

Text-based predictions of COVID-19 diagnosis from self-reported chemosensory descriptions
- PMID: 37500763
- PMCID: PMC10374642
- DOI: 10.1038/s43856-023-00334-5
Text-based predictions of COVID-19 diagnosis from self-reported chemosensory descriptions
Abstract
Background: There is a prevailing view that humans' capacity to use language to characterize sensations like odors or tastes is poor, providing an unreliable source of information.
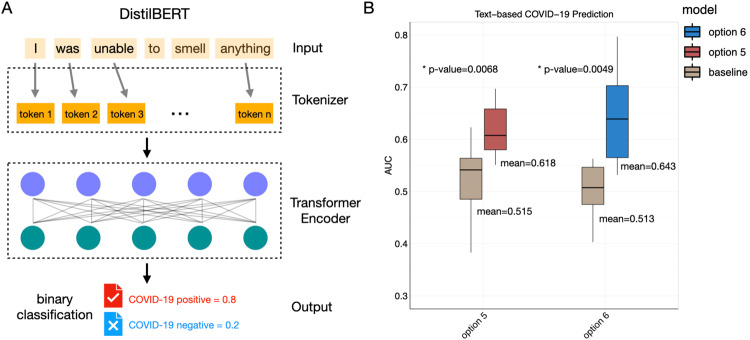
Methods: Here, we developed a machine learning method based on Natural Language Processing (NLP) using Large Language Models (LLM) to predict COVID-19 diagnosis solely based on text descriptions of acute changes in chemosensation, i.e., smell, taste and chemesthesis, caused by the disease. The dataset of more than 1500 subjects was obtained from survey responses early in the COVID-19 pandemic, in Spring 2020.
Results: When predicting COVID-19 diagnosis, our NLP model performs comparably (AUC ROC ~ 0.65) to models based on self-reported changes in function collected via quantitative rating scales. Further, our NLP model could attribute importance of words when performing the prediction; sentiment and descriptive words such as "smell", "taste", "sense", had strong contributions to the predictions. In addition, adjectives describing specific tastes or smells such as "salty", "sweet", "spicy", and "sour" also contributed considerably to predictions.
Conclusions: Our results show that the description of perceptual symptoms caused by a viral infection can be used to fine-tune an LLM model to correctly predict and interpret the diagnostic status of a subject. In the future, similar models may have utility for patient verbatims from online health portals or electronic health records.
Plain language summary
Early in the COVID-19 pandemic, people who were infected with SARS-CoV-2 reported changes in smell and taste. To better study these symptoms of SARS-CoV-2 infections and potentially use them to identify infected patients, a survey was undertaken in various countries asking people about their COVID-19 symptoms. One part of the questionnaire asked people to describe the changes in smell and taste they were experiencing. We developed a computational program that could use these responses to correctly distinguish people that had tested positive for SARS-CoV-2 infection from people without SARS-CoV-2 infection. This approach could allow rapid identification of people infected with SARS-CoV-2 from descriptions of their sensory symptoms and be adapted to identify people infected with other viruses in the future.
© 2023. The Author(s).
Conflict of interest statement
R.G. is an advisor for Climax Foods, Equity Compensation (RG); J.E.H. has consulted for for-profit food/consumer product corporations in the last 3 years on projects wholly unrelated to this study; also, he is Director of the Sensory Evaluation Center at Penn State, which routinely conducts product tests for industrial clients to facilitate experiential learning for students. P.M. is advisor of O.W. All other authors have no competing interests to declare.
Figures



References
LinkOut - more resources
Full Text Sources
Miscellaneous
