

Applications of multi-omics analysis in human diseases
- PMID: 37533767
- PMCID: PMC10390758
- DOI: 10.1002/mco2.315
Applications of multi-omics analysis in human diseases
Abstract
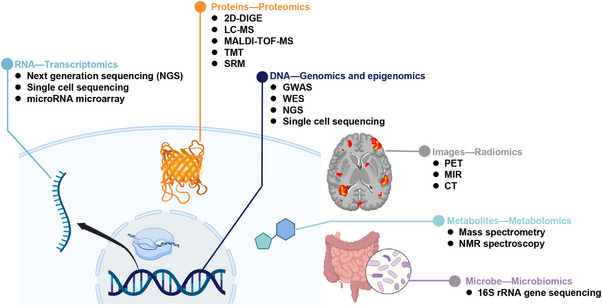
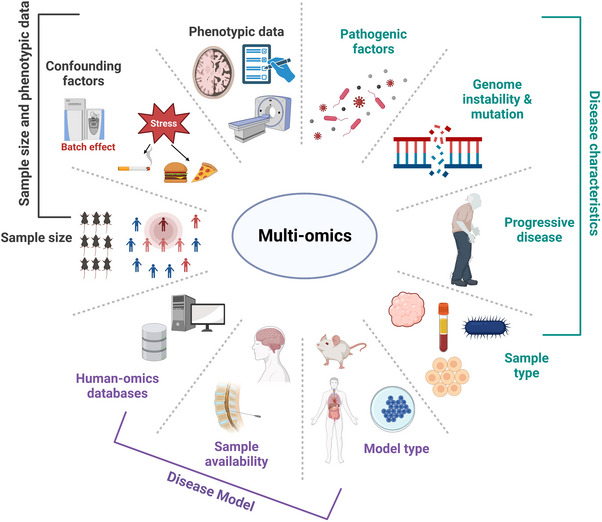
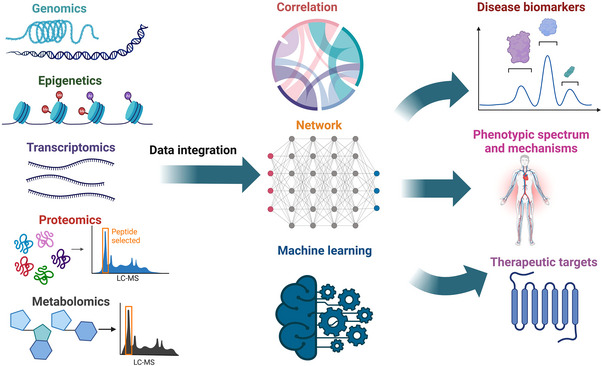
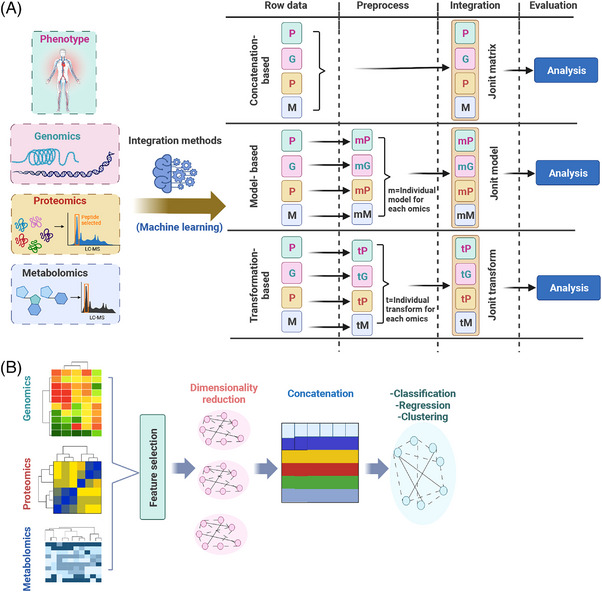
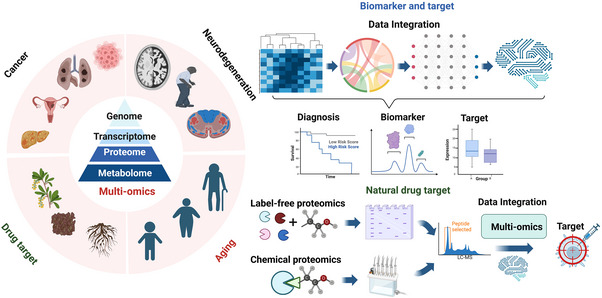
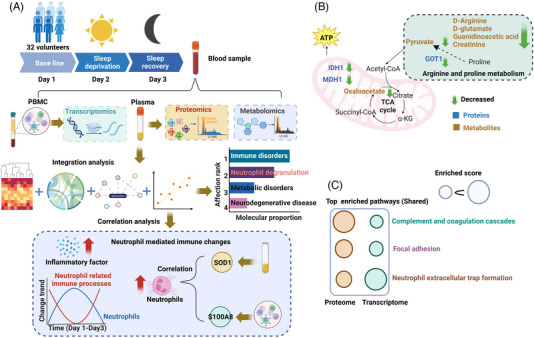
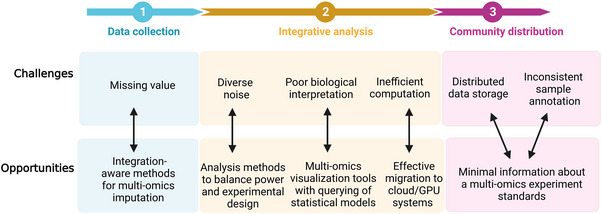
Multi-omics usually refers to the crossover application of multiple high-throughput screening technologies represented by genomics, transcriptomics, single-cell transcriptomics, proteomics and metabolomics, spatial transcriptomics, and so on, which play a great role in promoting the study of human diseases. Most of the current reviews focus on describing the development of multi-omics technologies, data integration, and application to a particular disease; however, few of them provide a comprehensive and systematic introduction of multi-omics. This review outlines the existing technical categories of multi-omics, cautions for experimental design, focuses on the integrated analysis methods of multi-omics, especially the approach of machine learning and deep learning in multi-omics data integration and the corresponding tools, and the application of multi-omics in medical researches (e.g., cancer, neurodegenerative diseases, aging, and drug target discovery) as well as the corresponding open-source analysis tools and databases, and finally, discusses the challenges and future directions of multi-omics integration and application in precision medicine. With the development of high-throughput technologies and data integration algorithms, as important directions of multi-omics for future disease research, single-cell multi-omics and spatial multi-omics also provided a detailed introduction. This review will provide important guidance for researchers, especially who are just entering into multi-omics medical research.
Keywords: biomarker; machine learning and deep learning; multi‐omics; neurodegenerative disease; precision medicine.
© 2023 The Authors. MedComm published by Sichuan International Medical Exchange & Promotion Association (SCIMEA) and John Wiley & Sons Australia, Ltd.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Kreitmaier P, Katsoula G, Zeggini E. Insights from multi‐omics integration in complex disease primary tissues. Trends Genet. 2023;39(1):46‐58. - PubMed
-
- Nie C, Li Y, Li R, et al. Distinct biological ages of organs and systems identified from a multi‐omics study. Cell Rep. 2022;38(10):110459. - PubMed
-
- Joshi A, Rienks M, Theofilatos K, Mayr M. Systems biology in cardiovascular disease: a multiomics approach. Nat Rev Cardiol. 2021;18(5):313‐330. - PubMed
Publication types
LinkOut - more resources
Full Text Sources