

Next generation pan-cancer blood proteome profiling using proximity extension assay
- PMID: 37463882
- PMCID: PMC10354027
- DOI: 10.1038/s41467-023-39765-y
Next generation pan-cancer blood proteome profiling using proximity extension assay
Abstract
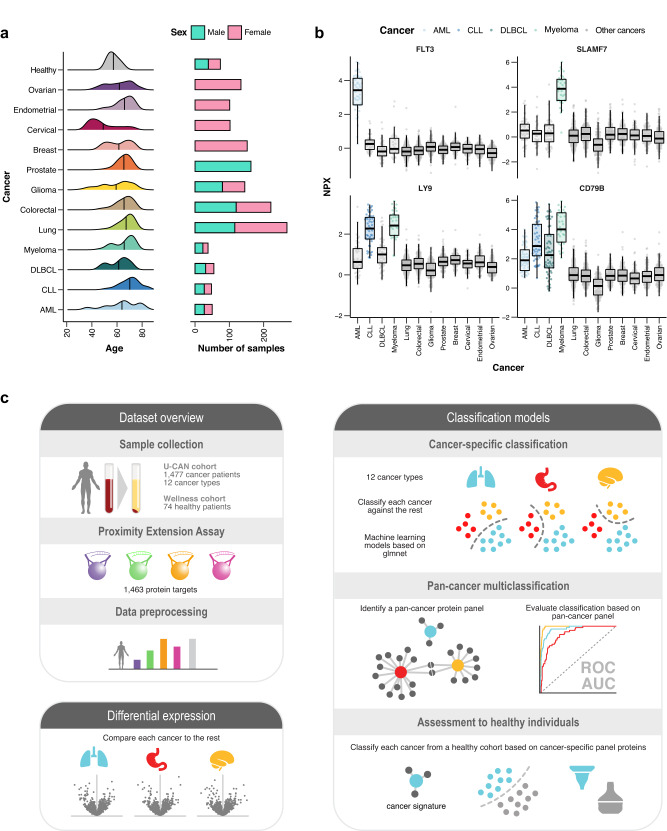
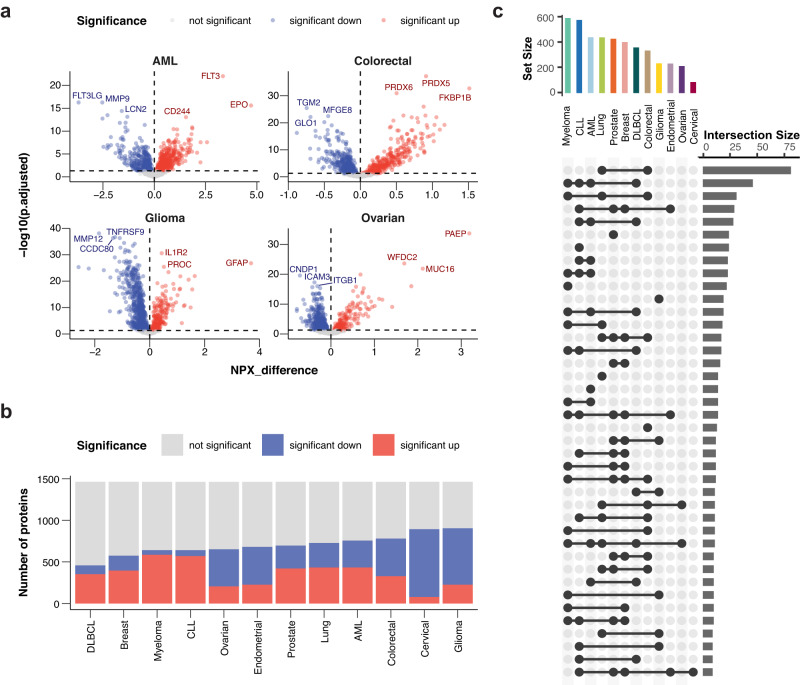
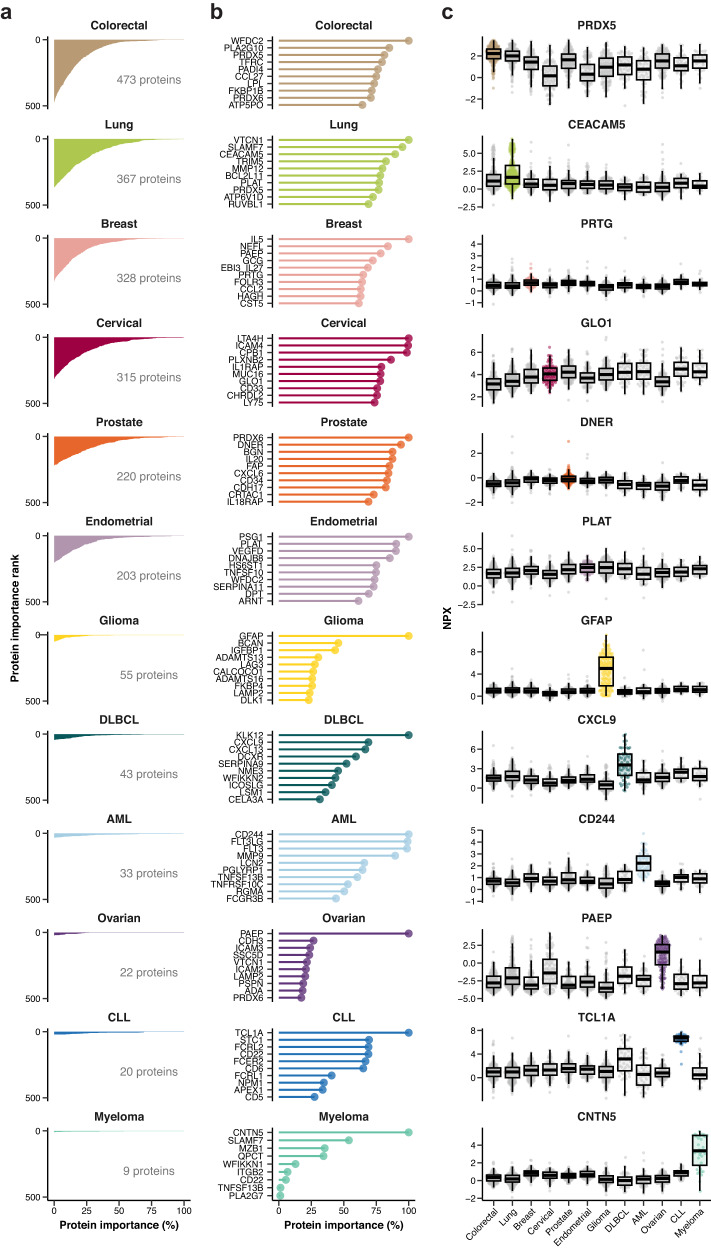
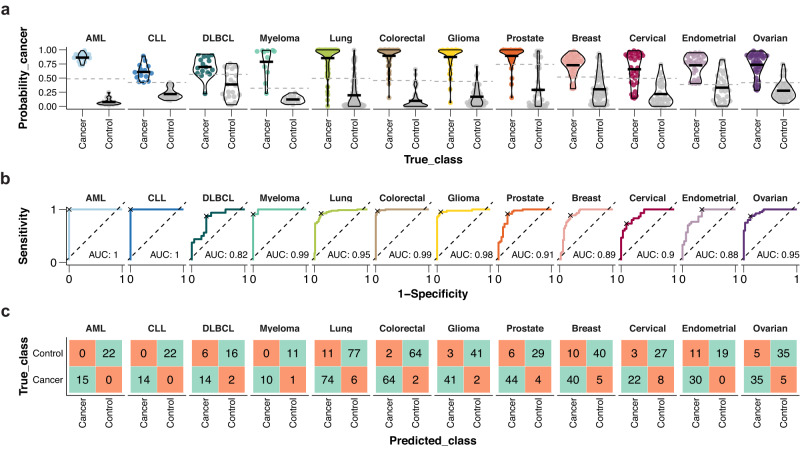
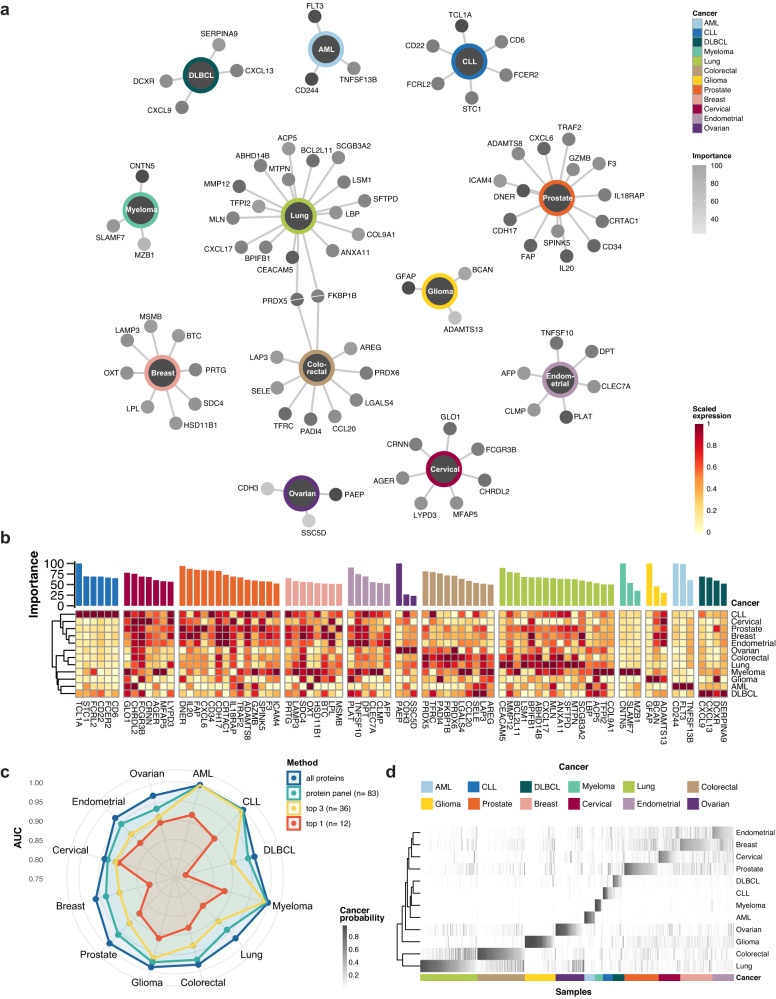
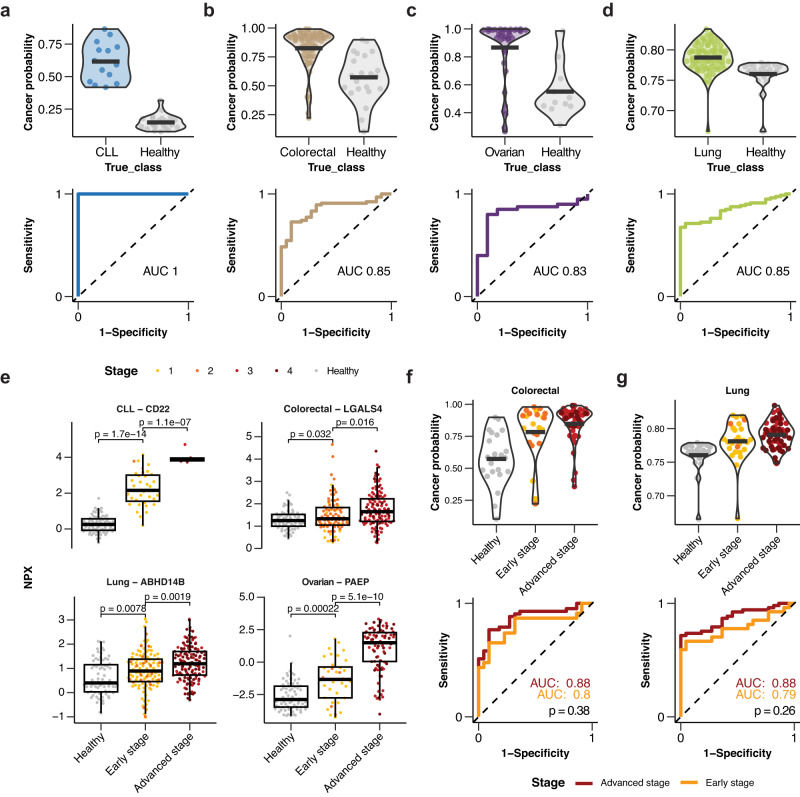
A comprehensive characterization of blood proteome profiles in cancer patients can contribute to a better understanding of the disease etiology, resulting in earlier diagnosis, risk stratification and better monitoring of the different cancer subtypes. Here, we describe the use of next generation protein profiling to explore the proteome signature in blood across patients representing many of the major cancer types. Plasma profiles of 1463 proteins from more than 1400 cancer patients are measured in minute amounts of blood collected at the time of diagnosis and before treatment. An open access Disease Blood Atlas resource allows the exploration of the individual protein profiles in blood collected from the individual cancer patients. We also present studies in which classification models based on machine learning have been used for the identification of a set of proteins associated with each of the analyzed cancers. The implication for cancer precision medicine of next generation plasma profiling is discussed.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Medical
