

This is a preprint.
Evaluating Capabilities of Large Language Models: Performance of GPT4 on Surgical Knowledge Assessments
- PMID: 37502981
- PMCID: PMC10371188
- DOI: 10.1101/2023.07.16.23292743
Evaluating Capabilities of Large Language Models: Performance of GPT4 on Surgical Knowledge Assessments
Update in
-
Evaluating capabilities of large language models: Performance of GPT-4 on surgical knowledge assessments.Surgery. 2024 Apr;175(4):936-942. doi: 10.1016/j.surg.2023.12.014. Epub 2024 Jan 20. Surgery. 2024. PMID: 38246839 Free PMC article.
Abstract
Background: Artificial intelligence (AI) has the potential to dramatically alter healthcare by enhancing how we diagnosis and treat disease. One promising AI model is ChatGPT, a large general-purpose language model trained by OpenAI. The chat interface has shown robust, human-level performance on several professional and academic benchmarks. We sought to probe its performance and stability over time on surgical case questions.
Methods: We evaluated the performance of ChatGPT-4 on two surgical knowledge assessments: the Surgical Council on Resident Education (SCORE) and a second commonly used knowledge assessment, referred to as Data-B. Questions were entered in two formats: open-ended and multiple choice. ChatGPT output were assessed for accuracy and insights by surgeon evaluators. We categorized reasons for model errors and the stability of performance on repeat encounters.
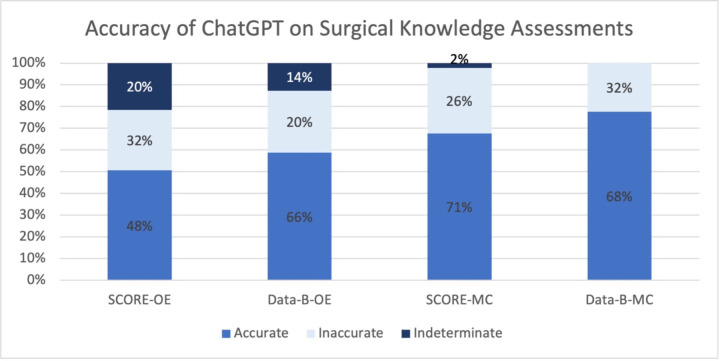
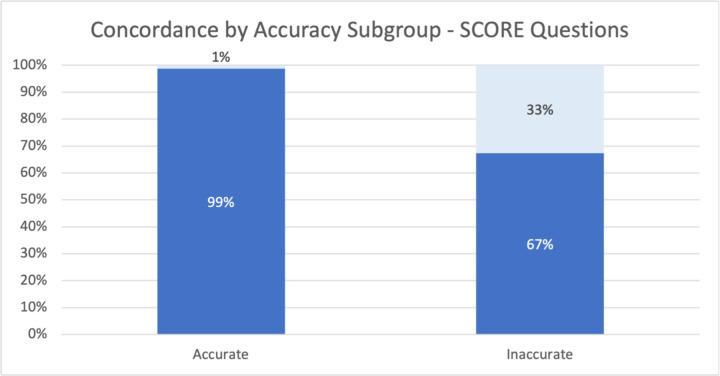
Results: A total of 167 SCORE and 112 Data-B questions were presented to the ChatGPT interface. ChatGPT correctly answered 71% and 68% of multiple-choice SCORE and Data-B questions, respectively. For both open-ended and multiple-choice questions, approximately two-thirds of ChatGPT responses contained non-obvious insights. Common reasons for inaccurate responses included: inaccurate information in a complex question (n=16, 36.4%); inaccurate information in fact-based question (n=11, 25.0%); and accurate information with circumstantial discrepancy (n=6, 13.6%). Upon repeat query, the answer selected by ChatGPT varied for 36.4% of inaccurate questions; the response accuracy changed for 6/16 questions.
Conclusion: Consistent with prior findings, we demonstrate robust near or above human-level performance of ChatGPT within the surgical domain. Unique to this study, we demonstrate a substantial inconsistency in ChatGPT responses with repeat query. This finding warrants future consideration and presents an opportunity to further train these models to provide safe and consistent responses. Without mental and/or conceptual models, it is unclear whether language models such as ChatGPT would be able to safely assist clinicians in providing care.
Keywords: ChatGPT; artificial intelligence; language models; surgery; surgical education.
Figures
References
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources