

A Preprocessing Manifold Learning Strategy Based on t-Distributed Stochastic Neighbor Embedding
- PMID: 37510011
- PMCID: PMC10378244
- DOI: 10.3390/e25071065
A Preprocessing Manifold Learning Strategy Based on t-Distributed Stochastic Neighbor Embedding
Abstract
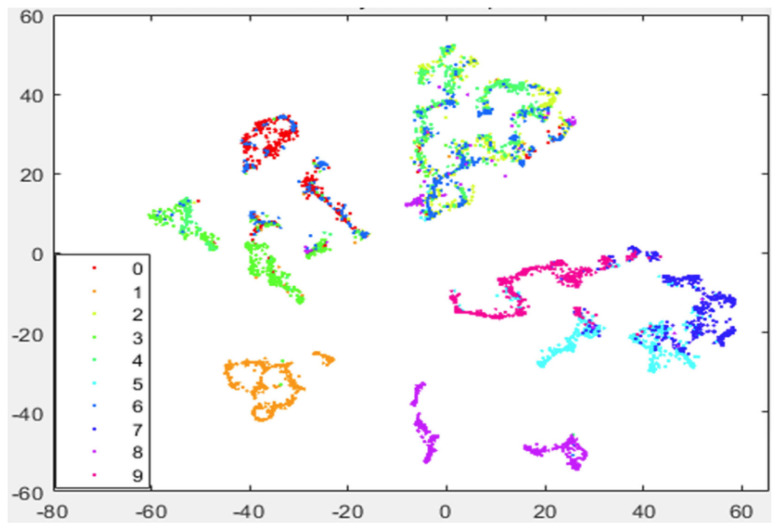
In machine learning and data analysis, dimensionality reduction and high-dimensional data visualization can be accomplished by manifold learning using a t-Distributed Stochastic Neighbor Embedding (t-SNE) algorithm. We significantly improve this manifold learning scheme by introducing a preprocessing strategy for the t-SNE algorithm. In our preprocessing, we exploit Laplacian eigenmaps to reduce the high-dimensional data first, which can aggregate each data cluster and reduce the Kullback-Leibler divergence (KLD) remarkably. Moreover, the k-nearest-neighbor (KNN) algorithm is also involved in our preprocessing to enhance the visualization performance and reduce the computation and space complexity. We compare the performance of our strategy with that of the standard t-SNE on the MNIST dataset. The experiment results show that our strategy exhibits a stronger ability to separate different clusters as well as keep data of the same kind much closer to each other. Moreover, the KLD can be reduced by about 30% at the cost of increasing the complexity in terms of runtime by only 1-2%.
Keywords: dimensionality reducing; k-nearest neighbor; manifold learning; t-SNE.
Conflict of interest statement
The authors declare no conflicts of interest.
Figures









Similar articles
-
Nonlinear Feature Extraction Through Manifold Learning in an Electronic Tongue Classification Task.Sensors (Basel). 2020 Aug 27;20(17):4834. doi: 10.3390/s20174834. Sensors (Basel). 2020. PMID: 32867066 Free PMC article.
-
Shape-aware stochastic neighbor embedding for robust data visualisations.BMC Bioinformatics. 2022 Nov 14;23(1):477. doi: 10.1186/s12859-022-05028-8. BMC Bioinformatics. 2022. PMID: 36376789 Free PMC article.
-
Supervised t-distributed stochastic neighbor embedding for data visualization and classification.INFORMS J Comput. 2021 Spring;33(2):419-835. doi: 10.1287/ijoc.2020.0961. Epub 2020 Sep 10. INFORMS J Comput. 2021. PMID: 34354339 Free PMC article.
-
A Study on Dimensionality Reduction and Parameters for Hyperspectral Imagery Based on Manifold Learning.Sensors (Basel). 2024 Mar 25;24(7):2089. doi: 10.3390/s24072089. Sensors (Basel). 2024. PMID: 38610302 Free PMC article.
-
Neural manifold analysis of brain circuit dynamics in health and disease.J Comput Neurosci. 2023 Feb;51(1):1-21. doi: 10.1007/s10827-022-00839-3. Epub 2022 Dec 16. J Comput Neurosci. 2023. PMID: 36522604 Free PMC article. Review.
Cited by
-
Analysis of dermoscopy images of multi-class for early detection of skin lesions by hybrid systems based on integrating features of CNN models.PLoS One. 2024 Mar 21;19(3):e0298305. doi: 10.1371/journal.pone.0298305. eCollection 2024. PLoS One. 2024. PMID: 38512890 Free PMC article.
References
-
- Keogh E., Mueen A. Encyclopedia of Machine Learning. Springer; Boston, MA, USA: 2011. Curse of dimensionality; pp. 257–258.
-
- Anowar F., Sadaoui S., Selim B. Conceptual and empirical comparison of dimensionality reduction algorithms (PCA, KPCA, LDA, MDS, SVD, LLE, ISOMAP, LE, ICA, t-SNE) Comput. Sci. Rev. 2021;40:100378. doi: 10.1016/j.cosrev.2021.100378. - DOI
-
- An P., Wang Z., Zhang C. Ensemble unsupervised autoencoders and Gaussian mixture model for cyberattack detection. Inf. Process. Manag. 2022;59:102844. doi: 10.1016/j.ipm.2021.102844. - DOI
-
- Gorban A.N., Kégl B., Wunsch D.C., Zinovyev A.Y., editors. Principal Manifolds for Data Visualization and Dimension Reduction. Springer; Boston, MA, USA: 2008.
Grants and funding
LinkOut - more resources
Full Text Sources
