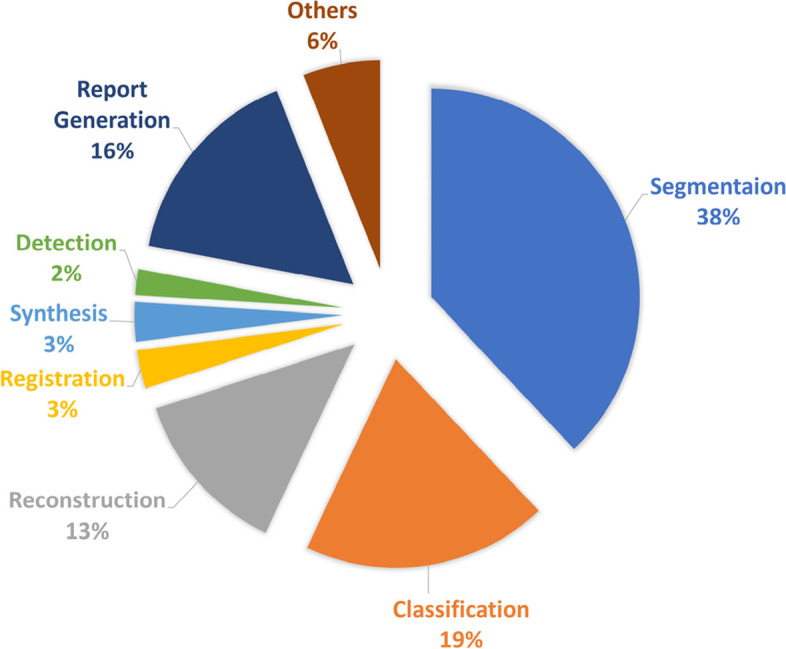
The vision transformer (ViT) is a state-of-the-art architecture for image recognition tasks that plays an important role in digital health applications. Medical images account for 90% of the data in digital medicine applications. This article discusses the core foundations of the ViT architecture and its digital health applications. These applications include image segmentation, classification, detection, prediction, reconstruction, synthesis, and telehealth such as report generation and security. This article also presents a roadmap for implementing the ViT in digital health systems and discusses its limitations and challenges.
Keywords: Artificial intelligence; Digital health; Medical imaging; Telehealth; Vision transformer.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing financial or non-financial interests.
Figures



Similar articles
-
Skin Cancer Segmentation and Classification Using Vision Transformer for Automatic Analysis in Dermatoscopy-Based Noninvasive Digital System.Int J Biomed Imaging. 2024 Feb 3;2024:3022192. doi: 10.1155/2024/3022192. eCollection 2024. Int J Biomed Imaging. 2024. PMID: 38344227 Free PMC article.
-
Classification of Mobile-Based Oral Cancer Images Using the Vision Transformer and the Swin Transformer.Cancers (Basel). 2024 Feb 29;16(5):987. doi: 10.3390/cancers16050987. Cancers (Basel). 2024. PMID: 38473348 Free PMC article.
-
IEViT: An enhanced vision transformer architecture for chest X-ray image classification.Comput Methods Programs Biomed. 2022 Nov;226:107141. doi: 10.1016/j.cmpb.2022.107141. Epub 2022 Sep 16. Comput Methods Programs Biomed. 2022. PMID: 36162246
-
Ultrasound Image Analysis with Vision Transformers-Review.Diagnostics (Basel). 2024 Mar 4;14(5):542. doi: 10.3390/diagnostics14050542. Diagnostics (Basel). 2024. PMID: 38473014 Free PMC article. Review.
-
Do it the transformer way: A comprehensive review of brain and vision transformers for autism spectrum disorder diagnosis and classification.Comput Biol Med. 2023 Dec;167:107667. doi: 10.1016/j.compbiomed.2023.107667. Epub 2023 Nov 3. Comput Biol Med. 2023. PMID: 37939407 Review.
Cited by
-
Metaheuristic optimizers integrated with vision transformer model for severity detection and classification via multimodal COVID-19 images.Sci Rep. 2025 Apr 22;15(1):13941. doi: 10.1038/s41598-025-98593-w. Sci Rep. 2025. PMID: 40263404 Free PMC article.
-
Multi-task approach based on combined CNN-transformer for efficient segmentation and classification of breast tumors in ultrasound images.Vis Comput Ind Biomed Art. 2024 Jan 26;7(1):2. doi: 10.1186/s42492-024-00155-w. Vis Comput Ind Biomed Art. 2024. PMID: 38273164 Free PMC article.
-
Deep Learning for 3D Vascular Segmentation in Phase Contrast Tomography.Res Sq [Preprint]. 2024 Jul 16:rs.3.rs-4613439. doi: 10.21203/rs.3.rs-4613439/v1. Res Sq. 2024. Update in: Sci Rep. 2024 Nov 8;14(1):27258. doi: 10.1038/s41598-024-77582-5. PMID: 39070623 Free PMC article. Updated. Preprint.
-
How Artificial Intelligence Is Shaping Medical Imaging Technology: A Survey of Innovations and Applications.Bioengineering (Basel). 2023 Dec 18;10(12):1435. doi: 10.3390/bioengineering10121435. Bioengineering (Basel). 2023. PMID: 38136026 Free PMC article. Review.
-
ViT-PSO-SVM: Cervical Cancer Predication Based on Integrating Vision Transformer with Particle Swarm Optimization and Support Vector Machine.Bioengineering (Basel). 2024 Jul 18;11(7):729. doi: 10.3390/bioengineering11070729. Bioengineering (Basel). 2024. PMID: 39061811 Free PMC article.
References
-
- Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai XH, Unterthiner T et al (2021) An image is worth 16x16 words: transformers for image recognition at scale. In: Proceedings of the 9th international conference on learning representations, OpenReview.net, Vienna, 3-7 May 2021
-
- Zhang QM, Xu YF, Zhang J, Tao DC. ViTAEv2: vision transformer advanced by exploring inductive bias for image recognition and beyond. Int J Comput Vis. 2023;131(5):1141–1162. doi: 10.1007/s11263-022-01739-w. - DOI
-
- Wang RS, Lei T, Cui RX, Zhang BT, Meng HY, Nandi AK. Medical image segmentation using deep learning: a survey. IET Image Process. 2022;16(5):1243–1267. doi: 10.1049/ipr2.12419. - DOI
-
- Bai WJ, Suzuki H, Qin C, Tarroni G, Oktay O, Matthews PM et al (2018) Recurrent neural networks for aortic image sequence segmentation with sparse annotations. In: Frangi AF, Schnabel JA, Davatzikos C, Alberola-López C, Fichtinger G (eds) Medical image computing and computer assisted intervention. 21st international conference, Granada, September 2018. Lecture notes in computer science (Image processing, computer vision, pattern recognition, and graphics), vol 11073. Springer, Cham, pp 586-594. 10.1007/978-3-030-00937-3_67
Publication types
LinkOut - more resources
Full Text Sources