

Mega-scale experimental analysis of protein folding stability in biology and design
- PMID: 37468638
- PMCID: PMC10412457
- DOI: 10.1038/s41586-023-06328-6
Mega-scale experimental analysis of protein folding stability in biology and design
Abstract
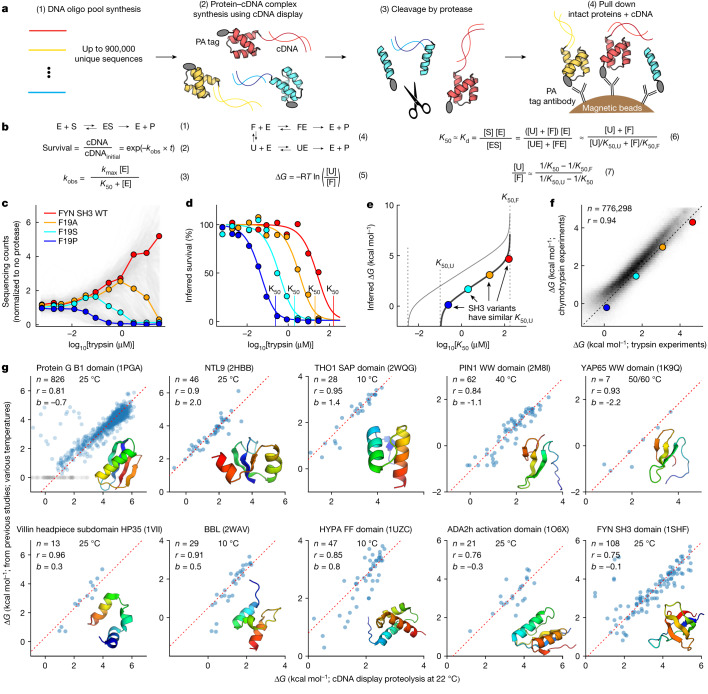
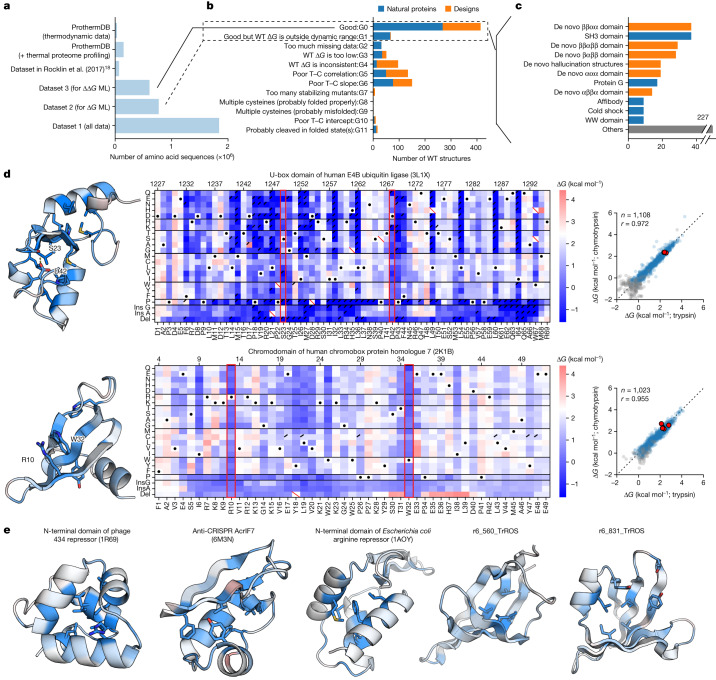
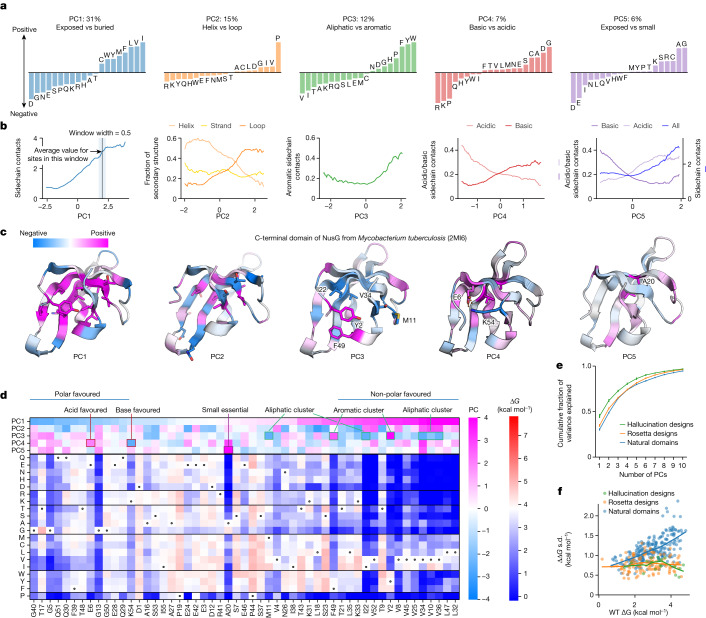
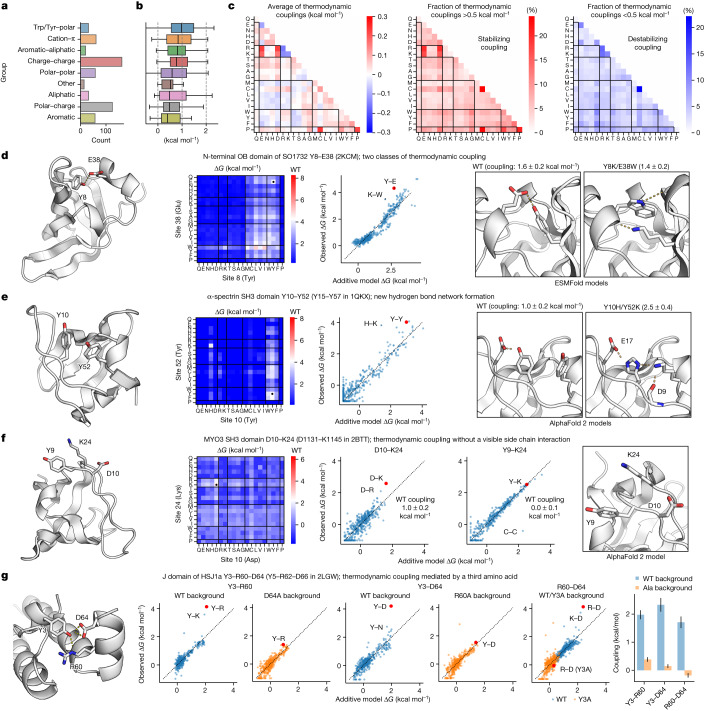
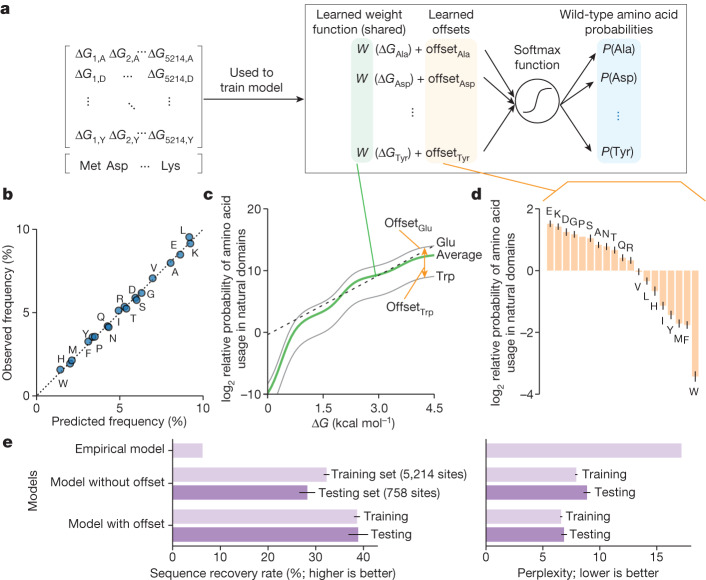
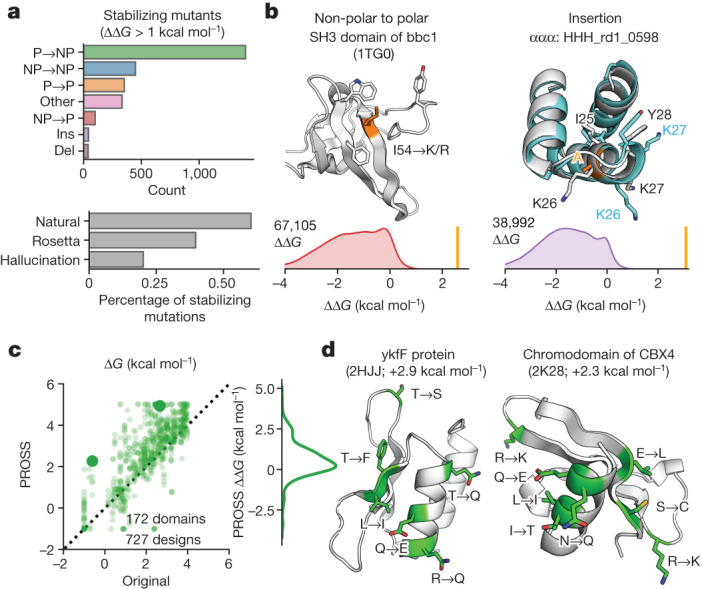
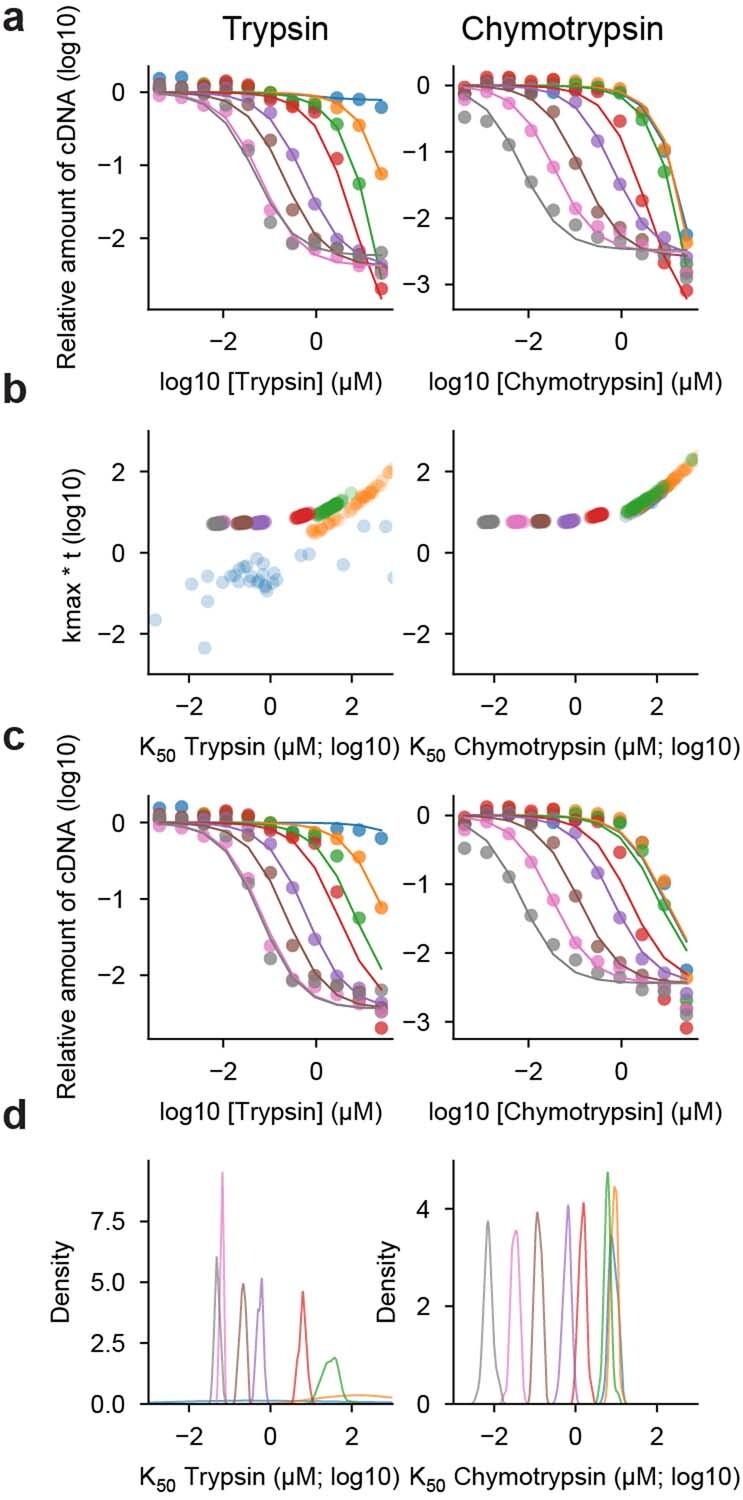
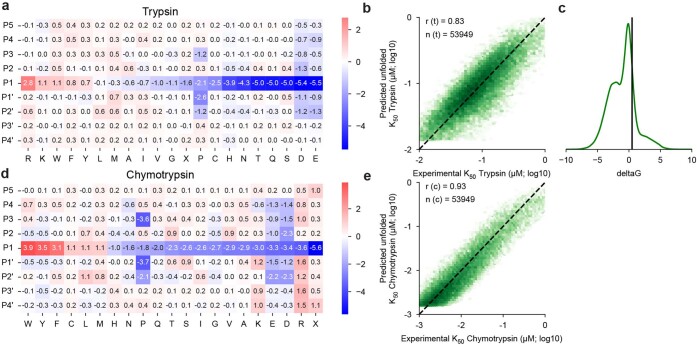
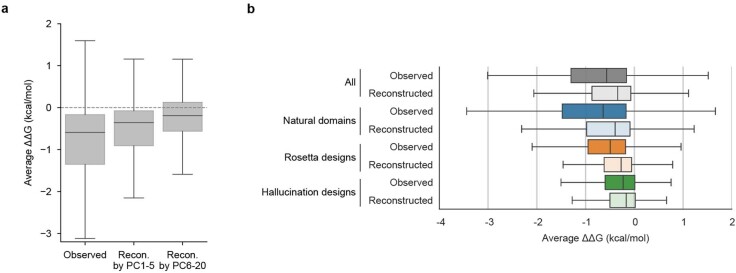
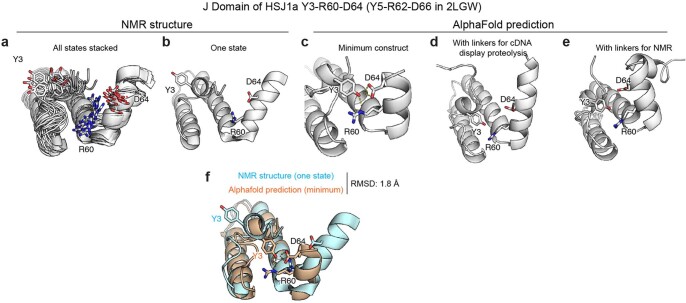
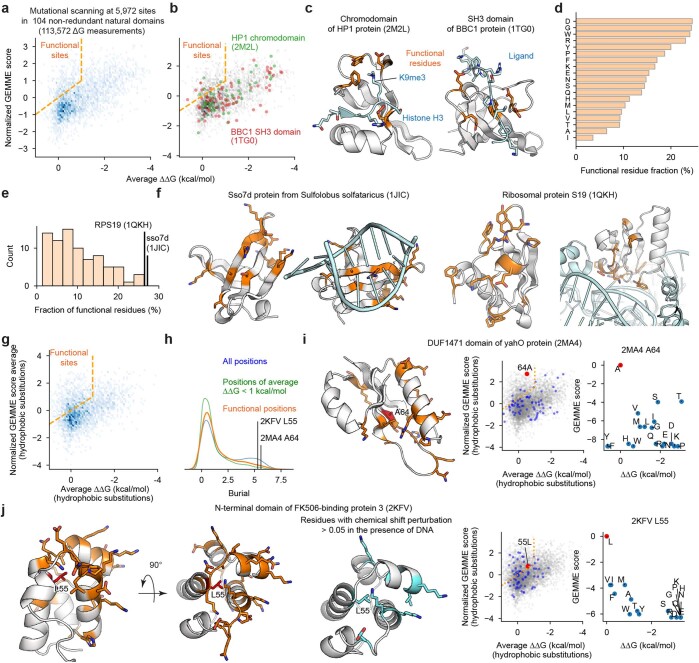
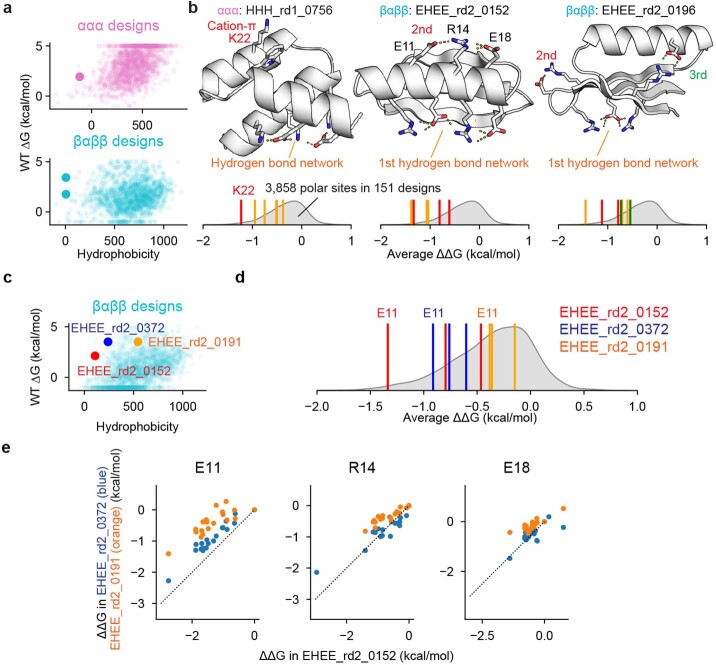
Advances in DNA sequencing and machine learning are providing insights into protein sequences and structures on an enormous scale1. However, the energetics driving folding are invisible in these structures and remain largely unknown2. The hidden thermodynamics of folding can drive disease3,4, shape protein evolution5-7 and guide protein engineering8-10, and new approaches are needed to reveal these thermodynamics for every sequence and structure. Here we present cDNA display proteolysis, a method for measuring thermodynamic folding stability for up to 900,000 protein domains in a one-week experiment. From 1.8 million measurements in total, we curated a set of around 776,000 high-quality folding stabilities covering all single amino acid variants and selected double mutants of 331 natural and 148 de novo designed protein domains 40-72 amino acids in length. Using this extensive dataset, we quantified (1) environmental factors influencing amino acid fitness, (2) thermodynamic couplings (including unexpected interactions) between protein sites, and (3) the global divergence between evolutionary amino acid usage and protein folding stability. We also examined how our approach could identify stability determinants in designed proteins and evaluate design methods. The cDNA display proteolysis method is fast, accurate and uniquely scalable, and promises to reveal the quantitative rules for how amino acid sequences encode folding stability.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures
References
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
