

Quality indices for topic model selection and evaluation: a literature review and case study
- PMID: 37481523
- PMCID: PMC10362613
- DOI: 10.1186/s12911-023-02216-1
Quality indices for topic model selection and evaluation: a literature review and case study
Abstract
Background: Topic models are a class of unsupervised machine learning models, which facilitate summarization, browsing and retrieval from large unstructured document collections. This study reviews several methods for assessing the quality of unsupervised topic models estimated using non-negative matrix factorization. Techniques for topic model validation have been developed across disparate fields. We synthesize this literature, discuss the advantages and disadvantages of different techniques for topic model validation, and illustrate their usefulness for guiding model selection on a large clinical text corpus.
Design, setting and data: Using a retrospective cohort design, we curated a text corpus containing 382,666 clinical notes collected between 01/01/2017 through 12/31/2020 from primary care electronic medical records in Toronto Canada.
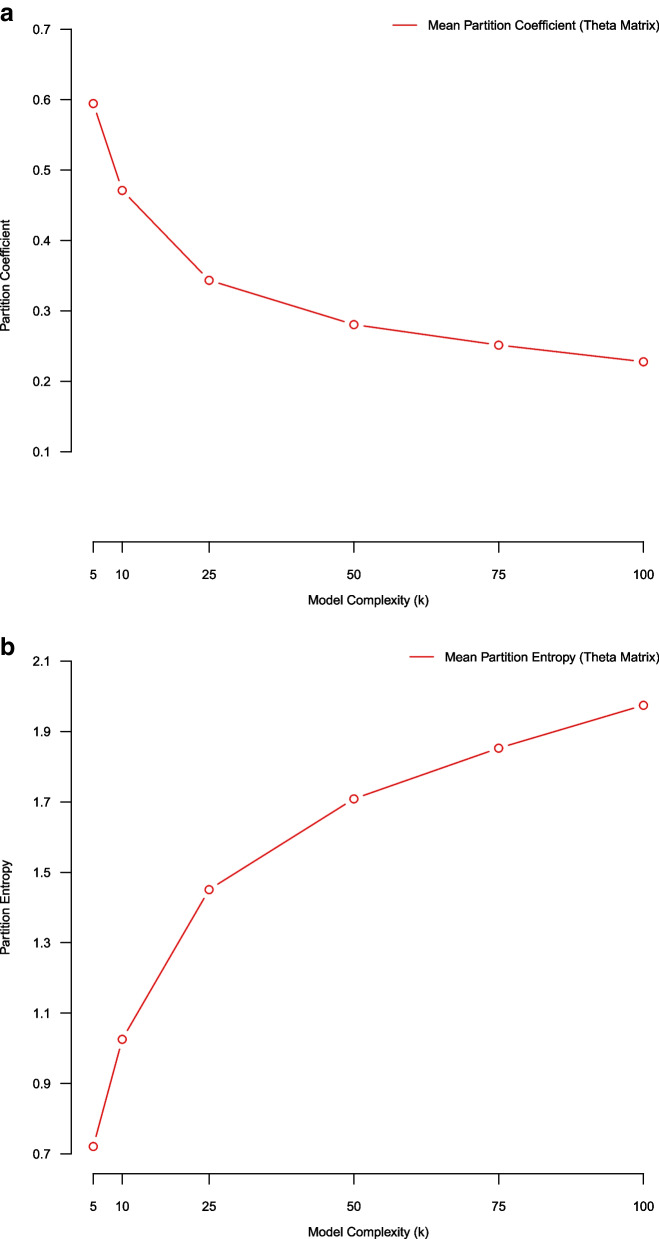
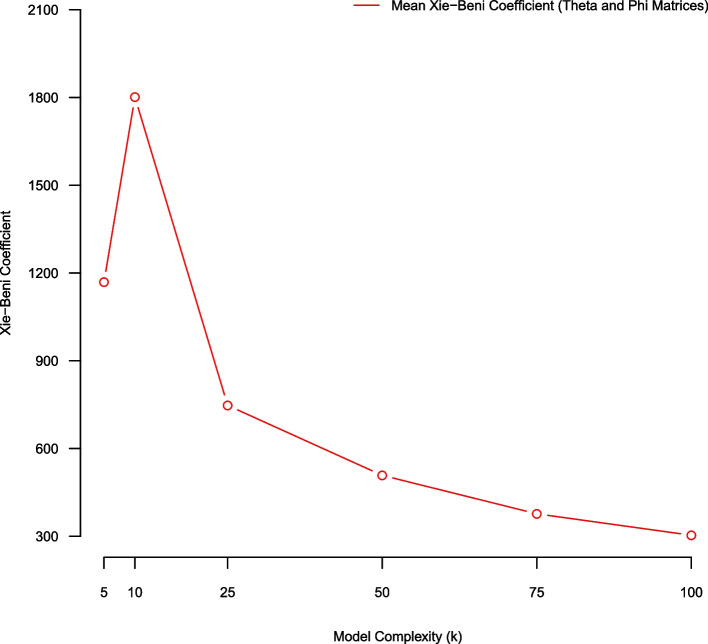
Methods: Several topic model quality metrics have been proposed to assess different aspects of model fit. We explored the following metrics: reconstruction error, topic coherence, rank biased overlap, Kendall's weighted tau, partition coefficient, partition entropy and the Xie-Beni statistic. Depending on context, cross-validation and/or bootstrap stability analysis were used to estimate these metrics on our corpus.
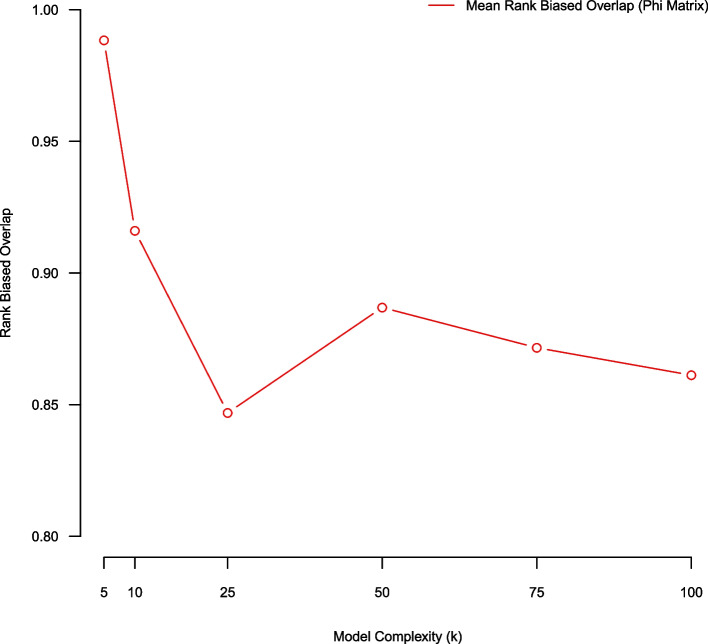
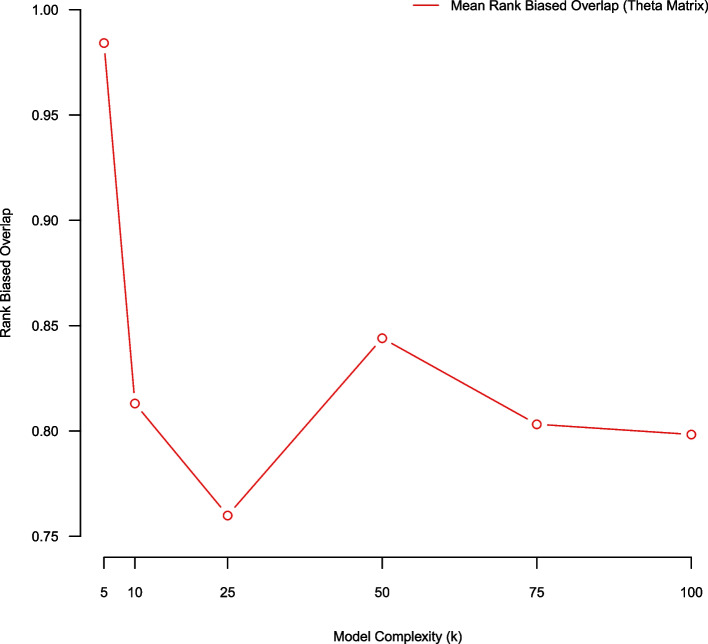
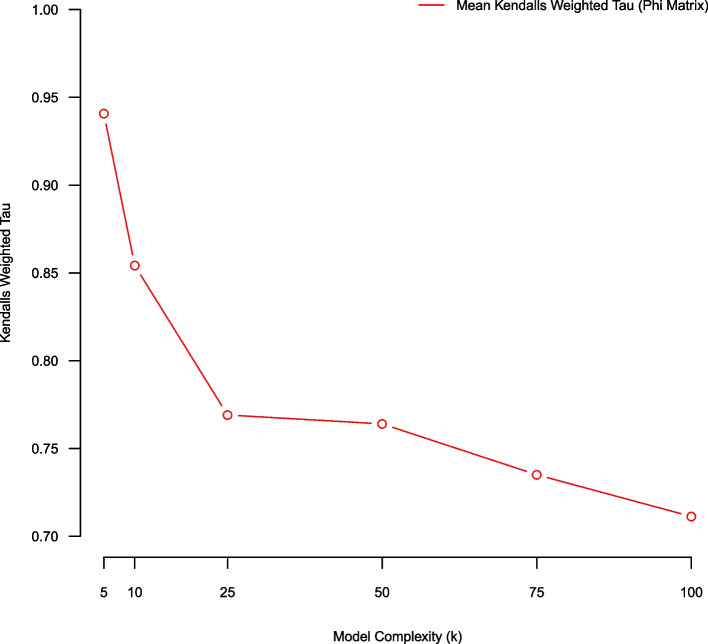
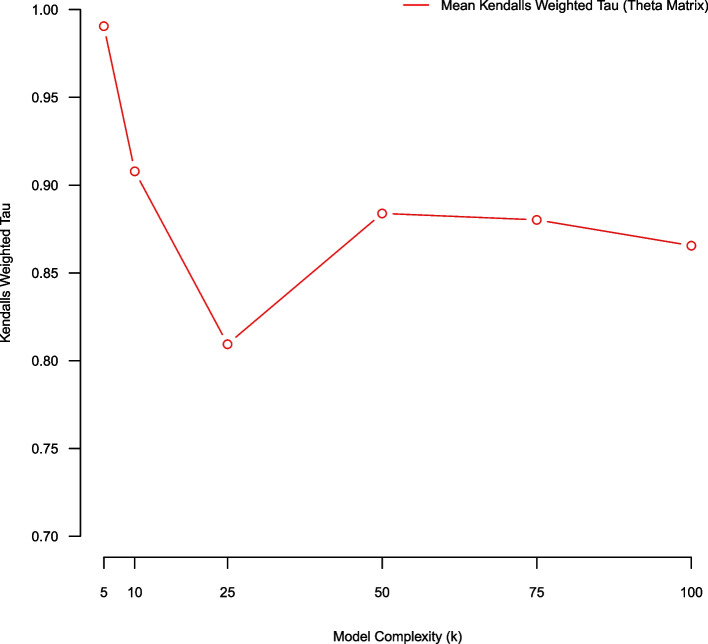
Results: Cross-validated reconstruction error favored large topic models (K ≥ 100 topics) on our corpus. Stability analysis using topic coherence and the Xie-Beni statistic also favored large models (K = 100 topics). Rank biased overlap and Kendall's weighted tau favored small models (K = 5 topics). Few model evaluation metrics suggested mid-sized topic models (25 ≤ K ≤ 75) as being optimal. However, human judgement suggested that mid-sized topic models produced expressive low-dimensional summarizations of the corpus.
Conclusions: Topic model quality indices are transparent quantitative tools for guiding model selection and evaluation. Our empirical illustration demonstrated that different topic model quality indices favor models of different complexity; and may not select models aligning with human judgment. This suggests that different metrics capture different aspects of model goodness of fit. A combination of topic model quality indices, coupled with human validation, may be useful in appraising unsupervised topic models.
Keywords: Clinical text data; Cross-validation; Electronic medical record; Internal validation; Non-negative matrix factorization; Stability analysis; Topic model.
© 2023. The Author(s).
Conflict of interest statement
The authors declare that they have no competing interests.
Figures


References
-
- Gentzkow M, Kelly B, Taddy M. Text as Data. Journal of Economic Literature. 2019;57:535–574. doi: 10.1257/jel.20181020. - DOI
-
- Berry M, Dumais S, O’Brien G. Using Linear Algebra for Intelligent Information Retrieval. SIAM Rev. 1995;37:573–595. doi: 10.1137/1037127. - DOI
-
- Landauer T, Dumais S. A Solution to Plato’s Problem: The Latent Semantic Analysis Theory of Acquisition, Induction, and Representation of Knowledge. Psychological Reviews. 1997;104:211–240. doi: 10.1037/0033-295X.104.2.211. - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
