

Free viewing biases for complex scenes in preschoolers and adults
- PMID: 37479760
- PMCID: PMC10362043
- DOI: 10.1038/s41598-023-38854-8
Free viewing biases for complex scenes in preschoolers and adults
Abstract
Adult gaze behaviour towards naturalistic scenes is highly biased towards semantic object classes. Little is known about the ontological development of these biases, nor about group-level differences in gaze behaviour between adults and preschoolers. Here, we let preschoolers (n = 34, age 5 years) and adults (n = 42, age 18-59 years) freely view 40 complex scenes containing objects with different semantic attributes to compare their fixation behaviour. Results show that preschool children allocate a significantly smaller proportion of dwell time and first fixations on Text and instead fixate Faces, Touched objects, Hands and Bodies more. A predictive model of object fixations controlling for a range of potential confounds suggests that most of these differences can be explained by drastically reduced text salience in pre-schoolers and that this effect is independent of low-level salience. These findings are in line with a developmental attentional antagonism between text and body parts (touched objects and hands in particular), which resonates with recent findings regarding 'cortical recycling'. We discuss this and other potential mechanisms driving salience differences between children and adults.
© 2023. The Author(s).
Conflict of interest statement
The authors declare no competing interests.
Figures


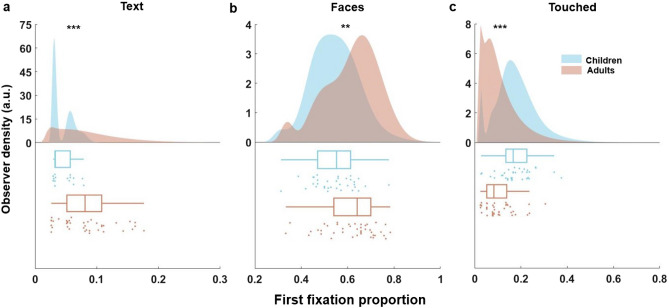


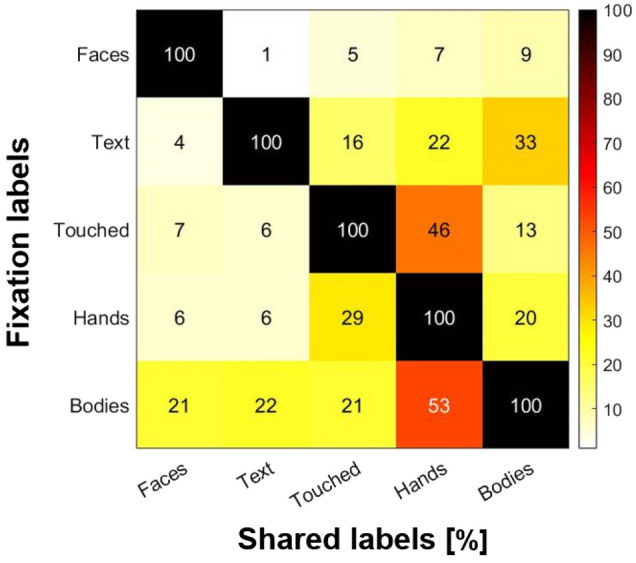
References
-
- Harel, J., Koch, C. & Perona, P. Graph-based visual saliency. Adv. Neural Inform. Process. Syst19 (2006).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
