

Latent neural dynamics encode temporal context in speech
- PMID: 37441880
- PMCID: PMC11182421
- DOI: 10.1016/j.heares.2023.108838
Latent neural dynamics encode temporal context in speech
Abstract
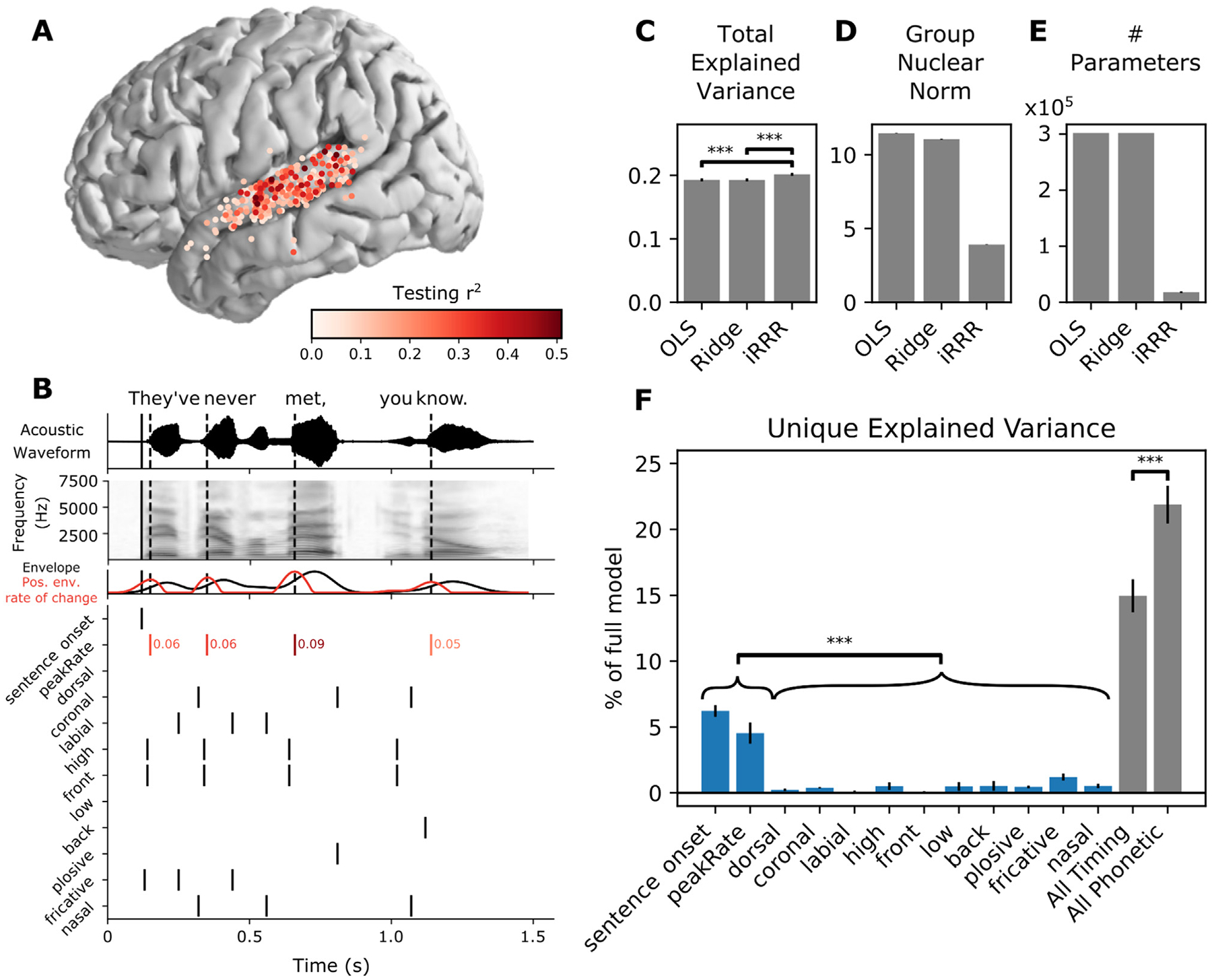
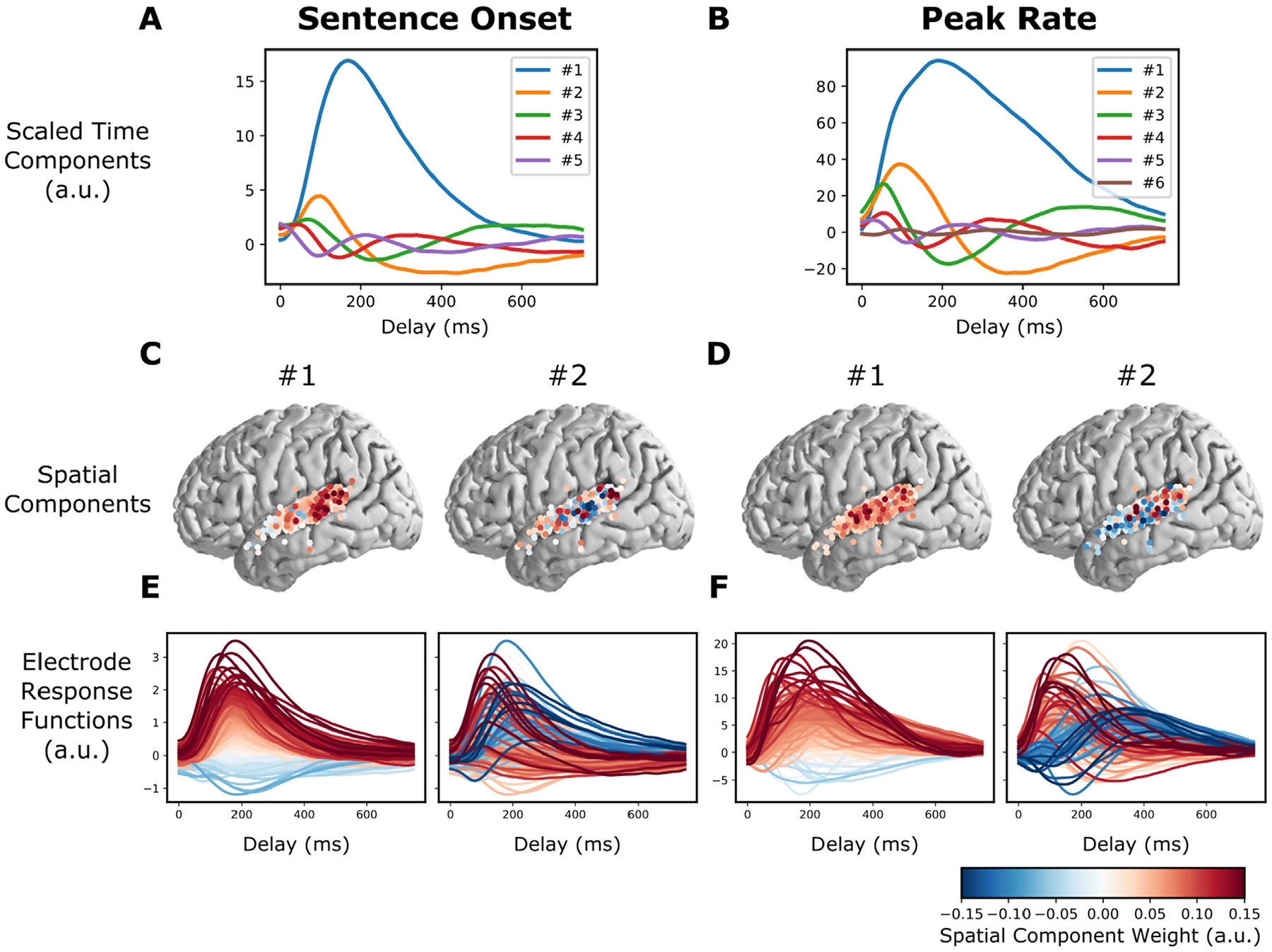
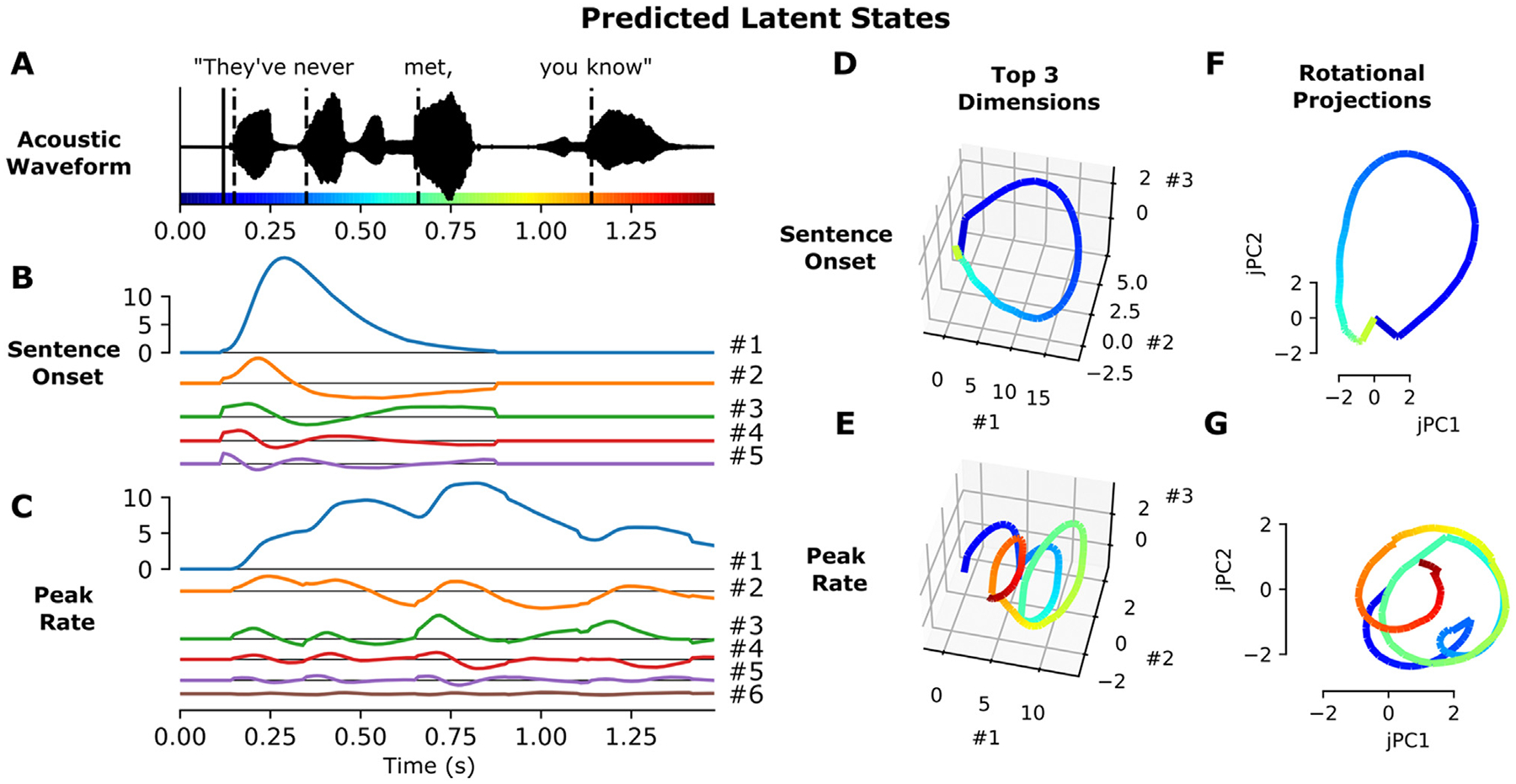
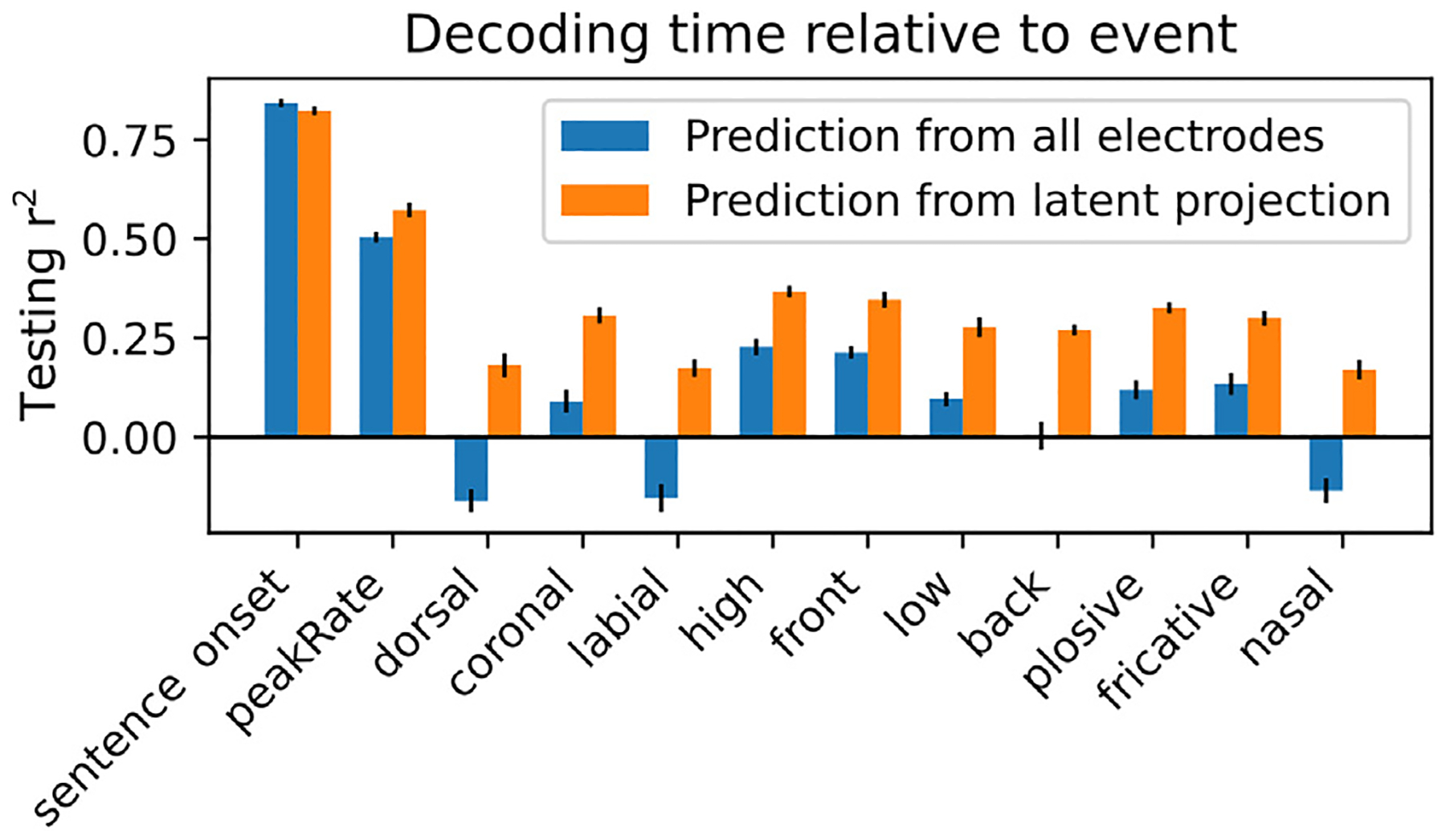
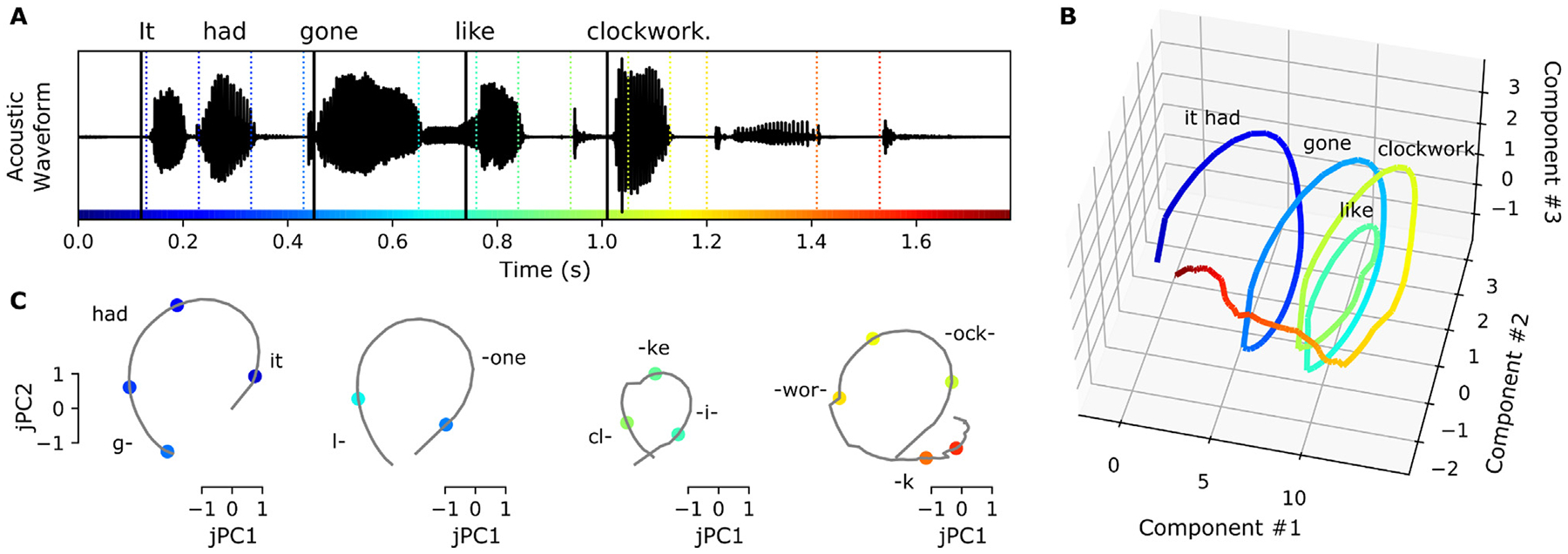
Direct neural recordings from human auditory cortex have demonstrated encoding for acoustic-phonetic features of consonants and vowels. Neural responses also encode distinct acoustic amplitude cues related to timing, such as those that occur at the onset of a sentence after a silent period or the onset of the vowel in each syllable. Here, we used a group reduced rank regression model to show that distributed cortical responses support a low-dimensional latent state representation of temporal context in speech. The timing cues each capture more unique variance than all other phonetic features and exhibit rotational or cyclical dynamics in latent space from activity that is widespread over the superior temporal gyrus. We propose that these spatially distributed timing signals could serve to provide temporal context for, and possibly bind across time, the concurrent processing of individual phonetic features, to compose higher-order phonological (e.g. word-level) representations.
Keywords: Auditory; Electrocorticography; Latent state; Reduced-rank regression; Superior temporal gyrus.
Copyright © 2023. Published by Elsevier B.V.
Conflict of interest statement
Declaration of Competing Interest The authors declare no competing interests.
Figures
References
-
- Antin B, Shenoy K, Linderman S, 2021. Probabilistic jPCA: a constrained model of neural dynamics, in: Cosyne Abstracts 2021. Presented at the Cosyne21, Online.
-
- Austern M and Zhou W, 2020. Asymptotics of cross-validation. arXiv preprint arXiv:2001.11111.
