

Counting pseudoalignments to novel splicing events
- PMID: 37432342
- PMCID: PMC10348833
- DOI: 10.1093/bioinformatics/btad419
Counting pseudoalignments to novel splicing events
Abstract
Motivation: Alternative splicing (AS) of introns from pre-mRNA produces diverse sets of transcripts across cell types and tissues, but is also dysregulated in many diseases. Alignment-free computational methods have greatly accelerated the quantification of mRNA transcripts from short RNA-seq reads, but they inherently rely on a catalog of known transcripts and might miss novel, disease-specific splicing events. By contrast, alignment of reads to the genome can effectively identify novel exonic segments and introns. Event-based methods then count how many reads align to predefined features. However, an alignment is more expensive to compute and constitutes a bottleneck in many AS analysis methods.
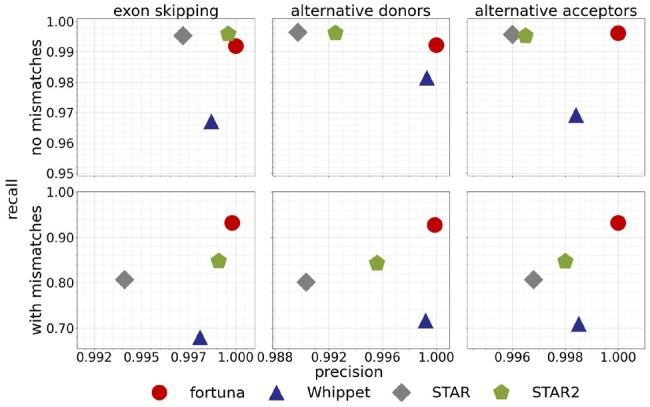
Results: Here, we propose fortuna, a method that guesses novel combinations of annotated splice sites to create transcript fragments. It then pseudoaligns reads to fragments using kallisto and efficiently derives counts of the most elementary splicing units from kallisto's equivalence classes. These counts can be directly used for AS analysis or summarized to larger units as used by other widely applied methods. In experiments on synthetic and real data, fortuna was around 7× faster than traditional align and count approaches, and was able to analyze almost 300 million reads in just 15 min when using four threads. It mapped reads containing mismatches more accurately across novel junctions and found more reads supporting aberrant splicing events in patients with autism spectrum disorder than existing methods. We further used fortuna to identify novel, tissue-specific splicing events in Drosophila.
Availability and implementation: fortuna source code is available at https://github.com/canzarlab/fortuna.
© The Author(s) 2023. Published by Oxford University Press.
Conflict of interest statement
None declared.
Figures





References
-
- Bray NL, Pimentel H, Melsted P et al. Near-optimal probabilistic RNA-seq quantification. Nat Biotechnol 2016;34:525–7. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Medical
Molecular Biology Databases
Research Materials
