

Modality-Specific Perceptual Learning of Vocoded Auditory versus Lipread Speech: Different Effects of Prior Information
- PMID: 37508940
- PMCID: PMC10377548
- DOI: 10.3390/brainsci13071008
Modality-Specific Perceptual Learning of Vocoded Auditory versus Lipread Speech: Different Effects of Prior Information
Abstract
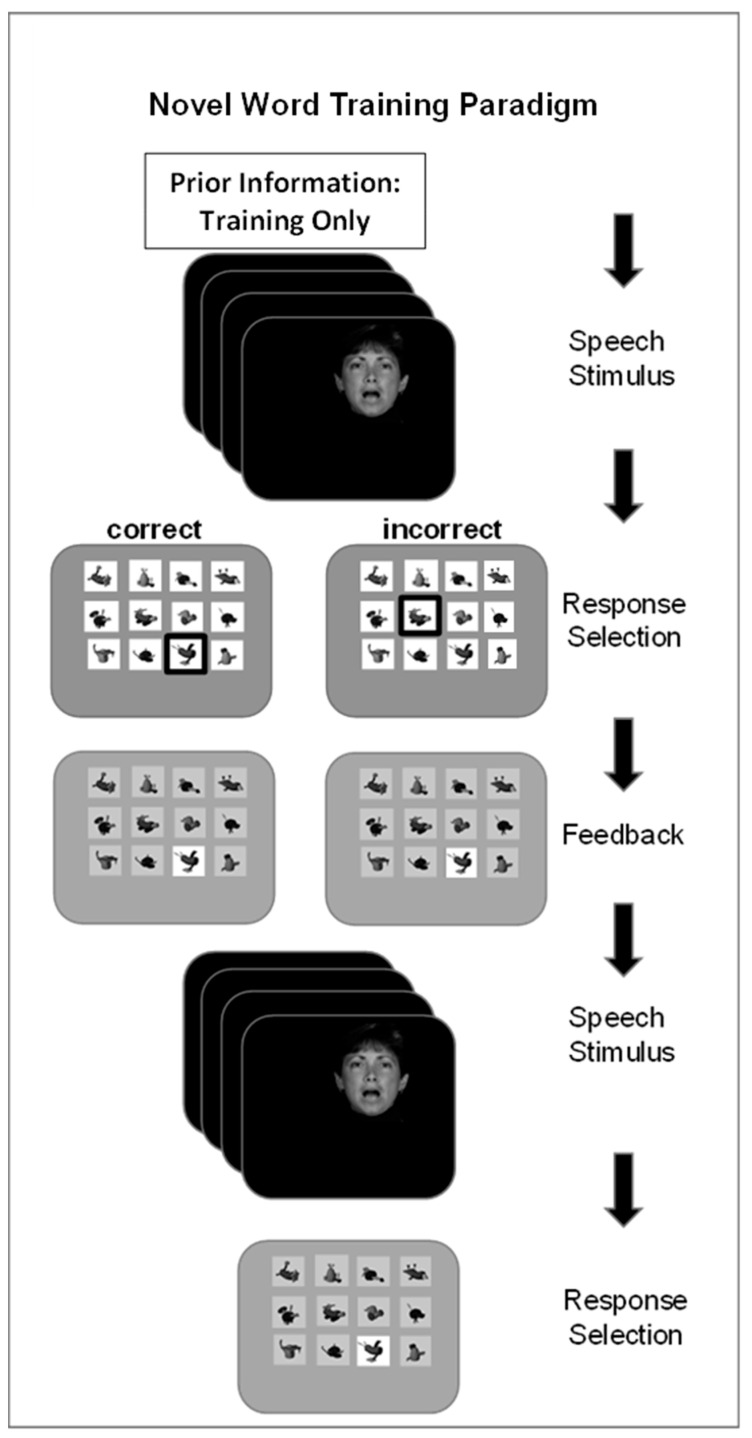
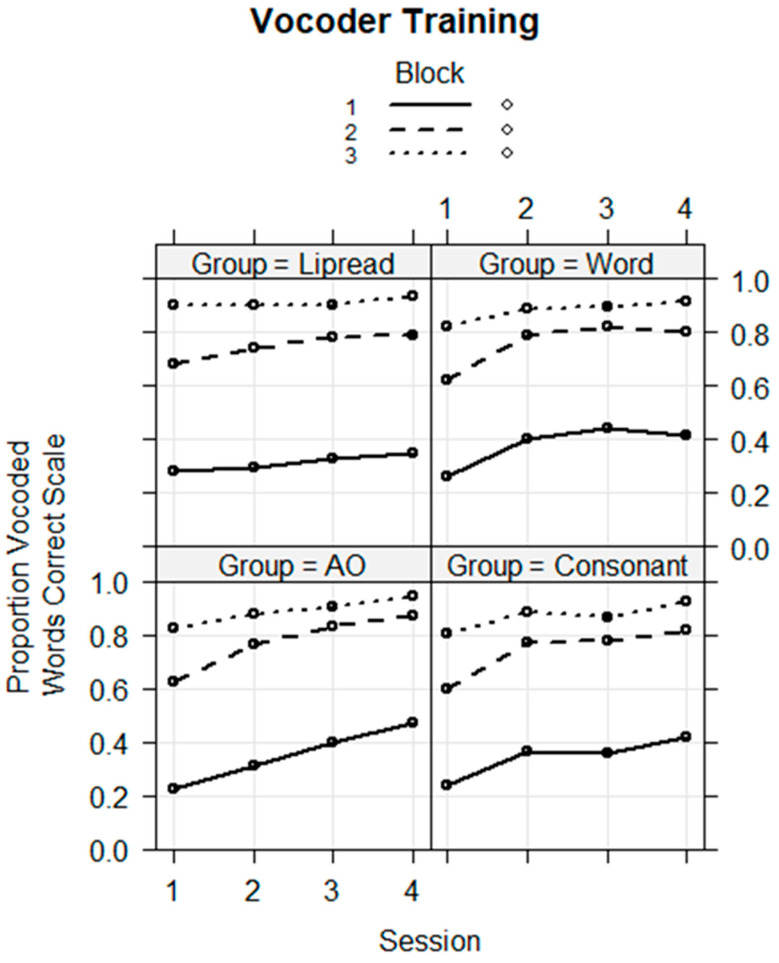
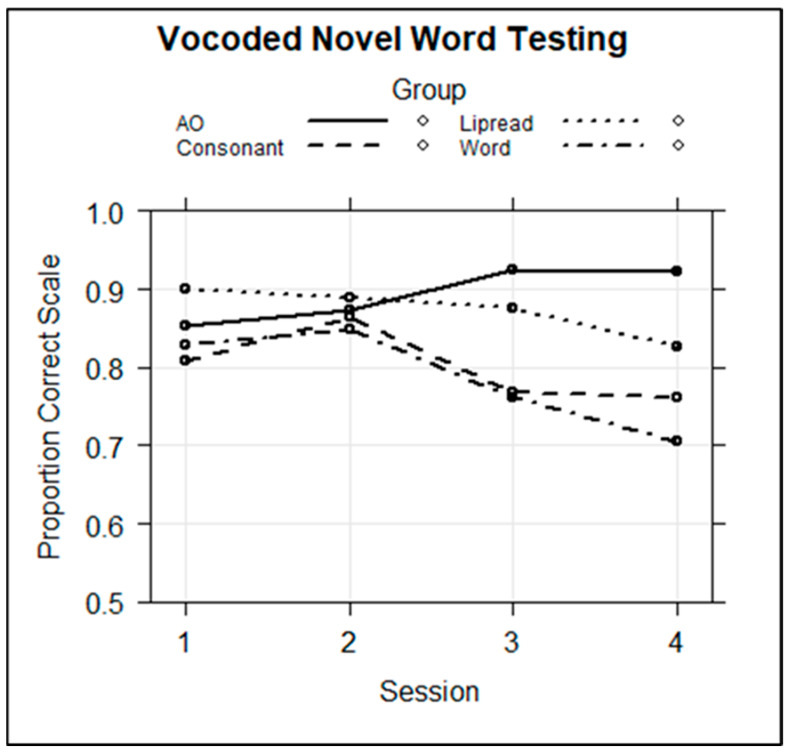
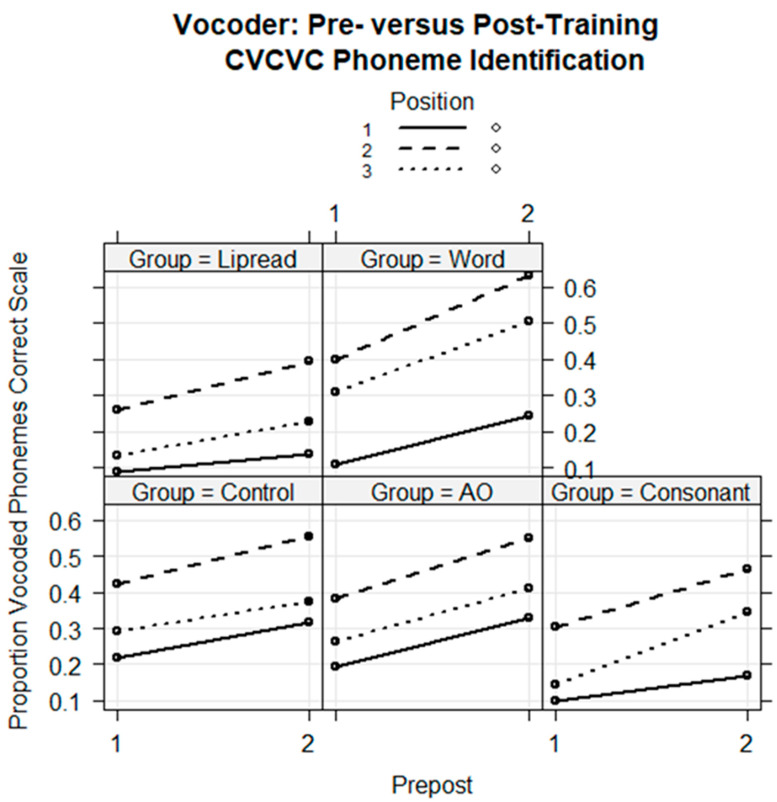
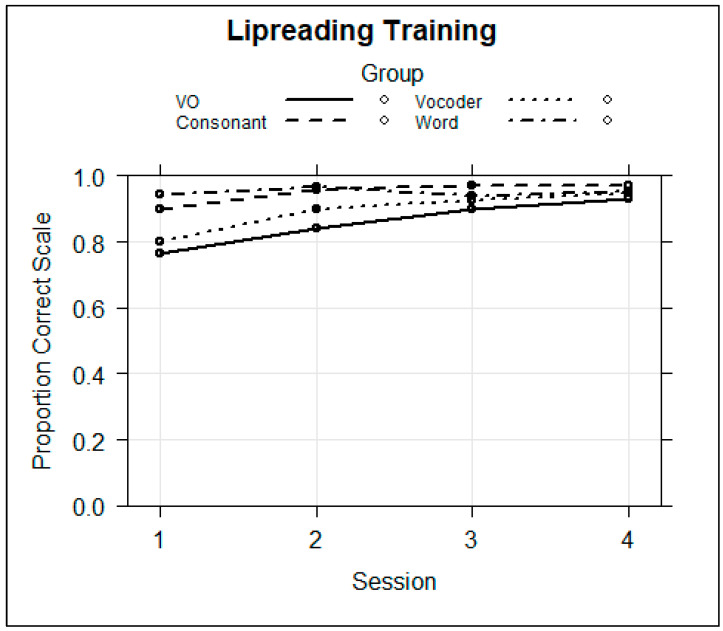
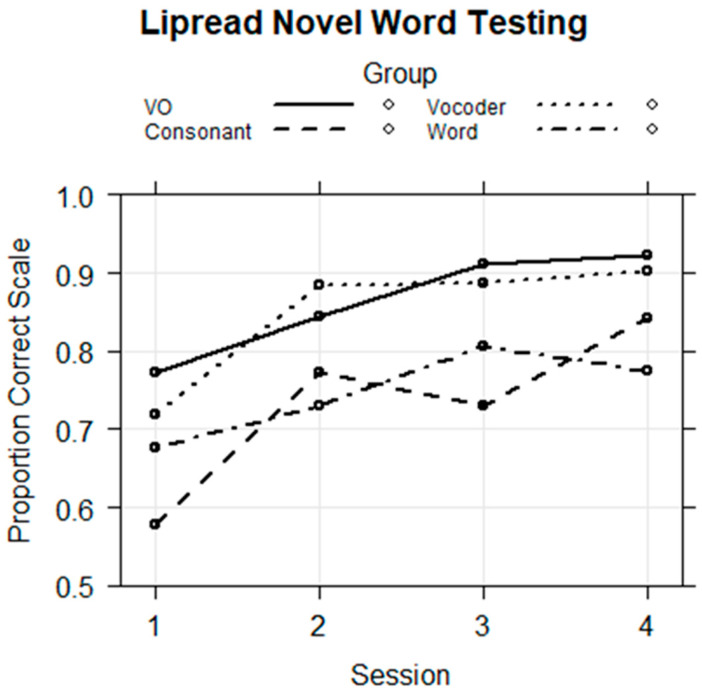
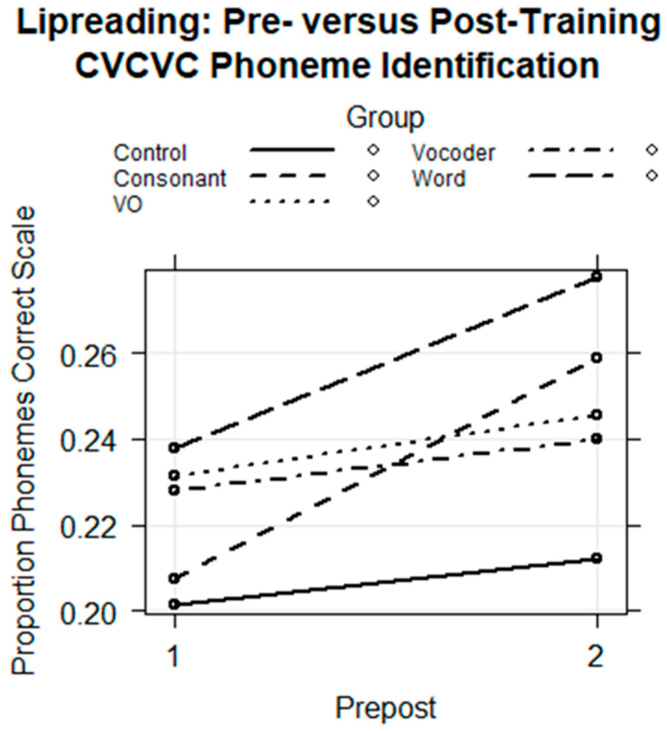
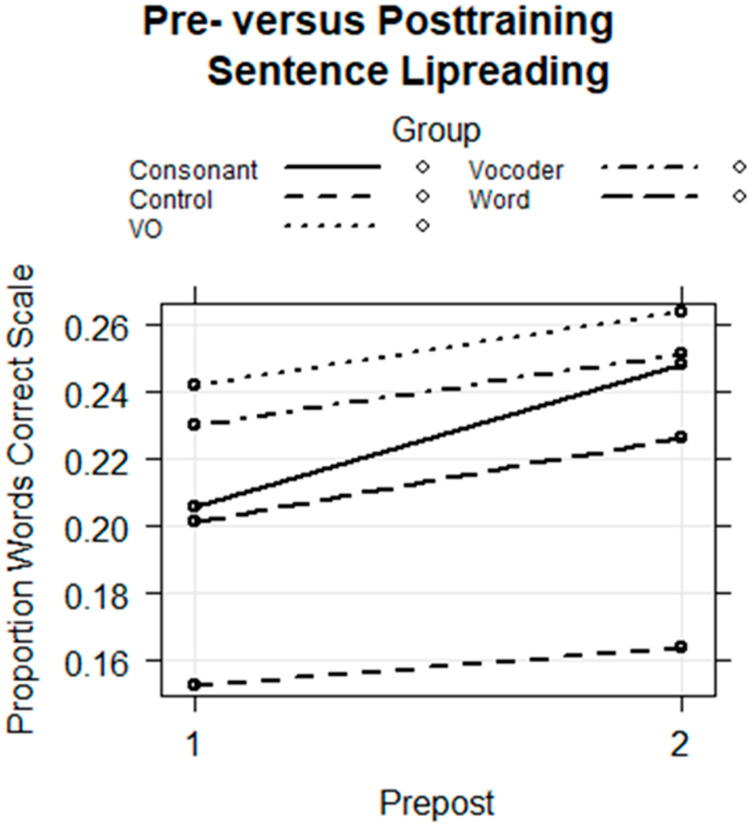
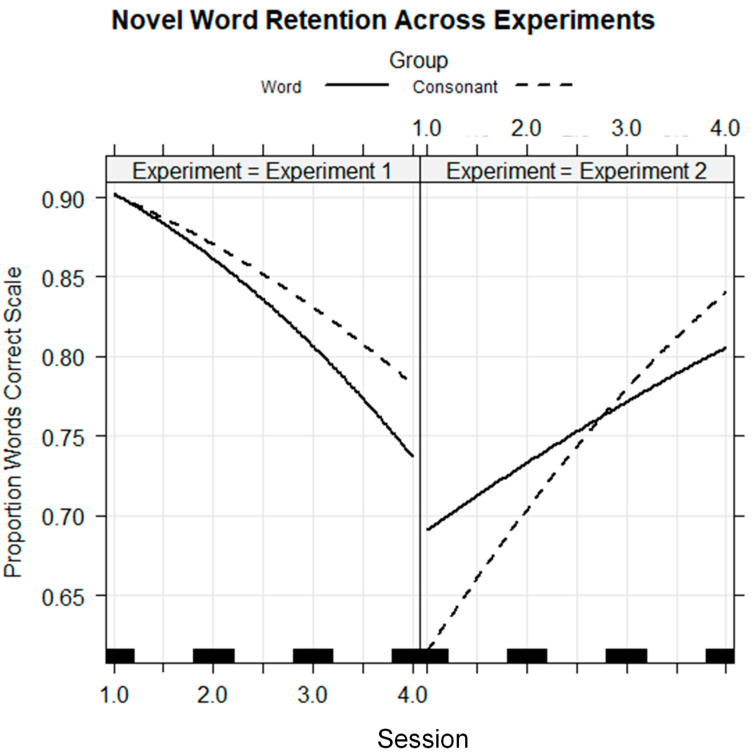
Traditionally, speech perception training paradigms have not adequately taken into account the possibility that there may be modality-specific requirements for perceptual learning with auditory-only (AO) versus visual-only (VO) speech stimuli. The study reported here investigated the hypothesis that there are modality-specific differences in how prior information is used by normal-hearing participants during vocoded versus VO speech training. Two different experiments, one with vocoded AO speech (Experiment 1) and one with VO, lipread, speech (Experiment 2), investigated the effects of giving different types of prior information to trainees on each trial during training. The training was for four ~20 min sessions, during which participants learned to label novel visual images using novel spoken words. Participants were assigned to different types of prior information during training: Word Group trainees saw a printed version of each training word (e.g., "tethon"), and Consonant Group trainees saw only its consonants (e.g., "t_th_n"). Additional groups received no prior information (i.e., Experiment 1, AO Group; Experiment 2, VO Group) or a spoken version of the stimulus in a different modality from the training stimuli (Experiment 1, Lipread Group; Experiment 2, Vocoder Group). That is, in each experiment, there was a group that received prior information in the modality of the training stimuli from the other experiment. In both experiments, the Word Groups had difficulty retaining the novel words they attempted to learn during training. However, when the training stimuli were vocoded, the Word Group improved their phoneme identification. When the training stimuli were visual speech, the Consonant Group improved their phoneme identification and their open-set sentence lipreading. The results are considered in light of theoretical accounts of perceptual learning in relationship to perceptual modality.
Keywords: lipreading; multisensory; perceptual learning; speech perception; speech perception training; spoken language processing; vocoded speech; word learning.
Conflict of interest statement
The authors have a conflict of interest. They are principals of SeeHear LLC. SeeHear LLC is a company formed to research and develop speech perception training. The study reported here made no use of SeeHear resources or intellectual property. The US NIH had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Figures


References
-
- Jeffers J., Barley M. In: Speechreading (Lipreading) Charles C., editor. Thomas; Springfield, IL, USA: 1971. p. 392.
-
- Gault R.H. On the effect of simultaneous tactual-visual stimulation in relation to the interpretation of speech. J. Abnorm. Soc. Psychol. 1930;24:498–517. doi: 10.1037/h0072775. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
