

Extended performance analysis of deep-learning algorithms for mice vocalization segmentation
- PMID: 37433808
- PMCID: PMC10336146
- DOI: 10.1038/s41598-023-38186-7
Extended performance analysis of deep-learning algorithms for mice vocalization segmentation
Abstract
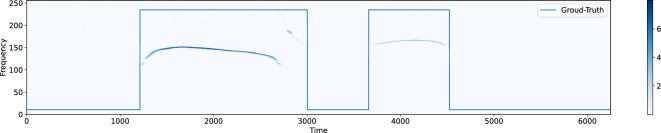
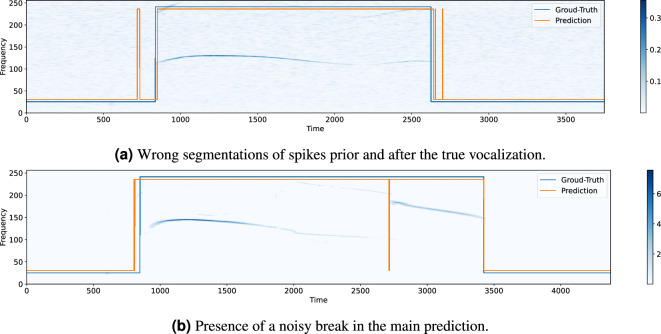
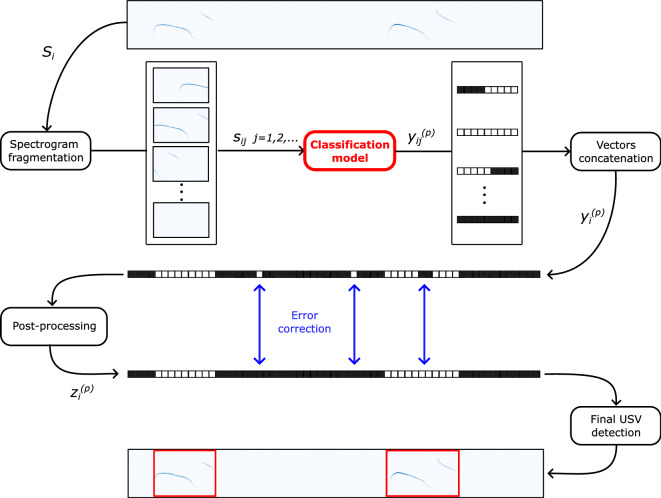
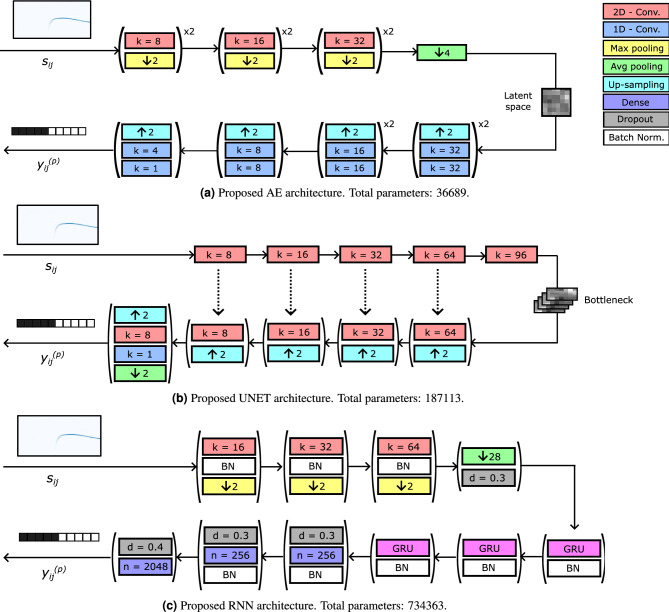
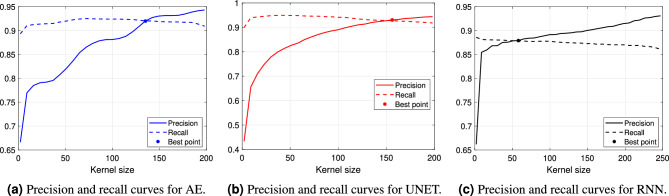
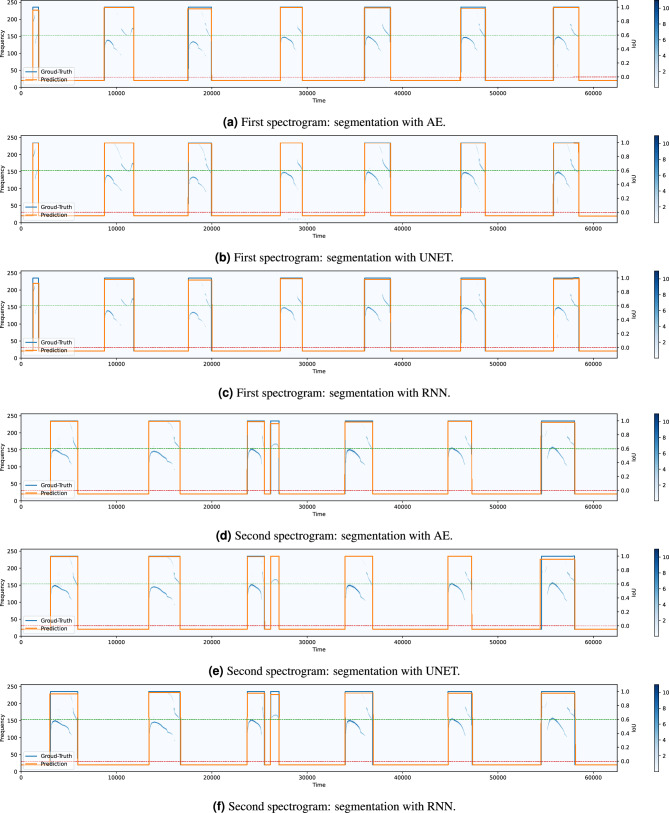
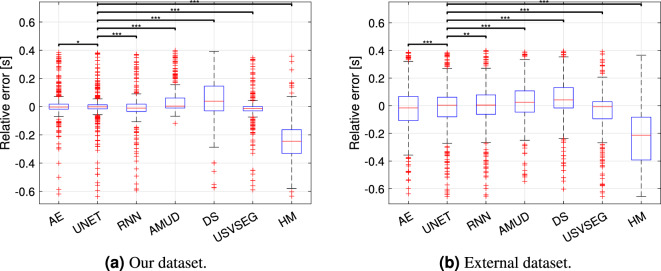
Ultrasonic vocalizations (USVs) analysis represents a fundamental tool to study animal communication. It can be used to perform a behavioral investigation of mice for ethological studies and in the field of neuroscience and neuropharmacology. The USVs are usually recorded with a microphone sensitive to ultrasound frequencies and then processed by specific software, which help the operator to identify and characterize different families of calls. Recently, many automated systems have been proposed for automatically performing both the detection and the classification of the USVs. Of course, the USV segmentation represents the crucial step for the general framework, since the quality of the call processing strictly depends on how accurately the call itself has been previously detected. In this paper, we investigate the performance of three supervised deep learning methods for automated USV segmentation: an Auto-Encoder Neural Network (AE), a U-NET Neural Network (UNET) and a Recurrent Neural Network (RNN). The proposed models receive as input the spectrogram associated with the recorded audio track and return as output the regions in which the USV calls have been detected. To evaluate the performance of the models, we have built a dataset by recording several audio tracks and manually segmenting the corresponding USV spectrograms generated with the Avisoft software, producing in this way the ground-truth (GT) used for training. All three proposed architectures demonstrated precision and recall scores exceeding [Formula: see text], with UNET and AE achieving values above [Formula: see text], surpassing other state-of-the-art methods that were considered for comparison in this study. Additionally, the evaluation was extended to an external dataset, where UNET once again exhibited the highest performance. We suggest that our experimental results may represent a valuable benchmark for future works.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures



References
-
- Zippelius HM, Schleidt WM. Ultraschall-laute bei jungen mause. Naturwissenschaften. 1956;43:502–502. doi: 10.1007/BF00632534. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
