

Distributional regression modeling via generalized additive models for location, scale, and shape: An overview through a data set from learning analytics
- PMID: 37502671
- PMCID: PMC10369920
- DOI: 10.1002/widm.1479
Distributional regression modeling via generalized additive models for location, scale, and shape: An overview through a data set from learning analytics
Abstract
The advent of technological developments is allowing to gather large amounts of data in several research fields. Learning analytics (LA)/educational data mining has access to big observational unstructured data captured from educational settings and relies mostly on unsupervised machine learning (ML) algorithms to make sense of such type of data. Generalized additive models for location, scale, and shape (GAMLSS) are a supervised statistical learning framework that allows modeling all the parameters of the distribution of the response variable with respect to the explanatory variables. This article overviews the power and flexibility of GAMLSS in relation to some ML techniques. Also, GAMLSS' capability to be tailored toward causality via causal regularization is briefly commented. This overview is illustrated via a data set from the field of LA. This article is categorized under:Application Areas > Education and LearningAlgorithmic Development > StatisticsTechnologies > Machine Learning.
Keywords: causal regularization; causality; educational data mining; generalized additive models for location, scale, and shape; learning analytics; machine learning; statistical learning; statistical modeling; supervised learning.
© 2022 The Authors. WIREs Data Mining and Knowledge Discovery published by Wiley Periodicals LLC.
Conflict of interest statement
The authors have declared no conflicts of interest for this article.
Figures

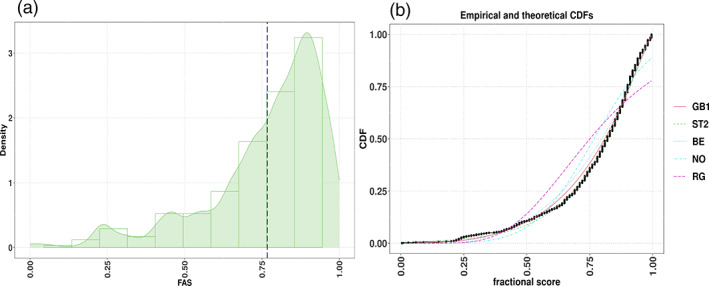




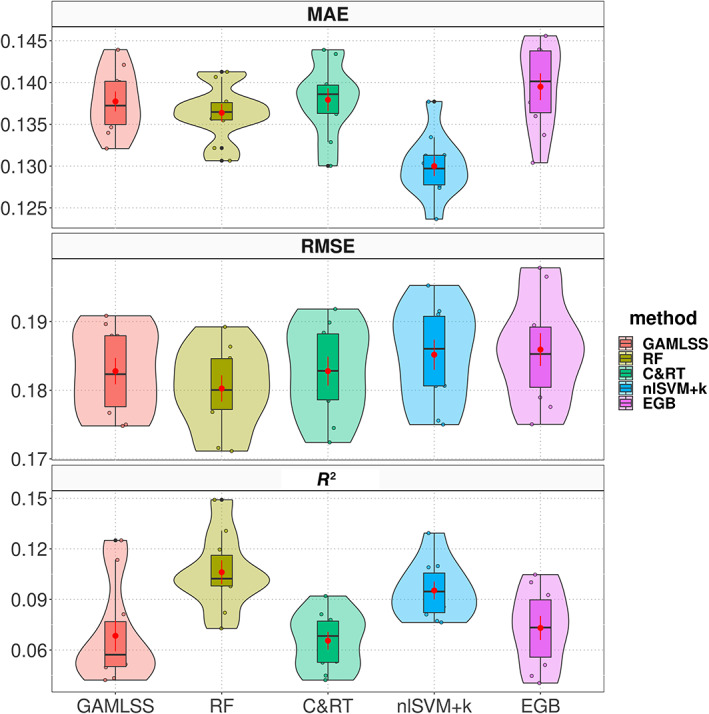
References
-
- Akaike, H. (1974). A new look at the statistical model identification. IEEE Transactions on Automatic Control, 19(6), 716–723.
-
- Akantziliotou, K. , Rigby, R. , & Stasinopoulos, D. (2002). The R implementation of generalized additive models for location, scale and shape. In Statistical modelling in society: Proceedings of the 17th International Workshop on statistical modelling, Statistical Modelling Society, Chania, Crete, July 8‐12, 2002 (pp. 75–83).
-
- Alshabandar, R. , Hussain, A. , Keight, R. , Laws, A. , & Baker, T. (2018). The application of Gaussian mixture models for the identification of at‐risk learners in massive open online courses. In IEEE congress on evolutionary computation. IEEE Publishing. http://researchonline.ljmu.ac.uk/id/eprint/8486/
-
- Angelov, P. P. , Soares, E. A. , Jiang, R. , Arnold, N. I. , & Atkinson, P. M. (2021). Explainable artificial intelligence: An analytical review. WIREs Data Mining and Knowledge Discovery, 11(5), e1424. 10.1002/widm.1424 - DOI
Publication types
LinkOut - more resources
Full Text Sources