

MInet: A Novel Network Model for Point Cloud Processing by Integrating Multi-Modal Information
- PMID: 37514622
- PMCID: PMC10386742
- DOI: 10.3390/s23146327
MInet: A Novel Network Model for Point Cloud Processing by Integrating Multi-Modal Information
Abstract
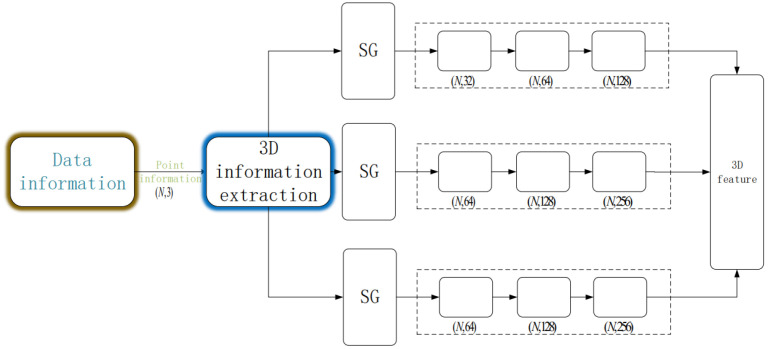
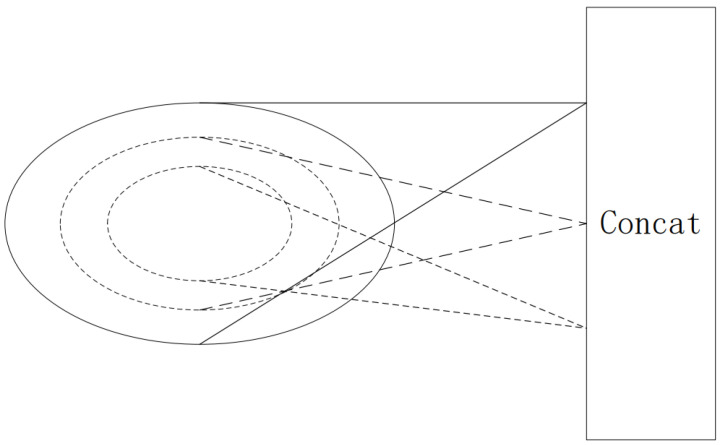
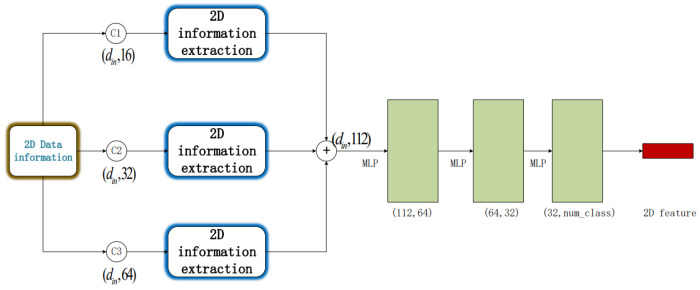
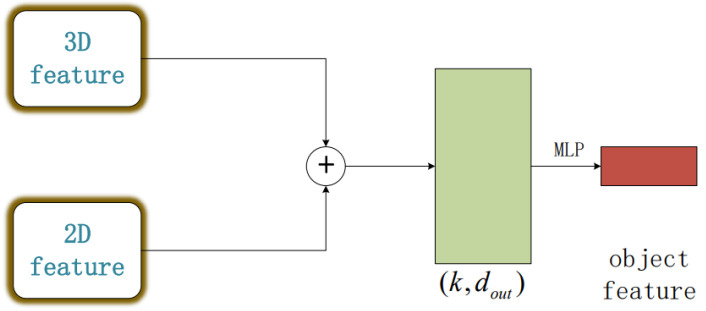
Three-dimensional LiDAR systems that capture point cloud data enable the simultaneous acquisition of spatial geometry and multi-wavelength intensity information, thereby paving the way for three-dimensional point cloud recognition and processing. However, due to the irregular distribution, low resolution of point clouds, and limited spatial recognition accuracy in complex environments, inherent errors occur in classifying and segmenting the acquired target information. Conversely, two-dimensional visible light images provide real-color information, enabling the distinction of object contours and fine details, thus yielding clear, high-resolution images when desired. The integration of two-dimensional information with point clouds offers complementary advantages. In this paper, we present the incorporation of two-dimensional information to form a multi-modal representation. From this, we extract local features to establish three-dimensional geometric relationships and two-dimensional color relationships. We introduce a novel network model, termed MInet (Multi-Information net), which effectively captures features relating to both two-dimensional color and three-dimensional pose information. This enhanced network model improves feature saliency, thereby facilitating superior segmentation and recognition tasks. We evaluate our MInet architecture using the ShapeNet and ThreeDMatch datasets for point cloud segmentation, and the Stanford dataset for object recognition. The robust results, coupled with quantitative and qualitative experiments, demonstrate the superior performance of our proposed method in point cloud segmentation and object recognition tasks.
Keywords: LiDAR; multi-modal information; object recognition; point cloud; segmentation.
Conflict of interest statement
The authors declare no conflict of interest.
Figures



Similar articles
-
3D Point Cloud Recognition Based on a Multi-View Convolutional Neural Network.Sensors (Basel). 2018 Oct 29;18(11):3681. doi: 10.3390/s18113681. Sensors (Basel). 2018. PMID: 30380691 Free PMC article.
-
An Efficient Ensemble Deep Learning Approach for Semantic Point Cloud Segmentation Based on 3D Geometric Features and Range Images.Sensors (Basel). 2022 Aug 18;22(16):6210. doi: 10.3390/s22166210. Sensors (Basel). 2022. PMID: 36015964 Free PMC article.
-
Point Cloud Semantic Segmentation Network Based on Multi-Scale Feature Fusion.Sensors (Basel). 2021 Feb 26;21(5):1625. doi: 10.3390/s21051625. Sensors (Basel). 2021. PMID: 33652553 Free PMC article.
-
Deep Learning on Point Clouds and Its Application: A Survey.Sensors (Basel). 2019 Sep 26;19(19):4188. doi: 10.3390/s19194188. Sensors (Basel). 2019. PMID: 31561639 Free PMC article. Review.
-
Object Recognition, Segmentation, and Classification of Mobile Laser Scanning Point Clouds: A State of the Art Review.Sensors (Basel). 2019 Feb 16;19(4):810. doi: 10.3390/s19040810. Sensors (Basel). 2019. PMID: 30781508 Free PMC article. Review.
Cited by
-
RST: Rough Set Transformer for Point Cloud Learning.Sensors (Basel). 2023 Nov 8;23(22):9042. doi: 10.3390/s23229042. Sensors (Basel). 2023. PMID: 38005431 Free PMC article.
References
-
- Liu Z., Cai Y., Wang H., Chen L., Gao H., Jia Y., Li Y. Robust target recognition and tracking of self-driving cars with radar and camera information fusion under severe weather conditions. IEEE Trans. Intell. Transp. Syst. 2021;23:6640–6653. doi: 10.1109/TITS.2021.3059674. - DOI
-
- Jiang J., Liu D., Gu J., Süsstrunk S. What is the space of spectral sensitivity functions for digital color cameras?; Proceedings of the 2013 IEEE Workshop on Applications of Computer Vision (WACV); Clearwater Beach, FL, USA. 15–17 January 2013; pp. 168–179.
-
- Schumann O., Hahn M., Dickmann J., Wöhler C. Semantic segmentation on radar point clouds; Proceedings of the 2018 21st International Conference on Information Fusion (FUSION); Cambridge, UK. 10–13 July 2018; pp. 2179–2186.
LinkOut - more resources
Full Text Sources
