

SCFusion: Infrared and Visible Fusion Based on Salient Compensation
- PMID: 37509931
- PMCID: PMC10378341
- DOI: 10.3390/e25070985
SCFusion: Infrared and Visible Fusion Based on Salient Compensation
Abstract
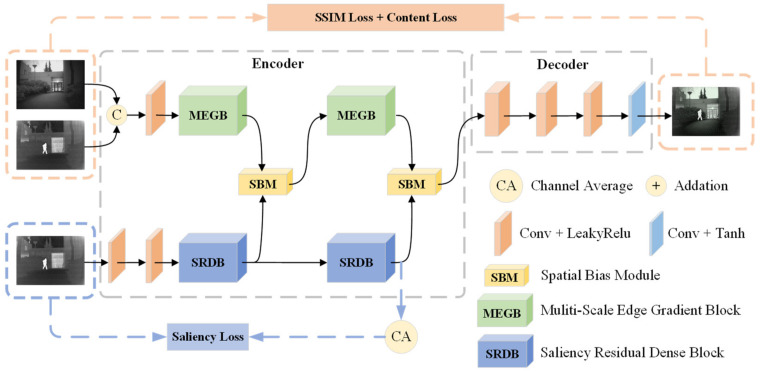
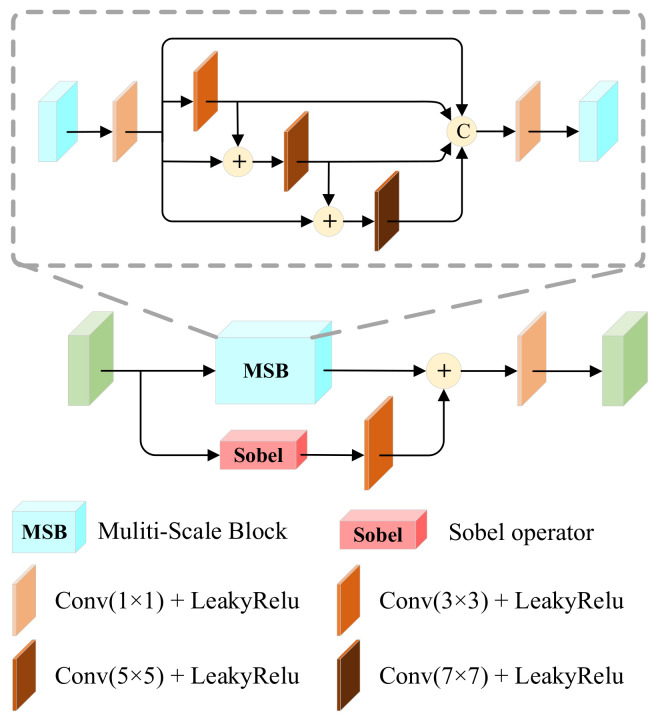
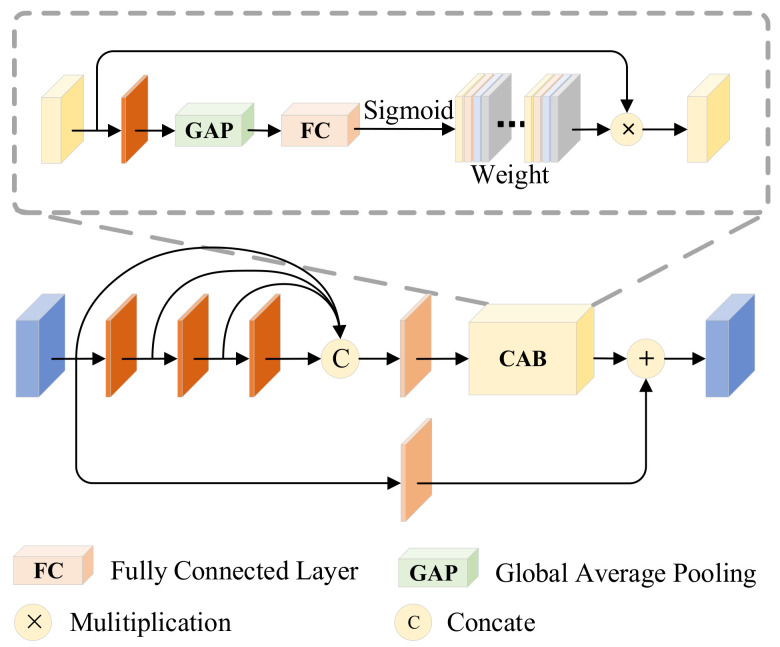
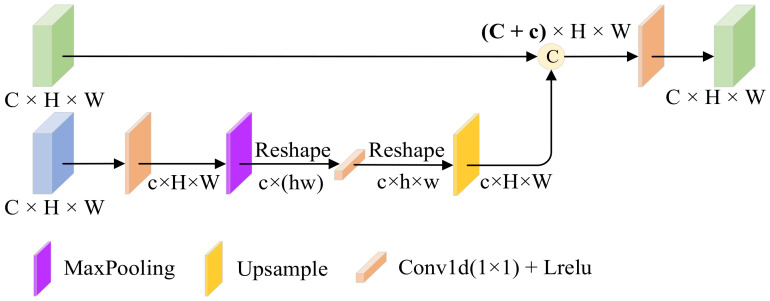
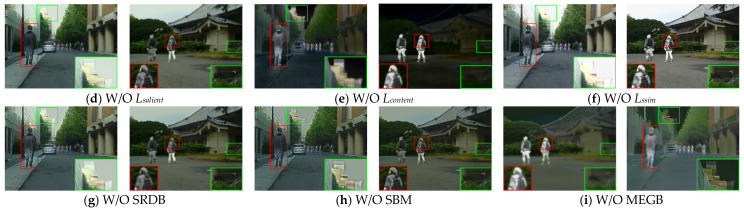
The aim of infrared and visible image fusion is to integrate the complementary information of the two modalities for high-quality fused images. However, many deep learning fusion algorithms have not considered the characteristics of infrared images in low-light scenes, leading to the problems of weak texture details, low contrast of infrared targets and poor visual perception in the existing methods. Therefore, in this paper, we propose a salient compensation-based fusion method that makes sufficient use of the characteristics of infrared and visible images to generate high-quality fused images under low-light conditions. First, we design a multi-scale edge gradient module (MEGB) in the texture mainstream to adequately extract the texture information of the dual input of infrared and visible images; on the other hand, the salient tributary is pre-trained by salient loss to obtain the saliency map based on the salient dense residual module (SRDB) to extract salient features, which is supplemented in the process of overall network training. We propose the spatial bias module (SBM) to fuse global information with local information. Finally, extensive comparison experiments with existing methods show that our method has significant advantages in describing target features and global scenes, the effectiveness of the proposed module is demonstrated by ablation experiments. In addition, we also verify the facilitation of this paper's method for high-level vision on a semantic segmentation task.
Keywords: deep learning; image fusion; infrared and visible images; salient compensation.
Conflict of interest statement
The authors declare no conflict of interest.
Figures





Similar articles
-
Infrared and Visible Image Fusion Based on Visual Saliency Map and Image Contrast Enhancement.Sensors (Basel). 2022 Aug 25;22(17):6390. doi: 10.3390/s22176390. Sensors (Basel). 2022. PMID: 36080849 Free PMC article.
-
Semantic-Aware Fusion Network Based on Super-Resolution.Sensors (Basel). 2024 Jun 5;24(11):3665. doi: 10.3390/s24113665. Sensors (Basel). 2024. PMID: 38894455 Free PMC article.
-
Infrared-Visible Image Fusion Based on Semantic Guidance and Visual Perception.Entropy (Basel). 2022 Sep 21;24(10):1327. doi: 10.3390/e24101327. Entropy (Basel). 2022. PMID: 37420348 Free PMC article.
-
Infrared and Visible Image Fusion Technology and Application: A Review.Sensors (Basel). 2023 Jan 4;23(2):599. doi: 10.3390/s23020599. Sensors (Basel). 2023. PMID: 36679396 Free PMC article. Review.
-
Saliency-CCE: Exploiting colour contextual extractor and saliency-based biomedical image segmentation.Comput Biol Med. 2023 Mar;154:106551. doi: 10.1016/j.compbiomed.2023.106551. Epub 2023 Jan 20. Comput Biol Med. 2023. PMID: 36716685 Review.
Cited by
-
SIFusion: Lightweight infrared and visible image fusion based on semantic injection.PLoS One. 2024 Nov 6;19(11):e0307236. doi: 10.1371/journal.pone.0307236. eCollection 2024. PLoS One. 2024. PMID: 39504316 Free PMC article.
-
SharDif: Sharing and Differential Learning for Image Fusion.Entropy (Basel). 2024 Jan 9;26(1):57. doi: 10.3390/e26010057. Entropy (Basel). 2024. PMID: 38248182 Free PMC article.
-
Lightweight Cross-Modal Information Mutual Reinforcement Network for RGB-T Salient Object Detection.Entropy (Basel). 2024 Jan 31;26(2):130. doi: 10.3390/e26020130. Entropy (Basel). 2024. PMID: 38392385 Free PMC article.
-
SDAM: A dual attention mechanism for high-quality fusion of infrared and visible images.PLoS One. 2024 Sep 24;19(9):e0308885. doi: 10.1371/journal.pone.0308885. eCollection 2024. PLoS One. 2024. PMID: 39316595 Free PMC article.
References
-
- Zhang H., Xu H., Tian X., Jiang J., Ma J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion. 2021;76:323–336. doi: 10.1016/j.inffus.2021.06.008. - DOI
-
- Chen J., Li X., Luo L., Ma J. Multi-focus image fusion based on multi-scale gradients and image matting. IEEE Trans. Multimed. 2021;24:655–667. doi: 10.1109/TMM.2021.3057493. - DOI
-
- Parihar A.S., Singh K., Rohilla H., Asnani G. Fusion-based simultaneous estimation of reflectance and illumination for low-light image enhancement. IET Image Process. 2021;15:1410–1423. doi: 10.1049/ipr2.12114. - DOI
-
- Shi Z., Guo B., Zhao M., Zhang C. Nighttime low illumination image enhancement with single image using bright/dark channel prior. EURASIP J. Image Video Process. 2018;2018:13. doi: 10.1186/s13640-018-0251-4. - DOI
-
- Zhang X. Benchmarking and comparing multi-exposure image fusion algorithms. Inf. Fusion. 2021;74:111–131. doi: 10.1016/j.inffus.2021.02.005. - DOI
Grants and funding
LinkOut - more resources
Full Text Sources
