

The shaky foundations of large language models and foundation models for electronic health records
- PMID: 37516790
- PMCID: PMC10387101
- DOI: 10.1038/s41746-023-00879-8
The shaky foundations of large language models and foundation models for electronic health records
Abstract
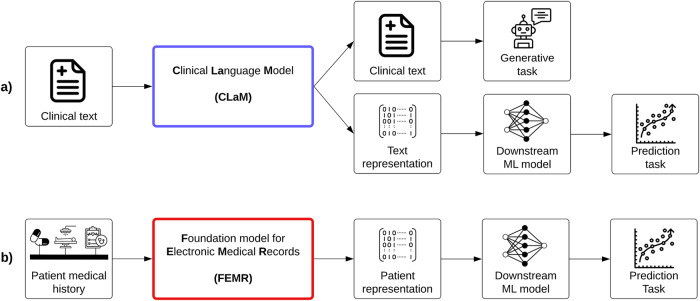
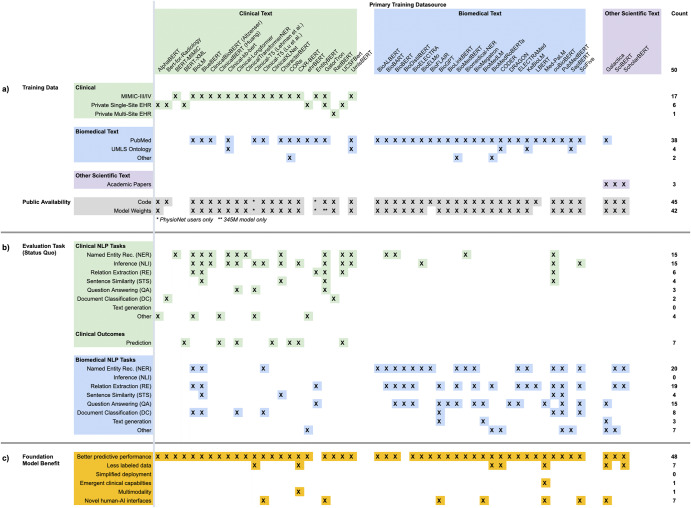
The success of foundation models such as ChatGPT and AlphaFold has spurred significant interest in building similar models for electronic medical records (EMRs) to improve patient care and hospital operations. However, recent hype has obscured critical gaps in our understanding of these models' capabilities. In this narrative review, we examine 84 foundation models trained on non-imaging EMR data (i.e., clinical text and/or structured data) and create a taxonomy delineating their architectures, training data, and potential use cases. We find that most models are trained on small, narrowly-scoped clinical datasets (e.g., MIMIC-III) or broad, public biomedical corpora (e.g., PubMed) and are evaluated on tasks that do not provide meaningful insights on their usefulness to health systems. Considering these findings, we propose an improved evaluation framework for measuring the benefits of clinical foundation models that is more closely grounded to metrics that matter in healthcare.
© 2023. The Author(s).
Conflict of interest statement
B.P. reports stock-based compensation from Google, LLC. Otherwise, the authors declare that there are no competing interests.
Figures


References
-
- Bommasani, R. et al. On the opportunities and risks of foundation models. Preprint at arXiv: 2108.07258 (2021).
-
- Brown, T. B. et al. Language models are few-shot learners. Preprint at arXiv:2005.14165 (2020).
-
- Esser, P., Chiu, J., Atighehchian, P., Granskog, J. & Germanidis, A. Structure and content-guided video synthesis with diffusion models. Preprint at arXiv: 2302.03011 (2023).
-
- Jiang, Y. et al. VIMA: general robot manipulation with multimodal prompts. Preprint at arXiv: 2210.03094 (2022).
Publication types
LinkOut - more resources
Full Text Sources
