

Manifold learning for fMRI time-varying functional connectivity
- PMID: 37497043
- PMCID: PMC10366614
- DOI: 10.3389/fnhum.2023.1134012
Manifold learning for fMRI time-varying functional connectivity
Abstract
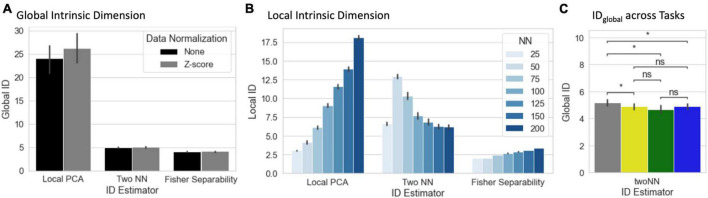
Whole-brain functional connectivity (FC) measured with functional MRI (fMRI) evolves over time in meaningful ways at temporal scales going from years (e.g., development) to seconds [e.g., within-scan time-varying FC (tvFC)]. Yet, our ability to explore tvFC is severely constrained by its large dimensionality (several thousands). To overcome this difficulty, researchers often seek to generate low dimensional representations (e.g., 2D and 3D scatter plots) hoping those will retain important aspects of the data (e.g., relationships to behavior and disease progression). Limited prior empirical work suggests that manifold learning techniques (MLTs)-namely those seeking to infer a low dimensional non-linear surface (i.e., the manifold) where most of the data lies-are good candidates for accomplishing this task. Here we explore this possibility in detail. First, we discuss why one should expect tvFC data to lie on a low dimensional manifold. Second, we estimate what is the intrinsic dimension (ID; i.e., minimum number of latent dimensions) of tvFC data manifolds. Third, we describe the inner workings of three state-of-the-art MLTs: Laplacian Eigenmaps (LEs), T-distributed Stochastic Neighbor Embedding (T-SNE), and Uniform Manifold Approximation and Projection (UMAP). For each method, we empirically evaluate its ability to generate neuro-biologically meaningful representations of tvFC data, as well as their robustness against hyper-parameter selection. Our results show that tvFC data has an ID that ranges between 4 and 26, and that ID varies significantly between rest and task states. We also show how all three methods can effectively capture subject identity and task being performed: UMAP and T-SNE can capture these two levels of detail concurrently, but LE could only capture one at a time. We observed substantial variability in embedding quality across MLTs, and within-MLT as a function of hyper-parameter selection. To help alleviate this issue, we provide heuristics that can inform future studies. Finally, we also demonstrate the importance of feature normalization when combining data across subjects and the role that temporal autocorrelation plays in the application of MLTs to tvFC data. Overall, we conclude that while MLTs can be useful to generate summary views of labeled tvFC data, their application to unlabeled data such as resting-state remains challenging.
Keywords: Laplacian Eigenmaps (LE); T-SNE; Uniform Manifold Approximation and Projection (UMAP); data visualization; fMRI; manifold learning; time-varying functional connectivity.
Copyright © 2023 Gonzalez-Castillo, Fernandez, Lam, Handwerker, Pereira and Bandettini.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figures









Update of
-
Manifold Learning for fMRI time-varying FC.bioRxiv [Preprint]. 2023 Jan 16:2023.01.14.523992. doi: 10.1101/2023.01.14.523992. bioRxiv. 2023. Update in: Front Hum Neurosci. 2023 Jul 11;17:1134012. doi: 10.3389/fnhum.2023.1134012. PMID: 36789436 Free PMC article. Updated. Preprint.
References
-
- Albergante L., Bac J., Zinovyev A. (2019). Estimating the effective dimension of large biological datasets using Fisher separability analysis. arXiv [Preprint]. 10.1109/ijcnn.2019.8852450 - DOI
-
- Amsaleg L., Bailey J., Barbe D., Erfani S., Houle M. E., Nguyen V., et al. (2017). “The Vulnerability of Learning to Adversarial Perturbation Increases with Intrinsic Dimensionality,” in Proceedings of the IEEE Workshop on Information Forensics and Security, Manhattan, NY, 10.1109/wifs.2017.8267651 - DOI
-
- Ansuini A., Laio A., Macke J. H., Zoccolan D. (2019). “Intrinsic dimension of data representations in deep neural networks,” in Proceedings of the Advances in Neural Information Processing Systems, Red Hook, NY.
Grants and funding
LinkOut - more resources
Full Text Sources