

This is a preprint.
High throughput PRIME editing screens identify functional DNA variants in the human genome
- PMID: 37502948
- PMCID: PMC10370011
- DOI: 10.1101/2023.07.12.548736
High throughput PRIME editing screens identify functional DNA variants in the human genome
Update in
-
High-throughput PRIME-editing screens identify functional DNA variants in the human genome.Mol Cell. 2023 Dec 21;83(24):4633-4645.e9. doi: 10.1016/j.molcel.2023.11.021. Mol Cell. 2023. PMID: 38134886 Free PMC article.
Abstract
Despite tremendous progress in detecting DNA variants associated with human disease, interpreting their functional impact in a high-throughput and base-pair resolution manner remains challenging. Here, we develop a novel pooled prime editing screen method, PRIME, which can be applied to characterize thousands of coding and non-coding variants in a single experiment with high reproducibility. To showcase its applications, we first identified essential nucleotides for a 716 bp MYC enhancer via PRIME-mediated saturation mutagenesis. Next, we applied PRIME to functionally characterize 1,304 non-coding variants associated with breast cancer and 3,699 variants from ClinVar. We discovered that 103 non-coding variants and 156 variants of uncertain significance are functional via affecting cell fitness. Collectively, we demonstrate PRIME capable of characterizing genetic variants at base-pair resolution and scale, advancing accurate genome annotation for disease risk prediction, diagnosis, and therapeutic target identification.
Conflict of interest statement
Competing interests statement X.R., H.Y., and Y.S. have filed a patent application related to pooled prime editing screens. Code availability statement A copy of the custom code used for data analysis and figure generation in this study is available upon request.
Figures
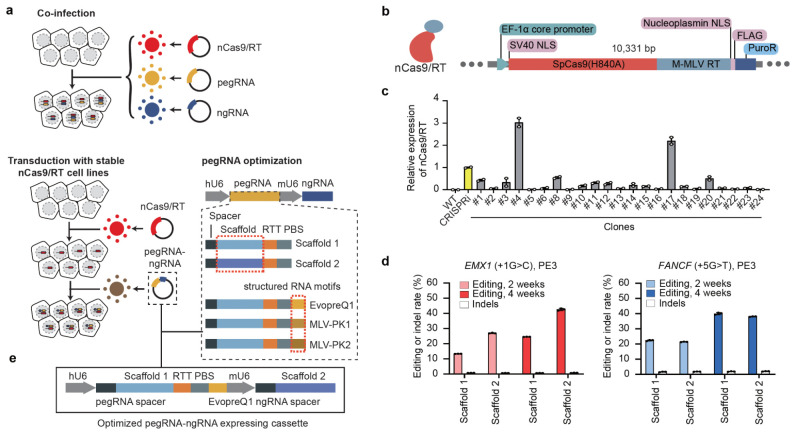
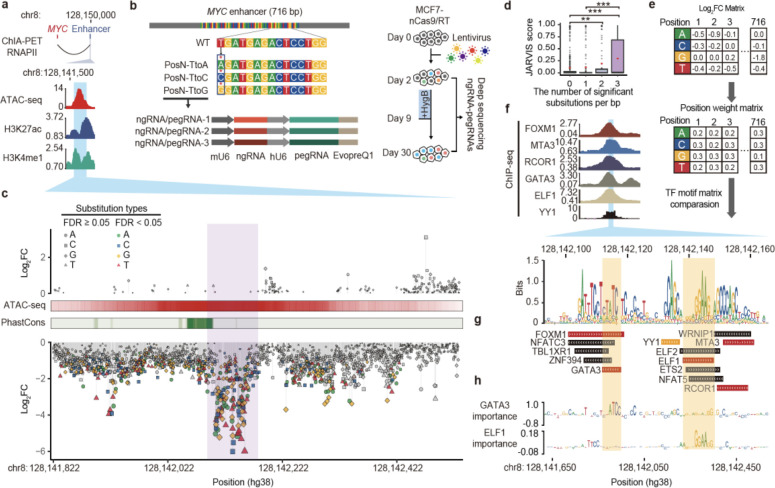
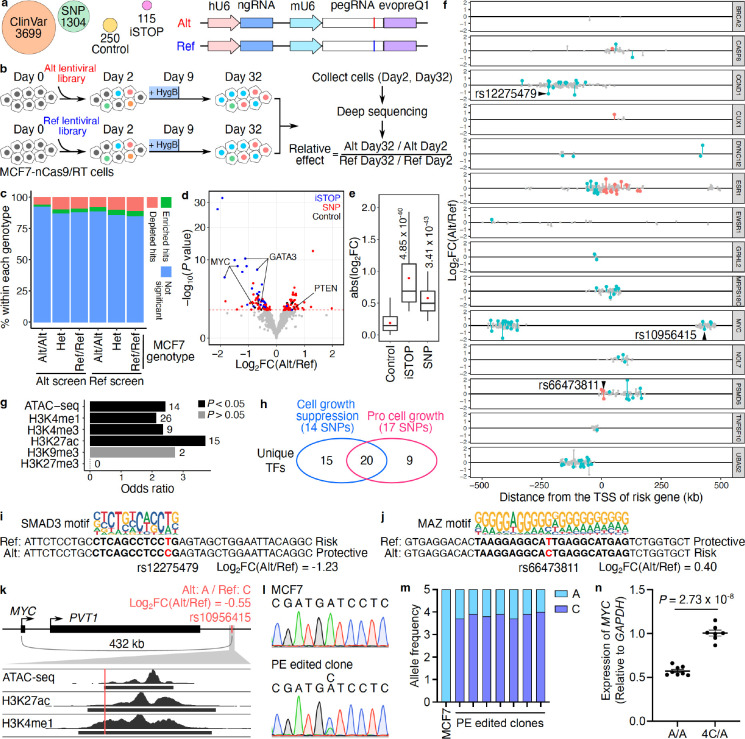
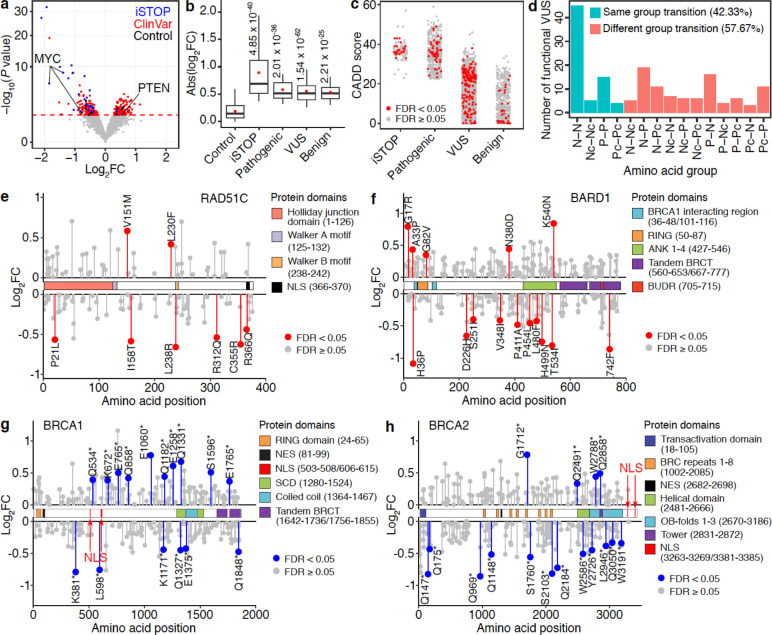
References
-
- Anzalone A.V., Koblan L.W. & Liu D.R. Genome editing with CRISPR-Cas nucleases, base editors, transposases and prime editors. Nat Biotechnol 38, 824–844 (2020). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources