

Research on Road Scene Understanding of Autonomous Vehicles Based on Multi-Task Learning
- PMID: 37448087
- PMCID: PMC10346996
- DOI: 10.3390/s23136238
Research on Road Scene Understanding of Autonomous Vehicles Based on Multi-Task Learning
Abstract
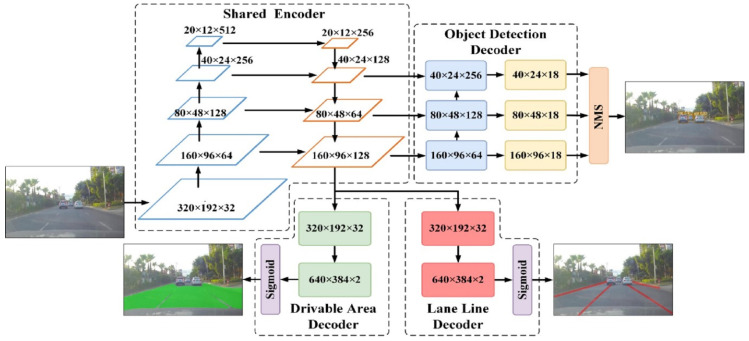
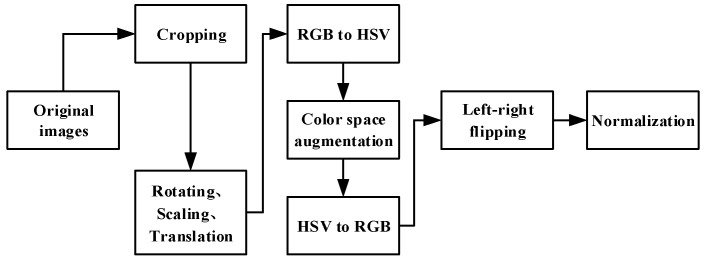
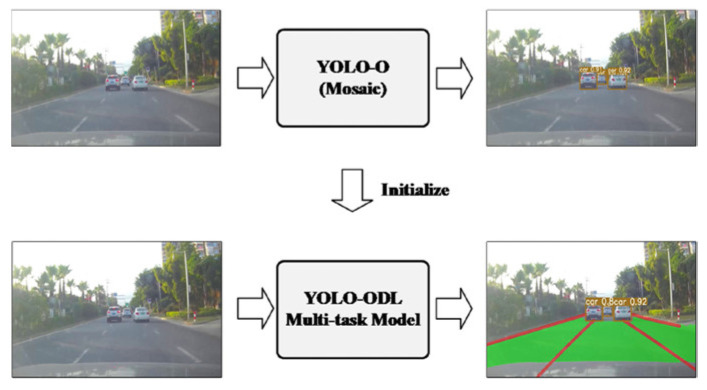
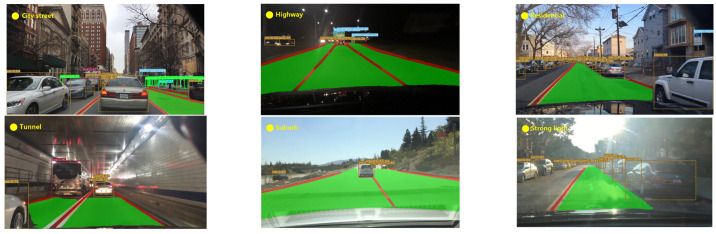
Road scene understanding is crucial to the safe driving of autonomous vehicles. Comprehensive road scene understanding requires a visual perception system to deal with a large number of tasks at the same time, which needs a perception model with a small size, fast speed, and high accuracy. As multi-task learning has evident advantages in performance and computational resources, in this paper, a multi-task model YOLO-Object, Drivable Area, and Lane Line Detection (YOLO-ODL) based on hard parameter sharing is proposed to realize joint and efficient detection of traffic objects, drivable areas, and lane lines. In order to balance tasks of YOLO-ODL, a weight balancing strategy is introduced so that the weight parameters of the model can be automatically adjusted during training, and a Mosaic migration optimization scheme is adopted to improve the evaluation indicators of the model. Our YOLO-ODL model performs well on the challenging BDD100K dataset, achieving the state of the art in terms of accuracy and computational efficiency.
Keywords: autonomous vehicles; drivable area detection; lane line detection; multi-task learning; traffic object detection; visual perception.
Conflict of interest statement
The authors declare no conflict of interest.
Figures





References
-
- Qian Y., Dolan J.M., Yang M. DLT-Net: Joint detection of drivable areas, lane lines, and traffic objects. IEEE Trans. Intell. Transp. Syst. (IVS) 2019;21:4670–4679. doi: 10.1109/TITS.2019.2943777. - DOI
-
- Teichmann M., Weber M., Zollner M., Cipolla R., Urtasun R. MultiNet: Real-time joint semantic reasoning for autonomous driving; Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV); Changshu, China. 26–30 June 2018; pp. 1013–1020.
-
- Sun Z., Bebis G., Miller R. On-road vehicle detection: A review. IEEE Trans. Pattern Anal. Mach. Intell. 2006;28:694–711. - PubMed
-
- Owais M. Traffic sensor location problem: Three decades of research. Expert Syst. Appl. 2022;208:118134. doi: 10.1016/j.eswa.2022.118134. - DOI
-
- Bhaggiaraj S., Priyadharsini M., Karuppasamy K., Snegha R. Deep Learning Based Self Driving Cars Using Computer Vision; Proceedings of the 2023 International Conference on Networking and Communications (ICNWC); Chennai, India. 5–6 April 2023; pp. 1–9.
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials
